Maybe check and revive this PR
Integration with uWebSockets could be very interesting.
would be nice to have a benchmark:
[uWebSockets]
A good point about uWebSockets is the fact the sockjs was updated 4y ago vs 3 weeks ago from uWebSockets.
@ignl do you mind to do a small POC?
[Proto]
One advantage of using Protobuf in Meteor is that we’re full-stack, so developers don’t need to worry about Protobuf-specific knowledge. They only need to work with JS/TS types, and we can handle everything behind the scenes.
I was looking with chatgpt into this some time ago and conclusion was that it’s a big undertaking so stopped right there. uWebsockets are very very very performant, but it’s complete reimplementation with different api, so it’s not really compatible with nodejs ws or socksjs and would require deep refactoring in meteor code. But I don’t really know much about meteor.js internals, maybe it’s not as bad as chatgpt says. I just put this idea out as potentially interesting.
There were also some discussions about maybe moving to bun (and bun I think uses uWebsockets underneath) so if refactor is big anyway maybe that could be a move. Of course this is just brainstorming for now.
Protobuf needs to be de-serialized, I am not sure it would be more performant than simple json. I would really research and test this before investing into implementation. Maybe there are some new browser api’s that could do deserialization natively idk, but if done in js it probably won’t give any big wins and introduce complexity.
For those who want to work on it, understand DDP pkg could be a good point of start, here and here you can find a guide
@ignl but what do you think to do an benchmark comparing ws, sockjs and uws and talk about the diffenreces between them, it will be a good content for the dev community and for who want to do a poc like this. It will a required knowledge for who want to work on it
I’ve been working on the benchmarking side of things and built a framework on top of the existing meteor/performance repo that could help with some of the questions raised here (measuring the impact of change streams, etc.).
Live dashboard: https://meteor-benchmark-dashboard.sandbox.galaxycloud.app/
Fork: GitHub - dupontbertrand/performance at feature/benchmark-framework · GitHub
A bench.js CLI that runs Artillery+Playwright scenarios against any Meteor checkout, collects CPU/RAM/GC metrics, compares two branches and detects regressions
GC tracking via Node.js perf_hooks (zero overhead when disabled)
A Blaze dashboard on Galaxy to visualize runs, compare branches, and track trends over time
GitHub Actions workflows for automated PR and nightly benchmarks
There’s already data in the dashboard for release-3.2 through release-3.5 and devel. For example, devel vs release-3.5 shows nearly identical performance on the light scenario, with devel having slightly better GC behavior (−31% max pause, −34% major GC time)
This is still very much a draft/experimental setup — benchmarks are running on shared GitHub Actions runners (no dedicated VM), so the numbers have some variance. But the framework itself is functional end-to-end: run, compare, push to dashboard, CI automation. Happy to iterate on it if the team finds it useful ![]()
![]()
Give this man a baguette!! ![]()
![]()
![]()
This was exactly the longer-term vision I expected for meteor/performance: making it more dynamic and allowing easy checks between branches, different app examples and setups, multiple metrics, and so on.
Still, the app there is really basic and does not cover many real-world scenario behaviors (I will continue and intent here - I will try with Claude, I invoke you! ![]() ). But we can scale the performance app overtime, and with that the benchmark suite UI will be a good asset to compare changes and ensure we do not go backwards.
). But we can scale the performance app overtime, and with that the benchmark suite UI will be a good asset to compare changes and ensure we do not go backwards.
This dashboard opens also the possiblity to test the bundler scenario with meteor profile and check over versions we don’t go backwards in those terms. ![]()
I completely support the direction of your changes.
benchmarks are running on shared GitHub Actions runners (no dedicated VM), so the numbers have some variance.
Don’t worry we can improve that later with dedicated machines to get more stability on numbers, the idea is the direction to go.
Nice! This is something I was trying to do with OpenTelemetry, but you’re following a better path than I was. I really loved the live dashboard; I can definitely see it in our release pipeline one day.
I have a few questions:
Such a great tool. Squash the “meteor doesn’t scale” rhetoric.
Quick update on the benchmark work: the benchmark framework is now merged into dupontbertrand/performance on main , and the dashboard is live here: https://meteor-benchmark-dashboard.sandbox.galaxycloud.app ![]()
It currently covers:
I also added CI workflows for nightly runs, branch vs baseline comparisons, and transport comparisons like SockJS vs UWS ![]()
The dashboard has evolved quite a bit too. It now has a proper Release Health view, compare pages, trends, run detail pages, scenario detail pages, and more context around what each metric means.
Current tags/data include:
release-3.2release-3.3release-3.4release-3.5develrelease-3.5-sockjsrelease-3.5-uws@italojs To answer your questions directly:
1. Is the server running in the same environment as Artillery?
Yes, for now the Meteor app and the load generator run on the same machine, either on the same GitHub Actions runner in CI or on the same laptop locally.
That works well enough for relative comparisons on the same setup , but not for production-like absolute numbers, since the load generator also competes with the app for CPU and RAM. So for the 3.4 → 3.5 CPU differences some users reported, a split setup would definitely be cleaner: Meteor on one machine, load generation on another.
2. Do I have plans to test only the backend?
Yes, and that part is already in place ![]()
I added backend-only scenarios:
ddp-reactive-light / ddp-non-reactive-lightfanout-light / fanout-heavyp50 , p95 , p99 , max )I also added CLI-only benchmarks for:
cold-startbundle-sizeSo the current setup now covers browser/full-stack, backend-only, reactive fanout, and startup/build benchmarks.
The main next step now is improving signal quality:
So there’s still a lot to refine, but it’s starting to feel like something genuinely useful rather than just a pile of benchmark scripts ![]()
This is so cool. Fantastic job on this!
Edit: Something that may be of interest for developers who have not migrated to 3.x yet is a baseline comparison of 2.16?
Are all these tests using oplog tailing? Should 3.5 also have change streams support to measure 3.4 oplog tailing vs 3.5 change streams?
https://meteor-benchmark-dashboard.sandbox.galaxycloud.app/scenario/reactive-light
Measuring 2.x vs 3.x is turning out to be a bit more complicated than expected, but I’ll get there ![]()
And regarding oplog vs. change streams, yes, I can run both tests just like I did for SockJS vs. uWS ![]()
But until we have a dedicated machine, the metrics are completely skewed ![]()
IMO we should focus in make benchmark toolkit stable for 3.x first, as I can see still have so much to do to mensure 3.x, metrics, scenarios, pkgs…
I’m in favor of totally dropping 2.x. It’s a piece of history now. So don’t waste your time focusing on it.
Not trying to cast stones but sharing this for the broader community but the official stance now is no 2.x releases. Not even backports, fixes or any improvements to ease migrations. So makes no sense @dupontbertrand for you to try to get readings on performance. Drop 2.x.
Fiooou, quite a Saturday. Here’s what happened today on the benchmark front.
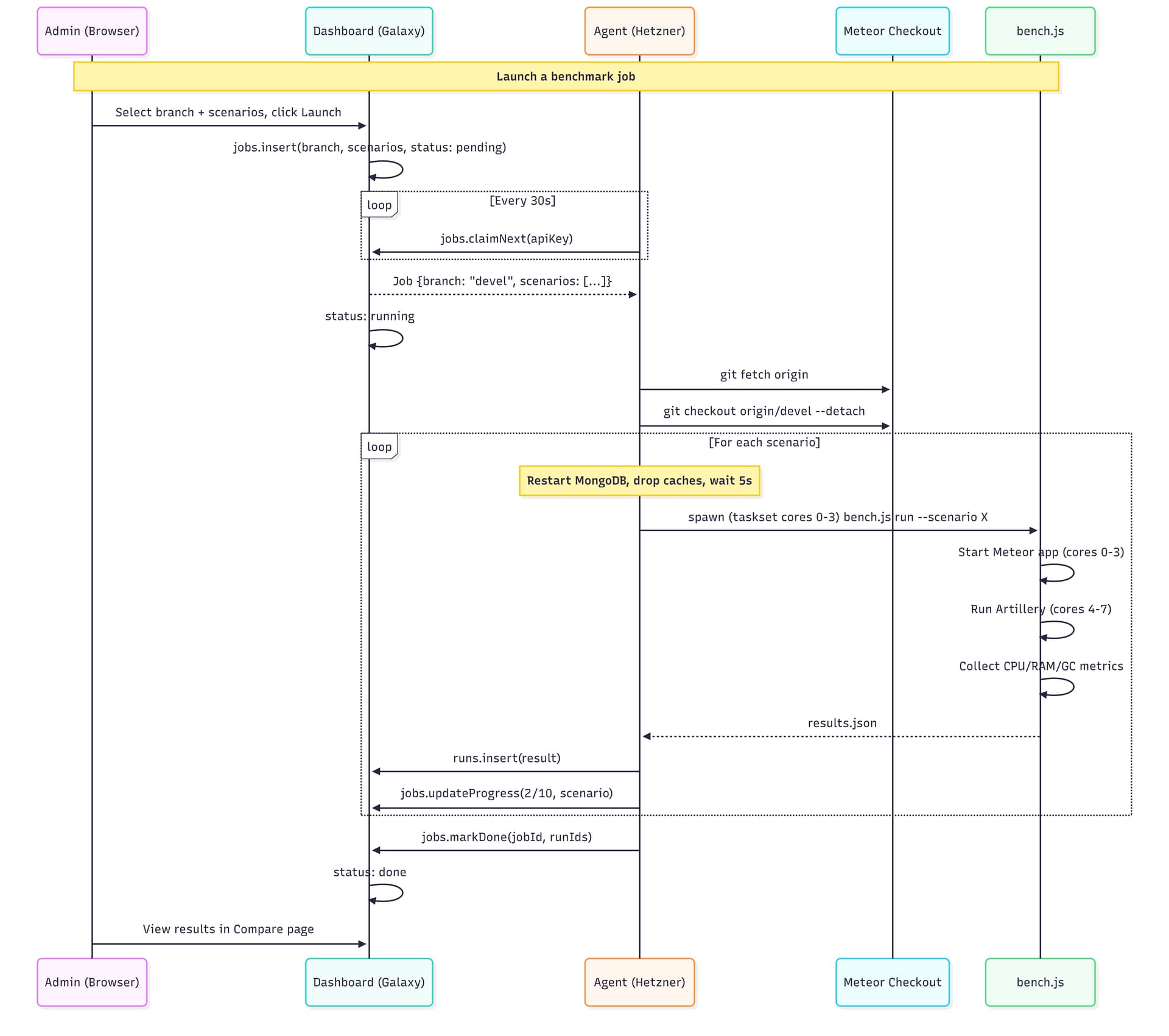
We now have a Hetzner CPX42 (8 vCPU AMD EPYC, 16 GB RAM, Nuremberg) running nothing but benchmarks. No desktop, no GUI, no cron jobs, no shared runners. Just Meteor, MongoDB, and Artillery.
MongoDB 7.0 and Node 22 — same versions as Meteor’s dev bundle.
Getting reliable numbers took a few iterations. Here’s what we ended up with:
taskset. They don’t fight for CPU anymore.echo 3 > /proc/sys/vm/drop_cachesThis made a huge difference. Our early runs had GC max pauses of 5+ seconds that turned out to be just noise from lack of isolation. With the setup above, the same metric dropped to ~40ms. Lesson learned: benchmark methodology matters more than the numbers themselves.
We split things into two private repos:
The old performance repo is archived.
The agent polls every 30s, picks up pending jobs, runs them sequentially, and pushes results back. There’s an admin page where you can select a branch from a dropdown (synced from the Meteor repo — all 1,900+ branches), pick scenarios, and hit launch.
All 10 scenarios, 240 concurrent Chromium sessions on the heavy ones. Same machine, same day, full isolation between scenarios.
The headline: release-3.5 has dramatically better GC.
| Scenario | Metric | devel | release-3.5 | Delta |
|---|---|---|---|---|
| reactive-crud (240 browsers) | GC total pause | 4,813 ms | 756 ms | -84% |
| reactive-crud | GC count | 970 | 299 | -69% |
| reactive-crud | Wall clock | 927s | 687s | -26% |
| non-reactive-crud (240 browsers) | GC total pause | 26,929 ms | 5,914 ms | -78% |
| non-reactive-crud | Wall clock | 373s | 267s | -28% |
| ddp-reactive-light (150 DDP) | GC count | 653 | 107 | -84% |
| ddp-reactive-light | RAM avg | 371 MB | 489 MB | +32% |
release-3.5 does 3-5x fewer garbage collections and spends 67-84% less time paused in GC. The trade-off is ~30% more RAM usage — it keeps objects alive longer instead of constantly allocating and collecting. For users, this means fewer micro-freezes and more consistent response times.
The exception — cold start:
| Scenario | devel | release-3.5 |
|---|---|---|
| cold-start | 16s | 36s |
| server bundle | 91 MB | 207 MB |
devel cold-starts in half the time. The server bundle is also half the size. Worth investigating what changed there.
The dashboard is public and read-only: https://meteor-benchmark-dashboard.sandbox.galaxycloud.app
Go to Compare, select devel vs release-3.5, and browse all 10 scenarios. The About page has the full methodology if you’re curious about how things are measured.
Would love feedback on what other comparisons would be useful!