I love the concept of your pub-sub-lite package!
3 Likes
very good advises by @filipenevola and @copleykj
I would also add:
- Analyze your db queries: create appropriate indexes, use projections, try to use projections to execute covered queries, read this article https://docs.mongodb.com/manual/core/query-optimization/#covered-query
- Use load testing tools with APM to understand why it’s unresponsive
APM tools (on local):
https://github.com/Meteor-Community-Packages/meteor-elastic-apm
monti APM: https://montiapm.com/
Load testing:
https://github.com/kschingiz/artillery-engine-meteor
There was also one load testing tool, but I cannot find it - I have also seen cases where frontend was doing lots of re-subscribes/method calls on each data change, use Meteor dev tools: https://chrome.google.com/webstore/detail/meteor-devtools/ippapidnnboiophakmmhkdlchoccbgje?hl=en
to see why and where you are refetching data - There are also cases when oplog cannot be used in pub/sub, so meteor uses PollingDriver which is very slow, MontiAPM which is based on Kadira will show that pub/subs
Good luck with optimization, I believe Meteor can handle even more connections than 7000+.
6 Likes
I’ve had performance problems on Galaxy which Galaxy Support never adequately addressed. Switched to NodeChef and problems were solved. BTW, lots of good performance optimization suggestions in this thread (many of which I had tried to no avail). NodeChef isn’t problem-free though either as I’ve experienced outages on my NodeChef hosted apps. However, when they run, they run well.
1 Like
Our load tests showed about ~300 concurrent connections per server, before load times skyrocket. Usually minimum size containers are used, so that it is no more than 50% RAM used in ‘idle’ state (in our case it is 512MB RAM containers, but normally 256MB containers are enough for simple application). This is without usage of Redis Oplog (which we want to try soon). This however strangely matches to your 7000 connections per 20 servers (7000 / 20 = 350 connections per server). Now I am interested if this is the maximum physical cap here? Or if larger servers may help?
1 Like
Hi @cormip how are you doing? I believe you are talking about past events (before Tiny acquisition), right? I would be happy to review the issues that you had with Galaxy and offer the trial for you to check Galaxy again.
We have thousands of Meteor apps running on Galaxy, handling thousands of connections without issues.
Please reach me out on filipe@meteor.com or support@meteor.com so I can understand your issues. If they are still happening that is even better so we can improve Galaxy even further ![]()
3 Likes
I have talked with @pasharayan by voice and he was using a different channel to communicate with Galaxy team and then even simple requests, like increase container limits, were not being received, he was not able to remember what was the channel specifically but I assume it was not the current valid ones. We did a test together sending requests using Meteor website and it’s working as expect, from now on I don’t believe he is going to have these issues anymore, it was a problem in the channel used to reach us and not with our support. And to be clear, the best channel is to send an email to support@meteor.com
But, in the same time, our support was replying many messages from Julius (Insidesherpa CTO) but I understand that when things were burning at their company and then maybe Pasha was not aware of that.
I just want to reinforce here that Galaxy is a very important piece of the Meteor ecosystem and we (Tiny) are doing our best to provide the best experience possible. We have received other the last 9 months a lot of great feedback about our support and service.
I know we have things to improve, we always have, but I’m sure we are providing a very good service here. And, if you are a Galaxy as well and you are not happy, please, send me an email filipe@meteor.com
6 Likes
Hi, we don’t have a maximum cap, we have clients running much more than 7000 connections. That is our fault that we don’t have a scaling guide and also study cases, we are working on this.
If you can handle 300 connections with 512MB without using redis-oplog be sure that you will be able to handle much more with redis-oplog.
Redis-oplog is the best way to use Subscriptions and achieve horizontal linear scale with Meteor as it helps you to spread the load of receiving/processing your real-time update messages equally or at least better. MongoDB oplog will require every container to read all the messages and that is why @diaconutheodor and his team came up with this great package, to workaround this issue and allow the messages to be sent to the necessary containers only.
You can improve this even further using redis namespaces then you can fine tune your messages. With this setup you can scale Meteor subscriptions a lot, I don’t see limits here.
A few important concepts about scaling Meteor apps and Meteor apps in general.
BTW, I’ve being scaling Meteor apps for many years, before I even join Tiny, so I’m writing below as a Meteor user that saw these solutions working in real apps.
1 - Meteor in runtime is just a group of packages running on Node.js, Meteor is not a runtime so Meteor has no limits to scale or at least it does not have any limit different than Node.js
2 - Subscriptions using DDP messages is a feature of Meteor to delivery real-time experiencie using subscriptions with almost no code in a very productive way but you can delivery data in many different ways (Methods, REST, GraphQL, etc), this is your choice in the end. When you choose to use Subscriptions you are going to receive a lot for free and in a very optimized way, think about the network layer, you only send diffs to the client and you didn’t write any code for this to work but of course some process need to calculate this diffs for you, keep the last state in the server, etc.
3 - Meteor subscriptions with MongoDB oplog will not scale horizontally (adding more containers, btw, Galaxy can do this automatically for you using triggers) at the same ratio of connections by container if you increase a lot the quantity of writes or containers, as every container needs to read all the oplog from MongoDB what will cause a side effect on MongoDB performance, because of that Redis oplog exists.
Important: most of the apps will never need to migrate to redis-oplog, because MongoDB oplog will be enough for most apps ![]() The advice here is: only start to use redis-oplog when you need, the replacement process is a breeze (thanks @diaconutheodor). Also, if you only use Subscriptions for a part of your app this is probably never going to be an issue for you. Some apps are doing everything using subscriptions then the chances are higher to need a solution like redis-oplog.
The advice here is: only start to use redis-oplog when you need, the replacement process is a breeze (thanks @diaconutheodor). Also, if you only use Subscriptions for a part of your app this is probably never going to be an issue for you. Some apps are doing everything using subscriptions then the chances are higher to need a solution like redis-oplog.
4 - Redis oplog can bring horizontal scaling for Meteor apps the same ratio of connections per container using how many containers you want as with because it is just going to send the messages to the containers “watching” a specific query. You can fine tune the messages that will be delivered for each container. Important: most of the apps, even if they need redis-oplog they are not going to need fine tuning but if you are using redis-oplog and want to scale even further you should use namespaces.
5 - MongoDB can be the bottleneck in many cases and not Meteor as you will be reading and writing from MongoDB and then if MongoDB starts to run slower this will affect your app.
“Meteor does not scale” is a myth, it is the same as say “Java does not scale” or “Node.js does not scale”, any technology will depend on our implementation more than anything else and Meteor already provide by default a very good solution that will work for almost every app. After that we have amazing packages like redis-oplog, pub-sub-lite to help. Pub-sub-lite is a new package but I’ve already worked in apps that wrote similar solutions, it’s great to see this solution available as a package.
We (as a community) and also I (as Meteor evangelist) need to do a better job promoting Meteor and showing how well it can scale and keeping great features like subscriptions. All other subscriptions technologies if they would do everything that Meteor does I bet that they will performance much less than Meteor.
Disclaimer: nowadays you can use Meteor in many different ways, many different data layers, many different view layers and everything we are discussing here is how to scale Subscriptions with Meteor. If you don’t need or don’t want to have real-time data sync between Mongo and Mini Mongo that is not even something that you need to worry about.
32 Likes
Thank you very much @filipenevola for the very detailed explanation. It is probably the best post on the topic which clearly reassures anyone in doubt. ![]()
3 Likes
Great reply @filipenevola, it’s really great to see the official support! I really like Galaxy and think everyone should use it and share more of their performance findings.
You gave a good piece of info on how the oplog is working, so based on what you said, for many users, they should probably scale in the container size before they scale in the number of containers.
I personally had wondered about scenarios where it might be wise to do this, for anyone who doesn’t know Galaxy yet, it just looks like this:
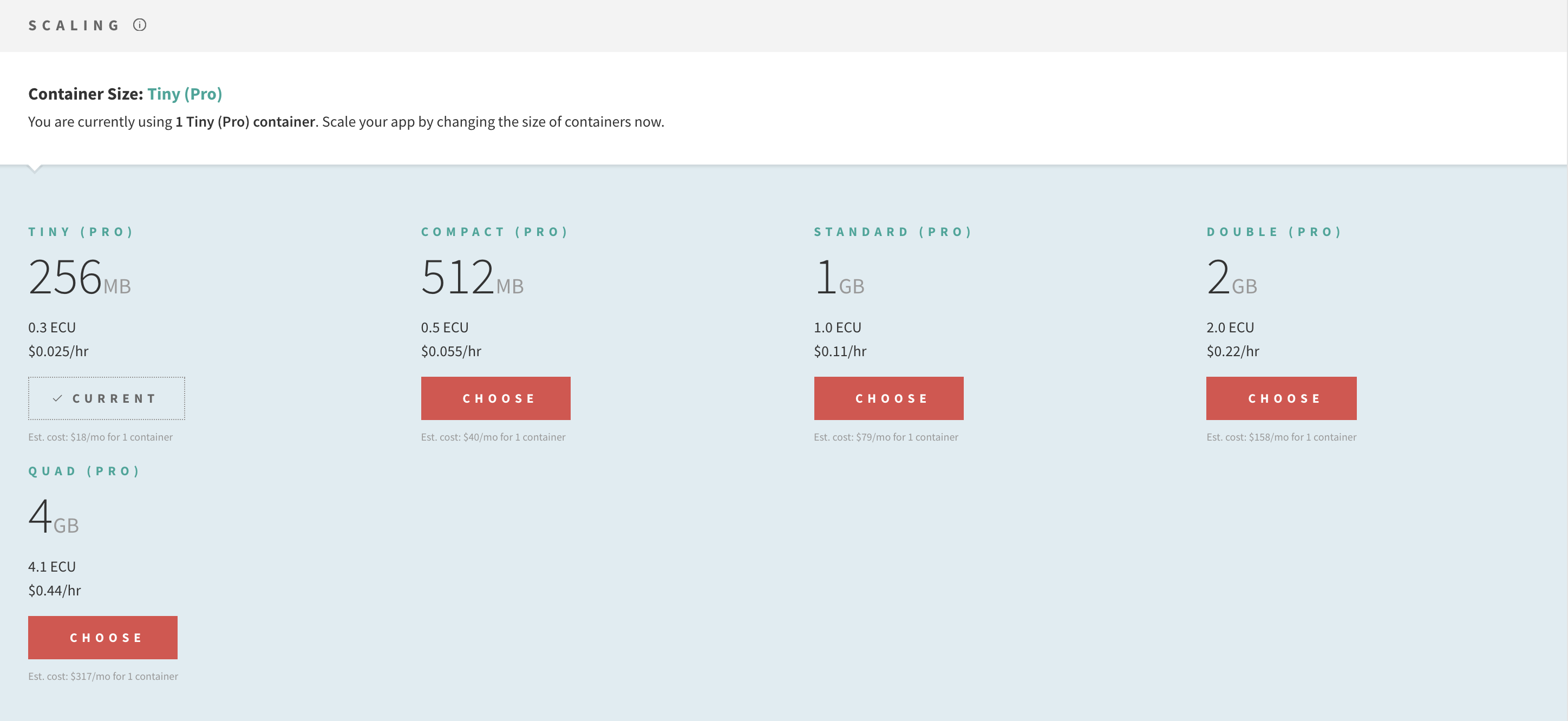
You can just pick the size of container and see how it impacts your apps performance.
Also, a couple of us are doing some mapping of Meteor’s architecture and I was doing some reading on Live Queries. There is some great info in the guide that shows how to optimize Live Queries.
How to Optimize Live Queries:
https://galaxy-guide.meteor.com/apm-optimizing-your-app-for-live-queries.html
Live Query support is one of the major competencies in Meteor. Normally, a new Live Query is created when you return a cursor from a publication. Then it’ll reactively watch the query and send changes to the client.
In order to detect these changes, Live Queries do some amazing work behind the scenes. To do this, they need to spend some CPU cycles. Therefore, Live Queries are a major factor affecting your app’s CPU usage.
However, the count of Live Queries itself does not cause many issues. These are the factors affecting the CPU usage:
- Number of documents fetched by Live Queries
- Number of live changes happening
- Number of oplog notifications Meteor is receiving
I kind of recommend that the whole community that is interested in scaling should read the link above ![]() Sometimes there is more documented about Meteor than we all realize
Sometimes there is more documented about Meteor than we all realize ![]()
4 Likes
Please read this: https://thecodebarbarian.com/slow-trains-in-mongodb-and-nodejs
Then read this: https://medium.com/@kyle_martin/mongodb-in-production-how-connection-pool-size-can-bottleneck-application-scale-439c6e5a8424
Perhaps then try to understand the limits of your MongoDB provider (ex: https://docs.atlas.mongodb.com/reference/atlas-limits/)
If your problem is due to a bottleneck at Node - MongoDB relation, consider to distribute your data over multiple DBs and avoid slow queries jamming your fast queries.
5 Likes
I learned a lot with this topic 
1 Like
Very helpful, thank you, guys!
1 Like
Hey, just to post a follow up here, each Quad container of Insidesherpa was handling around 700 connections and after some optimizations, like using Redis channels (https://github.com/cult-of-coders/redis-oplog/blob/master/docs/finetuning.md#custom-channels), they were able to increase this to 2,500 connections per container (and the container is running very fine with these connections). They have many apps deployed but the main one is running 3 containers instead of 20 at the moment.
They still have many areas where they could improve even more then I don’t think they are even close to their limit of connections in a Quad container but 2,500 connections per quad container IMO is already a pretty good number 
I’m talking with them so we can publish together a more detailed report of what they have done in these last days.
17 Likes
Hi all, want to put a closure from our end as well.
As @filipenevola mentioned before, we are finally on the happy end of things again being able to serve >2.5k connections / container without sweat on Quad CPU. Before this we tried 20 Quad CPU and it didn’t help e.g. method call response is 1s+, subscriptions also 1s+ (can peak to abysmal number like 10s).
I would highlight 2 main issues that made our system not scalable:
- Redis-oplog issue where a document was inserted or updated, but the publication did not detect and push the new document to the clients.
- 1 write to db that publishes to all users happened frequently (as @mullojo mentioned about multi-user update loops)
We are using publish-counts package https://github.com/percolatestudio/publish-counts, that were counting the entire collection and will need to reevaluate when a doc is updated for that collection. It also increases our container memory usage because whenever it is being used, the container will keep the observer. I removed this feature for now and will definitely implement it on a different way. We saw memory usage down from 2.8GB (yes Quad Pro was our minimum container that can serve our system), to ~1.2GB.
As you guys all know, we are still a startup where simple infrastructure is really important for us. MeteorJS has helped us achieved this until this point where we can naively have simple rules like:
- Data transfer should be using meteor publications
- Mutating data / actions should be done by meteor methods
These 2 rules have made our codebase very easy to build and debug because everything is done on the same way.
Now that we (I especially  ) have better understanding of the meteor ‘blackbox’, we are more thoughtful on using meteor publication and methods. Not saying we are not using meteor anymore, but we are going to add more things like caching for data intensive request and offloading CPU intensive operation from meteor methods to different instances.
) have better understanding of the meteor ‘blackbox’, we are more thoughtful on using meteor publication and methods. Not saying we are not using meteor anymore, but we are going to add more things like caching for data intensive request and offloading CPU intensive operation from meteor methods to different instances.
Galaxy Support has been helpful (@filipenevola especially) figuring out our issues. We were initially frustrated because Galaxy does not have a code-level support offering and I think some of my support requests that I submitted through Galaxy website form were not submitted properly.
I was quite surprised by how active the community is on this thread. I hope others can learn from our experience here.
12 Likes
Were you able to fix this? From experience, this is solved by fine tuning the mutations
Thanks for sharing. Learned a lot from this thread
1 Like
This was hugely interesting, thank you!! This begs the simple question, however, as to how to set the poolSize option for Meteor.
The Node.js MongoDB Driver API for MongoClient lists poolSize with a default value of 5.
The Meteor Doc about MONGO_URL refers to the MongoDB docs for the connection options. In this one however there’s only maxPoolSize and minPoolSize yet no poolSize as such. What am I missing here?
Thanks! I’ve just figured it out and add it here for reference, starting with Meteor 1.10.2 Mongo Connection Options can also be set in the Meteor settings. Options can be specified under private.packages.mongo.options. As of now this is presumably the most convenient way to specify options.
The MONGO_URL environment variable has the standard mongo connection string format, which also allows to set connection parameters, so quite possibly this could also work:
export MONGO_URL='mongodb://user:pw@host:27017/database?poolSize=10'
…given that MongoClient in the 3.6 (and prior versions) Node.js MongoDB driver has the option poolSize, but I wasn’t able to verify this yet.
At instantiation, MongoClient receives url and options; the fact that the standard mongo connection string format can also contain options creates an ambiguity which is not addressed in the Node.js API documentation. E.g. if there are options specified in the query part of the url, and the same options are also specified in the parameter options but with different values, which of the two takes precedence?
2 Likes
This is a nasty one!
2 Likes
I have wrote up a article outline of the article Arguments for Meteor — Theodor Diaconu, CEO of Cult of Coders: “Redis Oplog, Grapher, and Apollo Live..
Hope it have some help.
4 Likes