I’m a little late to this conversation, but as a tip, your problem is probably a method that does does something of the form of:
Collection1.find().forEach(function(doc1) {
Collections2.update({joinedField:doc1.field}, ...);
});
or
Collection1.find().forEach(function(doc1) {
Collections1.update({_id: {$in: doc1.arrayField} }, ...);
});
or, most likely from the numbers you’re seeing in your oplog:
Collection1.find().forEach(function(doc1) {
for (var i = 0; i < doc1.fieldB; i++) {
Collections2.update({joinedField:doc1.field}, ...);
}
});
Think about how you can restructure these to use an update with {multi:true}. Start by investigating your slowest methods in Kadira. If you can’t do a multi-update, make sure when you do these joins, you don’t accidentally replace the document; or, like in the third example, quadratically increase the number of documents you modify.
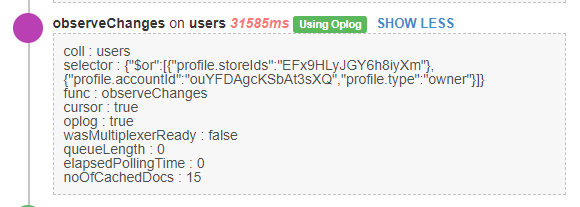
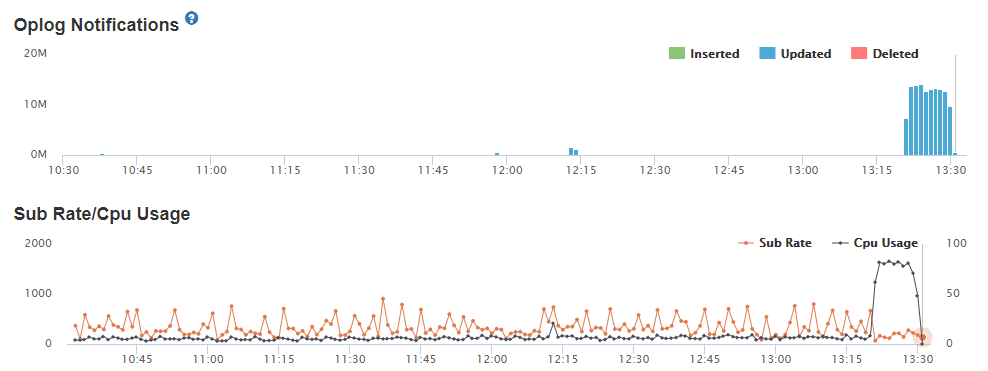
This is based on the reading of your oplog notifications, which generate a huge number of updates. Naturally, a publish and subscribe, as long as it’s not radically buggy, won’t update your database for you.
My bet is, actually, in your client code, you have a Collection.update that gets called, eventually, by rendering code, and coincidentally it is doing an extremely slow and noisy join across hundreds of concurrent users for you.