this fetch all my data (30000 entries…, and than jump to a random entry. which is highly unefficient.
My data is structured like this:
[{id: “randomstringbits”, text: “entry text”}, […]}
I wish i would set find({id: randomint}) where randomint is < than mycollection.find({]).count() but the id is non predictable and non ordered. and also fetching all my data just to know its size is highly unefficient.
Is there a way to fetch one entry at a time using a minimongo operator within the first argument? Or any other way?
Use a auto increment value on a key so you have numbers going from 1 to 30000 or whatever your count limit is
Then just pick a random value 1 - Max and select by that key on a findOne, add a index to the key and cache the result. CPU will 100% idle.
let max = 30000; //Could hold a hourly count here from db and cache it if its a growing dataset
let randomIndex = Math.floor(Math.random() * max);
let result = myCollection.findOne({index: randomIndex});
As a rule of thumb for good design - Never do random or any functions at database, use your scripting language for it and at most only ever do a sort on an indexed key, but try to avoid if possible and leverage the power of your scripting language. Picking a random number in node is effortless, doing so at database is not.
{index: randomnumber} is not a key that exists in my data.
My index (_id) is a random hex string.
Your answer is telling to rewrite my data, which is what i want to avoid for now.
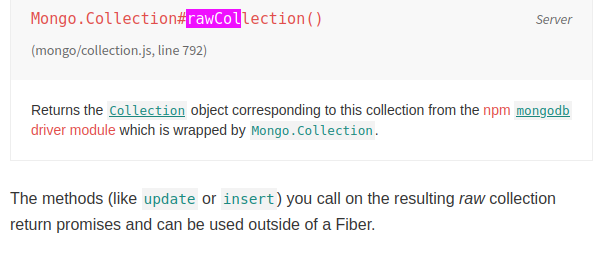
As I said, there is not aggregate Method in Collections Documentation.
You are inviting me to use $sample which only work in aggregate method, which doesn’t exist.
As you can you see in the documentation caption, Aggregate is not a Meteor function.