@filipenevola, hope this is not an effect of the fixes you are implementing regarding the expired certificates. This is causing even more downtime to one of our customers, in addition of the 15 hours of downtime we’ve exprienced today for another 5 of our customers.
I’m not sure what you mean but containers are not restarted, they are replaced so the container will be killed but other container is going to be running in another machine with your app.
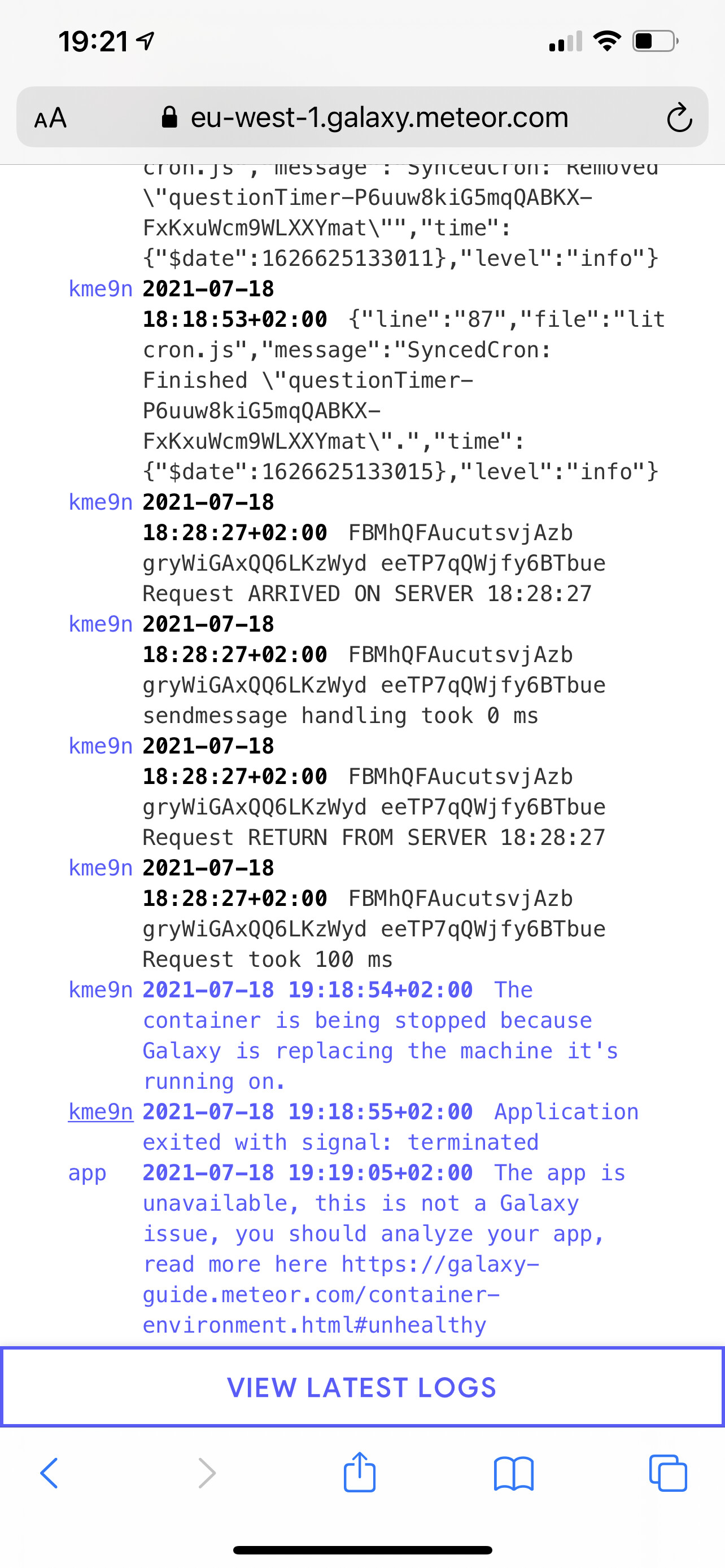
@filipenevola this application was down for 12 minutes as a result of a Galaxy initiated container replacement. We had to stop/start to get it running again. The start signal (manual!) made it spin up again.
The behaviour was similar to the other applications that went down as part of today’s issues. Just to make it clear; this happened after problems were reported resolved.
**
It makes us wonder whether we need to stay up to monitor downtime on other applications/containers because of the restarts you’ve announce as part of the resolution.
**
Logging (TZ CET, GMT+2)
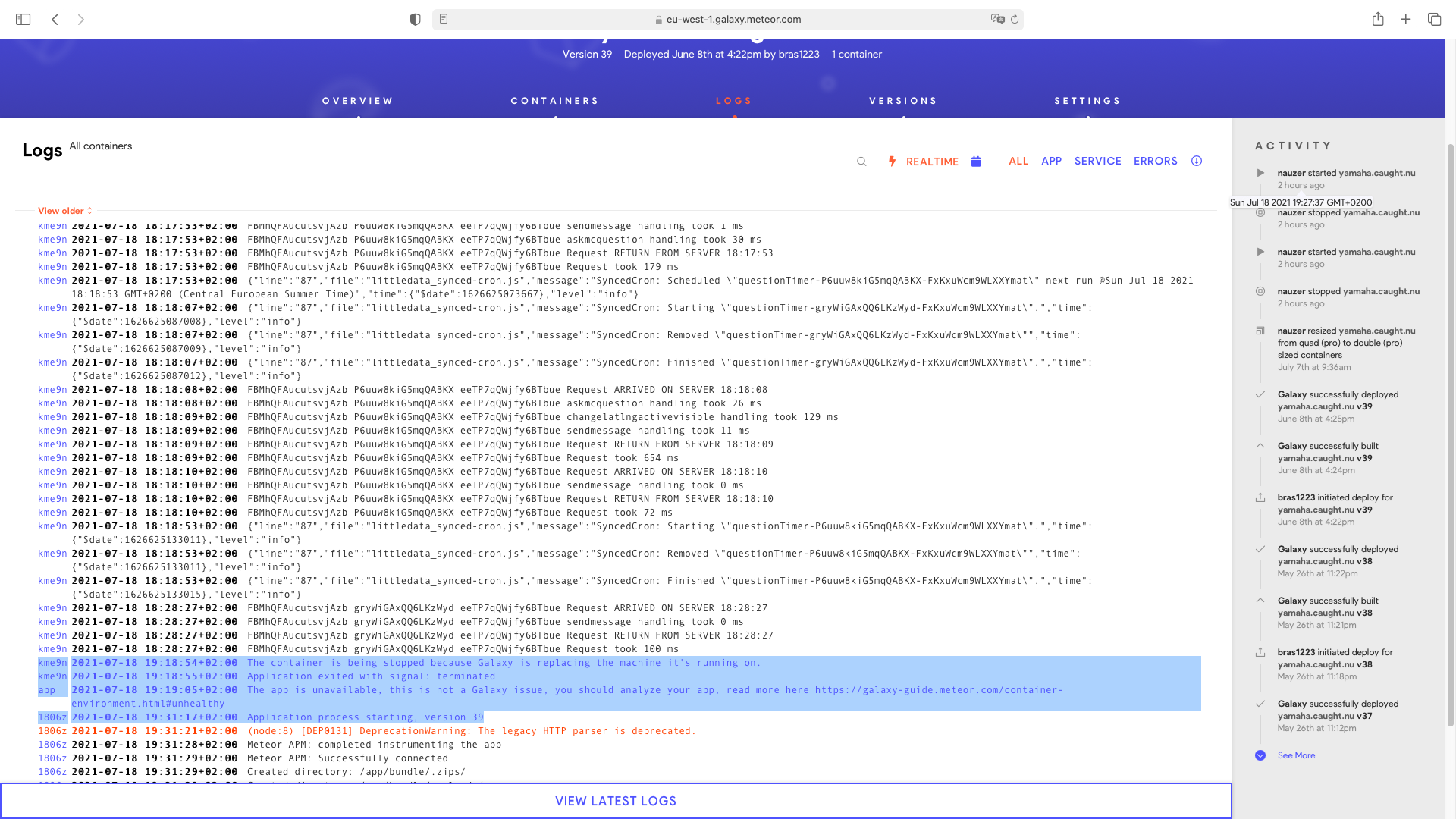
kme9n2021-07-18 19:18:54+02:00The container is being stopped because Galaxy is replacing the machine it’s running on.
kme9n2021-07-18 19:18:55+02:00Application exited with signal: terminated
app2021-07-18 19:19:05+02:00The app is unavailable, this is not a Galaxy issue, you should analyze your app, read more here Container environment | Galaxy Docs
1806z2021-07-18 19:31:17+02:00Application process starting, version 39
The machine replacement takes time to avoid moving many containers from the same app too fast. The underlying issue was indeed solved when we reported.
Meaning - any Galaxy initiated container replacement that happens as of the moment of reporting ‘fixed’ should have not cause issues - correct?
Sorry for not letting loose on this but if we cannot be sure that any replacement occurring over the coming night doesn’t cause the same issue again we need to know and have an alternative…