The stress tests above use client side updates and all worked as planned. Even allow / deny rules. I am using latest meteor from repo directly. Maybe a package we installed did something? I guess it’s time to move everything to methods, even though I disagree with this recommendation.
@ramez
Something is wrong then, 2 people complained about client-side inserts/updates not working. The reason why this is not recommended is described here: https://www.discovermeteor.com/blog/meteor-methods-client-side-operations/
MDG also agrees with this.
I can’t explain why it works for us but not for these two people. I do know that redis was used as we would start each test by checking redis-cli monitor to make sure traffic was flowing. And if we shut down redis Meteor would crash.
I understand that many recommend against client-side updates (and can see why), but it worked for us and in our case simplified things. Then again, we learnt not to go against recommendations of the platform maker, so will likely make the changes to our code base.
EDIT: Regardless of why it works with us and not others, I recommend we stick with @maxnowack’s package to be safe.
1 Like
I’m searching a new name for the package. allowdeny-redisoplog describes where the package came from, but the name doesn’t have anything to do with what the package do at the end.
I was thinking about redisoplog-clientsidemutations but it’s a bit too long 
That’s how it looks in a very simple meteor app with redis oplog, after a client side insert:
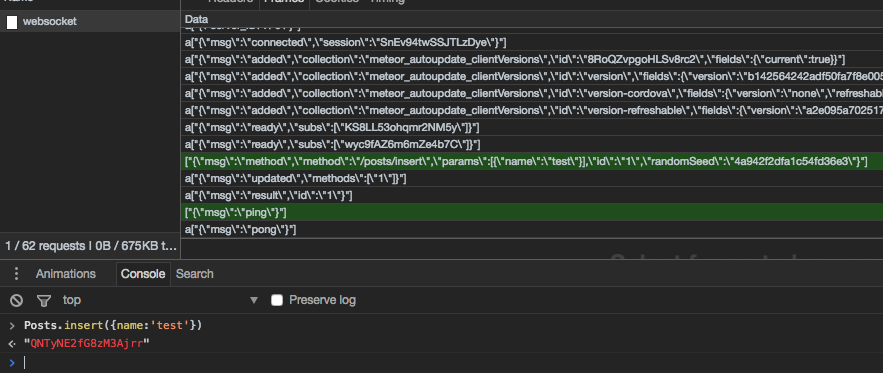
The method was executed successfully (and the post was inserted in mongo), but the new posts won’t be synced to the client.
Edit
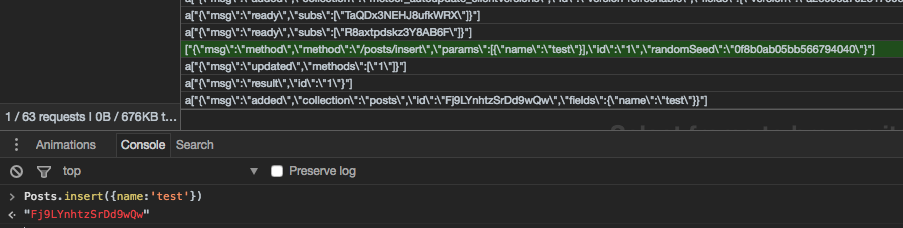
after adding my package:
normal behavior without redis oplog:
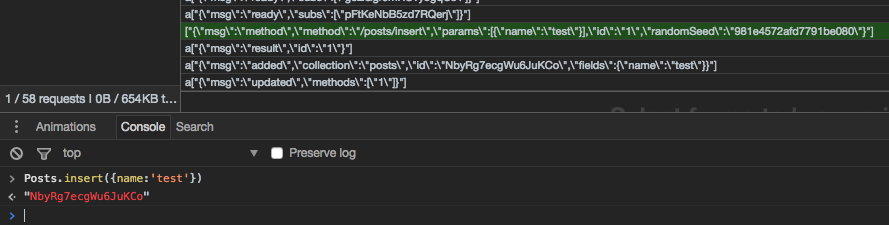
@diaconutheodor while writing this, I’m seeing the root of an issue with latency compensation I’ve noticed before:
with redis oplog, the posts was added after the method result was sent. In the normal behavior, the post will be added before the result was sent. I’ll file an issue at github for that case.
That may explain it - only the server reacts to client side mutations in our case
Thanks for the steady updates. We tested it out in our dev environment and it seemed to be working well, minus client-side updates. Our team posted a couple of issues.
The benchmarks posted above are interesting. We have between 5k and 10k concurrent users at any given time, so I’d be curious to try it in production (LOL). When it gets production ready, we’ll definitely want to see if we can do so.
4 Likes
Good find. We’ll continue the discussion on this on the github issue.
Btw, absolutely no idea for a name for the allowdeny package.
Guys I can confirm Client-Side works out-of-the-box on my end. I tried it and it just works with Redis-Oplog. For @ramez it also works.
But we have two other people that seem to encounter issues like: @maxnowack and some people from classcraft team @shawnyoung
Very weird, others should try this. My meteor version is : 1.4.2.3
This is what I got when doing an insert, with redis-oplog activated:
["{\"msg\":\"method\",\"method\":\"/users/insert\",\"params\":[{\"emails\":[{\"address\":\"x1@x3.com\",\"verified\":true}],\"createdAt\":{\"$date\":1479971764848},\"services\":{},\"_id\":\"dFQYSnPpK48pMzFHE\"}],\"id\":\"1\"}"] 226
09:16:04.856
a["{\"msg\":\"result\",\"id\":\"1\"}"] 38
09:16:04.868
a["{\"msg\":\"added\",\"collection\":\"users\",\"id\":\"dFQYSnPpK48pMzFHE\",\"fields\":{\"emails\":[{\"address\":\"x1@x3.com\",\"verified\":true}]}}"] 150
09:16:04.869
a["{\"msg\":\"updated\",\"methods\":[\"1\"]}"]
See how this whole thread started, I was thinking the same at first, that there may be some other underlying issues, but there aren’t really. It just works
Well, I do think you’d need to add some nuances about the performance vs correctness differences. BY using the redis oplog, you essentially end up with a dual write system, which can’t guarantee correctness. In the sense that the messages in Redis might be out of order from those in Mongo, so there’s even not eventual concistency. Especially if you have a high load and multiple Meteor servers. Next to that you may also end up with duplicate ddp messages because there’s no Mergebox. Meteor has a high focus on correctness/consistency. Not seldom this comes to the cost of performance. That’s not to say people shouldn’t use this plugin. Performance may be more important to them. But I think it should be made clear this doesn’t give all the same guarantees so people can make an informed choice.
BY using the redis oplog, you essentially end up with a dual write system
Yes. That’s how large scale-reactive applications work, they use a database to store their data, and another system to communicate the changes to all their nodes. They don’t rely to anything like a database’s oplog.
In the sense that the messages in Redis might be out of order from those in Mongo, so there’s even not eventual concistency.
It’s clear to me you don’t understand how this works. You mentioned this problem in the beginning of this thread, and it was solved since 1.0.4 I believe. By using Meteor._SynchronouosQueue Thank you for spotting tht out.
Next to that you may also end up with duplicate ddp messages because there’s no Mergebox.
Mergebox is at DDPServer level. So… we kinda use that 
But I think it should be made clear this doesn’t give all the same guarantees so people can make an informed choice.
By the time this becomes production-ready, it will have equal stability and consistency as meteor oplog. Right now we have just solved latency compensation and optimistic UI, and we will continue to test this in much depth.
So please, if you make claims like: “it’s not consistent”, “it doesn’t use mergebox”, ask first, don’t make claims
Update:
1.0.12 is out. We now have full support for latency-compensation and optimistic-ui and client-side mutations. + Other bugs with positional operator updates have been solved.
We have layed a new stepping stone in RedisOplog’s evolution.
Kudos to @maxnowack who bared with me and helped this lib achieve the client-side mutations, he tested it in his awesome TeamGrid app and says it works perfectly. And again thanks @ramez for taking your time to prove that RedisOplog no longer results into CPU spikes, and improves performance even if you only use _id based subscriptions.
Now… what is next:
- Tests, tests, tests, tests. It’s all I can say.
- Implement the “Amnesia” processing strategy, which will work great with a chat, without bloating server’s memory. This would mean that we no longer store the state server-side Need to think of what’s the best way to implement it. (Make use of: https://github.com/peerlibrary/meteor-control-mergebox)
- Centralizing query watchers is a hard problem we will post-pone this for now, if anyone gets an idea, be sure to share it.
6 Likes
Not sure if this is a right place to report an issue, but this doesn’t work for me…
I’m connected to redis (if I change a password in init I get an error),
I see logs:
I20161125-12:10:56.979(1)? [Main] New incomming subscription for publication: interventions
I20161125-12:10:55.063(1)? [RedisSubscriptionManager] Subscribing to channel: interventions
I20161125-12:10:55.056(1)? [PublicationFactory] Created new subscribers for redis for “interventions” :: {"$and":[{“orgid”:“sdfsafsdfasdfas”},{“siteIds”:{"$in":[“wea4234234243”]}},{“Year”:{"$in":[2017]}}]}{“transform”:null}
this is the publication function:
Meteor.publish(“interventions”, function(opts) {
return Interventions.find({ $and: _entityQuery(this.userId, opts.year, opts.siteId) });
});
When I update from the client side with Interventions.update({_id: “”}, {$set: {}}) I get “1” in console, the document is updated serverside and in mongo, but the local document stays not updated, same for the second browser that also subscribes to the same publication.
Also, if I update the collection using Meteor.shell, the same happens, server and mongo has the update, but clients not.
Any ideas?
I’m using the 1.0.12 version.
We have a built in house load-test solution that allows us to push galaxy containers to hundreds of sessions using real browsers (chrome). We are very excited to see how this affects performance, I’m curious to hear if you have any ideas what could be causing this kind of behavior.
Thanks a lot and great work on this and other packages!
1 Like
@lgandecki pls post an issue to github, so we do bug maintaince there and make sure to show us how “_entityQuery(this.userId, opts.year, opts.siteId)” looks exactly, so we can write a test-case to break it. Also make sure to give us exact use-case, what exactly do you set, what fields are in your publication, you can change the name of them if you want privacy, but keep the structure.
If you will test-load it, I am super-curious to see how it behaves.
@diaconutheodor Just tested v1.0.12 and can confirm the problem I reported with positional operator updates is fixed in my app.
I’ll carry on testing and keep you informed.
Appreciate your continued hard work on this and well done to the other community members for their contributions to testing/PR’s etc.
1 Like
_entityQuery just returns what you see in this log:
“I20161125-12:10:55.056(1)? [PublicationFactory] Created new subscribers for redis for “interventions” :: {”$and":[{“orgid”:“sdfsafsdfasdfas”},{“siteIds”:{"$in":[“wea4234234243”]}},{“Year”:{"$in":[2017]}}]}{“transform”:null}
"
Maybe it doesn’t work with $and?
But, sure, I will create a github issue.
Yes, sorry missed that, was in a rush. Let’s continue on Github so we don’t polute here. Thank you!
Update:
Added a test-case for $and search, works as expected: https://github.com/cult-of-coders/redis-oplog/commit/a512fa0a8227b7029c10ba0a41043dcb27dfc380
Not necessarily. Here’s a good read on that: Bottled Water: Real-time integration of PostgreSQL and Kafka — Martin Kleppmann’s blog
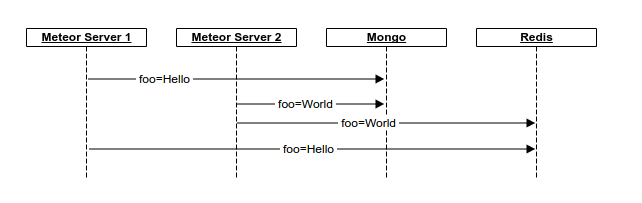
No, this is a different problem. It’s about race conditions between multiple instances. E.g. this situation:
@seba
Yet again, you come with very valuable insight
Ok, their example was a bit different, they had to have consistency for the cache and search. So this was a must, and race-conditions in their case would have had relatively long-term implications.
Now, the same thing can happen in our system as well. However this can be very easily solved, but with a small price to pay:
We push to redis the changed fields, and the query watcher would have to fetch them fields from the db, freshly. I don’t think this would have such a big impact on performance… but it will give users that missing consistency.
Currently the fetch is done right after the update/insert, and the doc is pushed to redis, so if we had let’s say 5 instances listening, they would not have to query the db 5 times.
My idea would be to let people choose, there may be some critical data, like a stock exchange market, where you don’t really want race conditions, so they could do something like:
return X.find({}, {raceConditionProtect: true});
Good stuff, something to think about.
I like the idea of being able to choose per query or publication.