I want to ask the Meteor community about how you guys handle your own (production) deployments and if/how you achieve zero downtime when deploying a new version.
Our own setup looks like this:
2 identical docker containers running our app, which sit behind a
traefik proxy (in its own docker container), handling the routing and the load balancing for these 2 containers
When we deploy a new version, we simply deploy container #1 first, wait ~10 seconds and then update container #2. The problem is, that due to sticky sessions, the traefik router/loadbalancer needs quite some time to really realize, that e.g. container #1 is now down and re-routes to #2.
Also, directly after starting up any container, Meteor needs up to ~30 seconds to be “really done with startup” and the CPU load goes down from 100% to a more acceptable level.
My question is: Do you guys have any input on what we could improve in this process? I would like to achieve a real zero downtime deployment, where at some point the containers just “switch over” from the old to the new version and all the user sees is a short page reload. - right now, if the user is online while we are deploying a new version, he sees a loading spinner of up to 30-40 seconds, which really is not nice!
I use AWS EC2 instances directly, with an ELB in front of them.
The deployment script de-registers one target, deploys, re-registers it, waits for it to be healthy, then moves onto the next host. This works great so long as you don’t have breaking schema changes - since you could run a migration on the first server that comes up, then after that runs your old server writes more incompatible data. There are ways around this of course (e.g., writing idempotent migrations and backwards-compatible schema changes)
Most of my projects have relatively few servers (the most is 8) so this works well. Any more than about 10 and I’d implement batches (take down 3 at a time for example).
Honestly, though - I’m looking at moving everything to k8s, where this gets handled for you.
In terms of meteor startup - the server doesn’t respond to requests at all until after all the startup hooks have fired - so if you have health checks, they also won’t respond until that point. So if you follow any deployment procedure that rolls based on health, you’re good.
I’m running Fargate on AWS, similar to @znewsham I just deploy a new version in Sourcetree (which I prefer over git command line). AWS takes care of everything else, it launches the new build, at that moment the new and old one are running in parallel. When the new one is running fine, all new connections go to it and AWS will start to move the user from the old server(s) to the new one (we do have rules in place to scale-up and down automatically). When there are no users on the old server, it’s taken down. This usually takes only a couple of minutes.
We also handled this with a notification at the bottom telling users that a new version is available (using Meteor’s feature to detect new builds). They can continue using the app (e.g., finish what they are doing) or choose to click the reload link.
Most of the time, we just chose a few minutes of a maintenance page and deployment during the wee hours of the morning. Good thing it was rare.
For zero downtime you can simply update the files, and then restart the app - it’s just the node main.js line.
I do this inside of a screen so it’s dettached from the shell and running as a process that i can monitor.
So in the most simplest way you just copy the build tarball to the server, decompress it and then start the process again because the app is running in memory, so killing and restarting is how you will do it and retain all session and never log anyone out. It will mean hitting ctrl+c to kill the process, then just press up and enter to start the node main.js again. If you use React for the frontend no one will notice.
Thanks for your replies everyone!
I just did some tests of the “startup time” of meteor.
On a pretty potent test server without any traffic, from running docker run of an already downloaded docker image, until the user can actually use the app in the browser, it took 11 seconds.
Is there any way to still improve this?
If I understand your argument correctly, you basically just accept that the client loses its DDP connection during deployment? @rjdavid how exactly do you check for “new version” and update your UI as you explained?
Packages are using this to allow the “migration” of the session to the new version.
We can hook to this functionality to stop the reloading of the app from loading the new version. The simplest way to stop the reload is by calling this simple function.
Reload._onMigrate(() => {
return [false];
});
You can read the rest of the functionality from the package
We have multiple servers behind a load balancer. When deploying, server1 is set to maintenance mode at the load balancer level, so that it doesn’t receive any requests. The currently connected clients pick this up and restart the web-socket connection in the background, ending up connecting to a different server running the same old version of the app. It’s unnoticeable for the user.
Then, we deploy the new version to server1 in maintenance mode. After a successful & healthy deployment, load balancer sets the server1 to drain-mode, meaning it will accept new connections only if server1 is specifically requested via the sticky session cookie. Run any required tests against the new production deployment, and if everything seems fine, set server1 status to ready in load balancer, meaning it is now running as usual.
Repeat for server2, server3, server4 etc…
We’ve also disabled automatic reloading when client detects new code, instead an UI prompt is shown to reload the page.
We’re currently rolling our own deployment solution in Fargate and AWS ECS.
How exactly are you/AWS doing the "move the user from the old servers(s) to the new one(s)? When we launch new containers for a new version of our app, our existing users don’t seem to do anything. The container they were gets shut down and nothing happens. Is this a setting in ECS or the load balancer? And are you maintaining user state? Do users stay logged in, etc.?
Again curious, how/where are you doing all of this functionality? This sounds like you’re running on your own VMs and not containers right?
You have to ask AWS, we didn’t set anything specific here. It takes about 4-5 minutes to be 100% on the safe side, after that the users are all on the new instance using the latest deployed version.
Nothing is required from our side. Keep in mind that we do have separate instances for Frontend and Backend. Frontend is actually an Electron desktop app running on the users PC/Mac/Linux machine, our Frontend instance is only responsible for the sign-up process and handles the login/logout/maintenance modes. The Electron app pings the Backend instance through the ELB, so redirecting it to the new instance after deployment is 100% automatic.
@evolross in EBS (Beanstalk) these are basic settings. I am not sure what ECS has over EBS for NODE but I feel EBS has all I need.
"How exactly are you/AWS doing the “move the user from the old servers(s) to the new one(s)”
This is done via the ALB (application load balancer).
If you have 1 EC2 running and the maximum number of EC2s for your autoscaling is set to 1, that machine is going to be down for 3-5 minutes.
If you have 1 EC2 running and the maximum set to 2 or more, you can select how you want to deploy the new code and separately, how you want to deploy the new configuration. With Meteor UP you can push configurations separately from pushing new code (bundle). You can select to deploy all at once (down time) or one by one. The necessary numbers of EC2 will start, deploy and shut down afterwards.
ALB manages connections and will take any new connection and direct it to the next available target group (this is how EC2s are organized). There is a condition there: DO NOT set stickiness ON because in this case a client will try to connect to the same server all the time. You want to let clients free to connect to anything they can :).
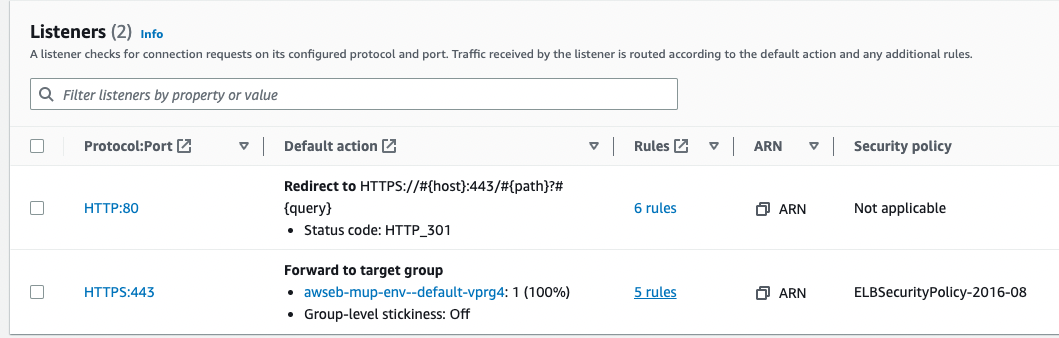
“Forward to target group” in this image is the ALB default target group (of EC2 machines). The 5 rules, are just ALB rules looking into what subdomain request comes in and directs to the respective target group for that Meteor subdomain. (e.g. chat.xxxx.com, app.xxx.com, products.xxx.com)
Number or EC2 : Min 1 max 3
%CPU for autoscaling up: 60%.
2 EC2 running at 50% CPU load each.
When you deploy new code or configuration, you can have a 3rd EC2 starting, deploying new code and then shifting connections from the 2nd EC2 (draining) to the new one and so on.
A little hard to put it in words but if you want I could show you around in a Skype or Zoom or anything.
Hm. Just curious about your setup now. So the only thing containerized in ECS is a back-end API for your app? What/where does your Electron app connect to handle login state part? Another Meteor server hosted elsewhere? If it’s just your back-end being redeployed and it doesn’t handle user-state, then yes that would be a significantly different use-case than us running our whole Meteor app (client and server) in ECS.
We went with ECS using Fargate for two reasons:
It’s more Docker/container oriented and we are designing a CI/CD process in addition to rolling our own deployment. All of this revolves around docker and containers.
We have some custom TLS requirements, similar to what Galaxy offers, where we need to dynamically update custom domains for clients and their TLS certs on the fly. The EBS load balancer seemed like a closed system that doesn’t allow this. Where in ECS we can put Caddy server (a reverse proxy that supports dynamic TLS) in front of the ALB. I’m still curious how Galaxy implements its dynamic TLS.
That was our take when choosing ECS. Now that we’re more knowledgable on all things AWS, could we do something similar with EBS? Maybe. We’re still going to review EBS once we get ECS working correctly. As it supports containers too (using ECS and Fargate under the hood). We also weren’t 100% sure we could put a Caddy reverse-proxy in front of EBS’s ELB in the same VPC, etc. All of this is very customizable in ECS stack templates.
This is curious and goes against everything I’ve read about deploying Meteor. As without sticky sessions, you lose application data state upon reconnecting. This may not be a big deal. But it would cause data reloading in the event of not reconnecting to the same server/container. This seems a bit of a hack to force your client to connect to the new server, no?
There’s an Electron app installed on the users desktop. There’s a frontend Meteor app on AWS and another Meteor app on AWS which is the Backend only. There are also Lambda calls for longer running functions and those CPU intensive ones. So it’s two (!) containers running which can be updated independently (through a code commit to the repo), triggered by AWS CodePipeline.
From a code perspective, the Electron/Frontend is all in one repo. Frontend and Backend are connected to each other. For the Backend to Frontend communication (to give feedback about progress of tasks etc.) I use the Streamy package.
I‘m on scalingo. It’s a no brainer here, just push to deploy and they do the rest (build, push and start new container, change balancers, shutdown old containers etc)
I’m also very intrigued by this, Is there any way to only disable group stickiness for EBS when deploying/scaling up and then reenabling it automatically?
I can see the benefit of splitting the users after scaling up or deploying a new version to fullfill all the instances available, but in general I don’t see the point of disabling it completely (on every page refresh or visit you could potentially end in another server and loose all the connection values)
I have seen this manual balancing options, but would be great if that was handled automatically somehow