@peterfkruger was so nice to have a look at the system with me, in a longer web session 
What we noticed, and what’s pretty strange: The production server and the staging server behave completely differently, using (almost) the same code base.
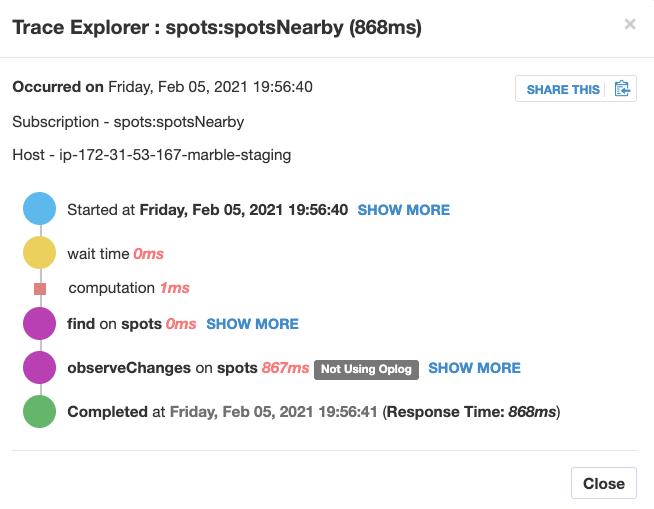
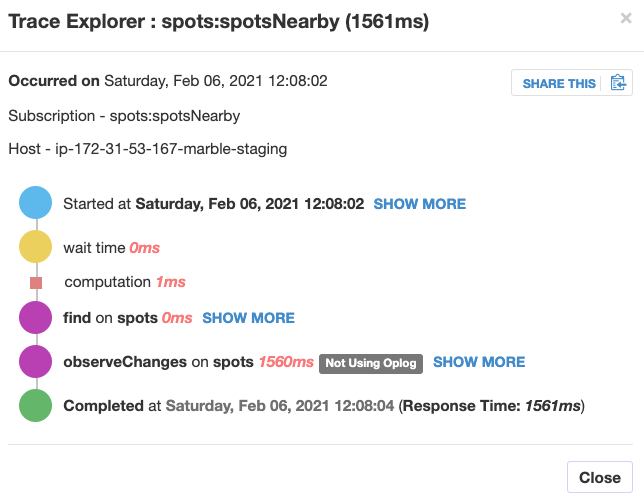
On the staging system (which is running on a t2.small instance), a typical pub trace looks like this:
which is pretty normal.
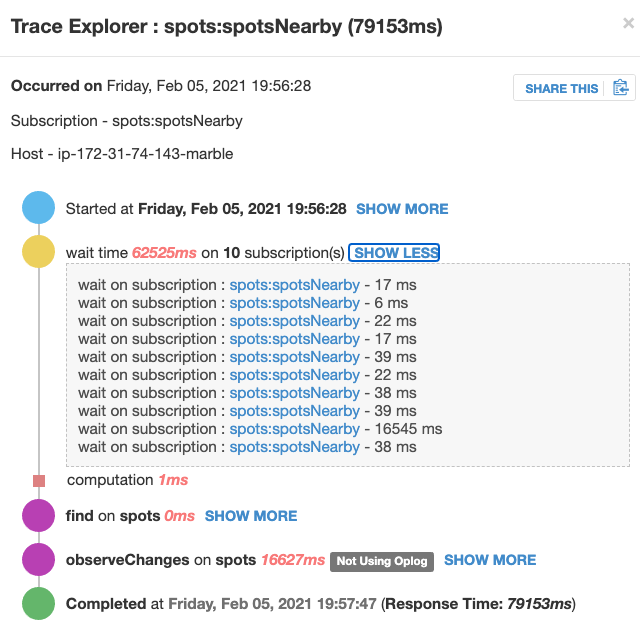
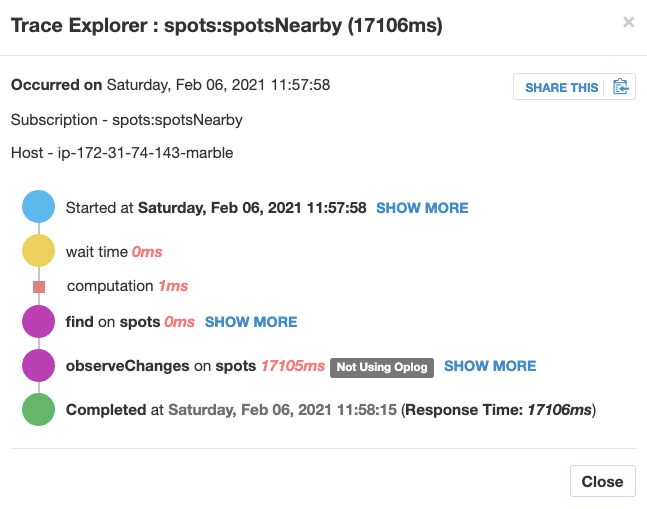
Whereas on the prod server (running on a t2.medium), it looks like this:
My explanation for the multiple subscriptions: This is a map where we panned across, which causes parameter updates and thus re-subscriptions for another map viewport.
The reason why one of the sub takes longer than the others is that this was on a low zoom level so there’s more data on the map. But still, we’re talking about a hundred vs. 5-6k elements, this won’t explain why it takes 1000x longer.
Plus, we did exactly the same user interactions on both the prod system and the staging system, so we are wondering why on the staging there is almost no wait time, whereas on the prod there is (same data)? There was no significant user load on both of the systems at that time.
The reason why “Not using oplog” shows up here is that I am using a $nearSphere query for this sub. As I just recently learned, Meteor falls back to non-oplog in this case. But that’s also the same for the staging system. I even stopped and restarted the EC2 instance now, but the problem still persists. I’m pretty clueless why this happens.
(Another very strange thing: If I start the app in Chrome right after starting the browser, the initial map load works fine. But as soon as I reload the page or pan to another map location, the sub starts to stall again. On Firefox and Safari, however, the problem occurs even on initial page load. @peterfkruger accessed the same systems on his PC hundreds of miles away, with the exact same results. So it’s not a network issue or something like that.)
What puzzles me the most: How can the same app under (almost) identical conditions (slightly larger EC2 instance, larger MongoDB cluster on the prod system) behave so differently?


 That’s quite something, we’ve been chasing a ghost!
That’s quite something, we’ve been chasing a ghost!