Wait. So I no nothing of Flux, Relay (the FB stack). @serkandurusoy, do you see us Meteor devs needing to learn one or both of these in order to use React with Meteor? We can’t or shouldn’t use Methods? Will we eventually need to learn Flux or Relay in order to get the most out of React, even on Meteor?
Flux is just a pattern to share data between React components. Without Meteor something like this is essential to pass data around.
With Meteor you don’t have to follow the flux pattern because the reactive data sources allow us to update the UI without any kind of event wiring. Sticking data into a Session variable and rendering with getMeteorData will work.
Learning about flux will allow you to further understand how the React ecosystem thinks about data flow but is not required.
4 Likes
I want to add a bit about this.
With Meteor, app architecture is solely to us how we model and design it. It’s vary from the project to project.
So, it’s sometimes harder for a new comer to join with the project. If we follow a pattern like FLUX (via redux), it’s easy for someone new to join with the project.
I think Meteor Guide is good way to show some pattern on building Meteor apps. +1 on that.
10 Likes
+1
I recently had to onboard some developers and it was really fast for devs to hop in and get working if they already knew React and Redux. They just had to learn about how Meteor handles data and they were off to the races.
1 Like
@aadams as always, @SkinnyGeek1010 and @arunoda are spot on.
That’s just a pattern and you don’t have to learn it while you can definitely benefit from it.
Also there is a nice blog post back from august which is a good read on this subject.
1 Like
23 Likes
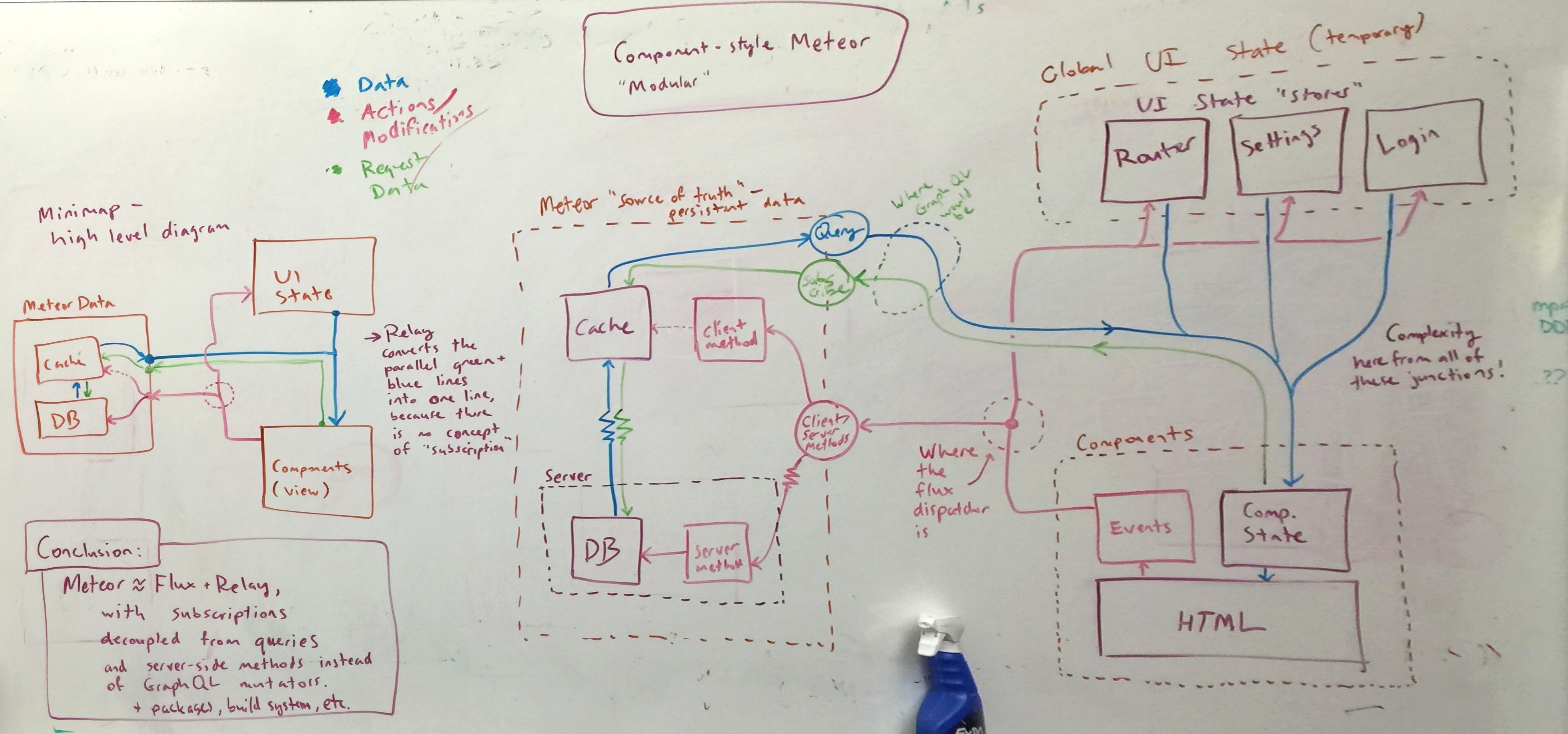
I have been trying to figure out for a while the best way to do extensible apps with Meteor for the next version of Worona. I will share my experiences with Flux and Meteor in case they are of some use here.
Sometimes I read about how Meteor and Flux relate to each other on posts or threads. I don’t think there is a direct resemblance. Meteor is a platform and Flux is an architecture.
I think there is a lot of confusion because people try to use other JS Flux implementations (created without Meteor in mind) in Meteor instead of just applying the principles of the architecture.
In my opinion, Flux just brings these principles to the table:
- Total decoupling of the View layer using the Dispatcher for events and a single object tree State for data (this is from Redux).
- One way data flow (easier debugging).
- No chained actions (easier debugging).
- Easier structure and code organisation.
I think each of those principles are good for a Meteor app because by default, Meteor comes without rules.
The View layer decoupling is very important. Designers should be able to write the UI with no/minimum javascript use.
Dispatcher is important as well. Its event pattern allows to easily extend the app when something happens.
No chained actions is very useful as well because it forces you to think easier ways to solve the same problem.
One way data flow makes reasoning about your app flow much easier.
What I mean by easier structure and code organisation is that when using Flux, you know that views can only dispatch, stores contain logic and modify data, they are structured by domain, state is a single object tree, and so on. So you don’t have to think where to put (or find!) stuff, you just write code. This code organisation is another thing Meteor doesn’t have.
At first, I tried to make Flux work with a port of the Facebook’s dispatcher. It was great, but if found the Flux’ “Action-driven” architecture collides with Meteor’s “Data-driven” mentality. I tried to solve it but:
- When I tried using only Flux actions to change the state of my app, the reactive data sources where left behind.
- When I tried to send a Flux action each time Meteor was changing some data, Meteor reactivity lost its magic and I ended up with a lot of not useful boilerplate code.
So that approach wasn’t working. Besides I wanted to introduce a single object tree for the whole state of the app in a kind of a Redux style.
I am a huge fan of Tracker. Reactive code is way easier to write and maintain. So it didn’t make sense to not use reactivity for the single object tree. I wrote a package called ReactiveState and it is working really well. People is using it even for other non-Flux apps.
Then, I went back and forth with Flux until I figured out a way to make both worlds (Flux’ Action-driven and Meteor’s Data-driven) work together. The solution was to make Flux actions reactive, but still have a non-reactive phase at the beginning and at the end of each dispatch.
The result is the MeteorFlux framework. I consider it still in development but so far it is working really well. GitHub - luisherranz/meteorflux: Flux architecture for Meteor
The Dispatcher starts the one-way-data-flow and it looks like this:
<a href="#" dispatch="CHECK_WP_API">Try again</a>
or in javascript:
Template.ApiChecker.events({
'click .change-url'(event, template) {
let url = template.find('input[name=url]');
Dispatch('APP_CHANGED', { url });
}
});
That’s it. Views aren’t allowed to do anything else.
After the dispatch, you can write two types of callbacks:
- Normal (non-reactive) Store callbacks:
Register(() => {
switch (Action.type()) {
case 'NEW_APP_CREATED':
Meteor.call('addNewApp', data);
break;
case 'APP_CHANGED':
let id = State.get('app.id');
Meteor.call('changeApp', id, data);
break;
}
});
// or async actions as well:
Register(() => {
if (Action.is('LOGOUT')) {
Meteor.logout( function(error) {
if (!error) {
Dispatch('LOGOUT_SUCCEED').then('SHOW_LOGIN');
} else {
Dispatch('LOGOUT_FAILED', { error });
}
});
}
});
- And then use reactive State modifications (called reducers in Redux):
// dependent on Flux actions...
State.modify('apiChecker.error', (state = false) => {
switch (Action.type()) {
case 'API_CHECK_FAILED':
return true;
case 'CHECK_API':
case 'API_CHECK_SUCCEED':
return false;
default:
return state;
}
});
// or dependent on Meteor reactive sources...
State.modify('apps.items', (state = []) => {
return Apps.find({}, { sort: { modifiedAt: -1 } });
});
let handle = Meteor.subscribe('apps');
State.modify('apps.isReady', (state = false) => {
return (!!handle && handle.ready());
});
State.modify('app', (state = {}) => {
let appId = State.get('app.id');
return Apps.findOne(appId);
});
Finally use State to render the View. It is available everywhere, designers don’t need helpers.
<div class="ui grey header">
Welcome {{profile.firstName}}!
</div>
<button class="ui button" dispatch="OPEN_NEW_APP_FORM">
Add another app!
</button>
<div class="ui subheader">
Choose an app:
</div>
{{#if apps.isReady}}
<div class="ui cards">
{{#each apps.items}}
<button class="header" dispatch="SHOW_APP" data-id={{_id}}>
{{name}}
</button>
<div class="meta">
<strong>Url:</strong> {{url}}
</div>
<div class="meta">
<strong>Modified:</strong> {{moFromNow modifiedAt}}
</div>
{{/each}}
</div>
{{else}}
Apps are loading, please wait!
{{/if}}
The log of the app is easy to follow and looks like this:
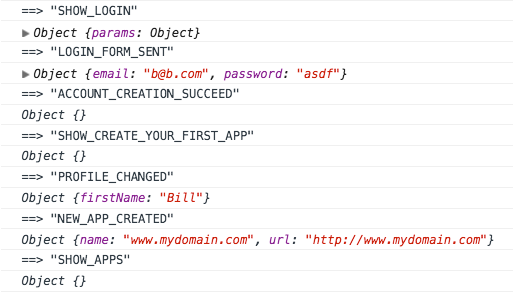
What the user did here was to enter its email and password on a login form. He didn’t have account yet, so we created a new one for him and showed him a special form called “Create your first app” asking for his name as well. When he submitted the form, the profile was changed, a new app was created and he is sitting now in the screen which shows him his list of apps.
This combination of Tracker and Flux is working really well so far. Logic is easy to write, strong against bugs (thanks to Tracker) easy to reason about and easy to extend (thanks to Flux).
The view layer is also easier to write and any designer can jump in. They only need a list of actions they can dispatch and the available tree of State. They shouldn’t care if data is coming from an external API, Minimongo, a javascript variable… whatever.
I don’t have easier examples to show at the moment other than the product we are building:
It is still in the first steps but if you are interested, you can get an idea. We are using “everything-is-a-package” as well. You can take a look at the action.js and state.js files of the dashboard packages to see more code examples.
14 Likes
I like where this is going, really good thoughts here & I hope it continues!
Redux is nice because when implemented properly, every single state change flows through the store, regardless of whether it’s a local change or persisted change. Data can’t come from or go to the server without going through redux. Minimongo achieves this, but is tightly coupled to…well, a lot of stuff. It also doesn’t care about state on the client.
Regarding client-only state, I can tell when a form is dirty, a url param has changed, a socket was interrupted, an auth token refreshed, or a css animation is happening all by looking at the “single source of truth”. This is really powerful because I can pass any subset of these truths to a component as a prop, which gives me fine-grained reactivity.
You can even use redux as a client-side cache to replace minimongo with a fully optimistic UI: https://github.com/mattkrick/meatier/blob/master/src/universal/redux/middleware/optimisticMiddleware.js#L28
Meteor 1.3 moving towards NPM is a great step #1, this would be an amazing step #3 (step #2 being a move to node 4 ;))
1 Like
Redux allows your UI to be a pure function. This comes with lots of benefits. For me, personally, the two biggest benefits are abstraction and time travel. You can record flows and save them for later. You can bundle up the entire user state and action sequences and send it to your server whenever theres a runtime exception. You can also generate tests for your application just by using it and recording the state-action sequences. Its really a pattern more than a framework. I’ve been reading about the Elm Architecture a bunch lately and its really opened my eyes to how user interfaces should be built.
4 Likes
I agree that redux is great with its abstraction and developer tools. Something we really missed in Blaze. But it’s just one way to build a modern app. People are hating on state mutation because it is indeed hard to manage…but to say its how you SHOULD build something is a little strong don’t you think Chet?
Meteor on the client has a DB which most frameworks do not. The concept of stores in other frameworks are objects or arrays. Then they have to have event emitters or fake callbacks to update things to keep stores in sync with actions that just happened. That’s why rehydration is a huge thing in Flux Architectures. The thing that these patterns lack is Tracker. Plain and simple, reactivity on the client is what brings Meteor, Minimongo at the forefront of a flux pattern.
You have stores (either client side local collections, minimongo bound collections, reactive vars, dicts, session) w/e
You then dispatch actions, which today meteor apps are over doing it in the view layer with Meteor.methods, but if they sent these actions via a dispatcher/or some action layer, then you could have some separation of concerns there
Actions cause state change, and the stores are aware immediately. No need for extra callbacks, or store subscribes. Tracker glues this together for us.
Elm though is indeed far out, and if I had a lack of client side reactivity in tracker I’d jump on the Redux/Elm bandwagon.
3 Likes
I totally agree with your opinion @abhiaiyer. Redux is only a way to build a modern app. Meteor (with Tracker) is another, valid as well.
Code is simpler when using Tracker (transparent reactivity), that’s for sure. The only thing it lacks, is some organisation so when your app grows it doesn’t end up being a mess. I think that’s the problem of many people. Not Tracker itself.
Again, I agree with you. I think Flux is a good way to separate concerns, keep your flow easy to debug and your code organised. That’s the reason MeteorFlux uses Flux for code organisation but still embraces Tracker and it doesn’t try to replace it with Redux or any other external tool.
By the way, I think it’s worth to mention there the last article of @faceyspacey about this topic:
It’s a really good read and I totally agree with him as well.
2 Likes
@abhiaiyer I don’t want to come across as nit-picky but I think these are great points to discuss. Here’s my take:
I think that if you compare flux/Redux with Meteor for non-persistent data you’ll find that things fall apart really quickly. You can no longer try to map ‘actions’ to Meteor methods, and mini-mongo is not really applicable (you could use null collections but Session and template var are more applicable).
Redux/flux is the easiest when not dealing with AJAX/Database data but gets a little more complex if you do, as you have to invalidate the cache (store) manually.
Meteor does not have a DB on the client… it’s just a cache, like a Redux store. Minimongo is specifically a write-though cache from what I understand which Redux does not have (you have to manually handle IO). Minimongo also stores data in arrays, it just uses Tracker to update them.
Using Tracker in React has been the root of all of my React performance problems and much prefer the events used in Redux. It takes a choppy laggy UI with Tracker and makes it silky smooth using connect in Redux.
Elm though is indeed far out, and if I had a lack of client side reactivity in tracker I’d jump on the Redux/Elm bandwagon.
Elm does look pretty cool! I’m still not sure how they do SPAs with a router but someday i’ll have enough time to check this out fully 
1 Like
You can map actions to methods if you implement logging. Which is extra effort but worth it for local collection state. I think people forget that users can hit save buttons and things don’t have to be reactive with the server.
To your point on minimongo. Now you’re talking semantics. Minimongo may not be “db” but you can approach your apps with the mentality that it is.
1 Like
Its certainly an opinion. But I have my reasons: I say “should” because when your entire application is composed of pure functions, then your program is literally a mathematical proof-by-induction. And if you were programming in Haskell, you get amazing things like “deterministic parallelism”. Now that sounds like just a bunch of worthless fancy words and you’re sort of right – you can build software however you want!  But I really suggest diving deep into functional programming. It took me a while before it really clicked in my head and I though, “man, this is the way you’re supposed be doing it!”.
But I really suggest diving deep into functional programming. It took me a while before it really clicked in my head and I though, “man, this is the way you’re supposed be doing it!”.
To your other points:
-
Tracker is amazing and really cool, but it inherently causes side-effects which is why Meteor feels so magical. But you can easily find yourself getting entangled with Tracker.autorun. I prefer the explicitness of pure functions. What’s so great about pure functions is you never have to open up another file – everything this function is concerned with is given as an argument.
-
Minimongo is full of side-effects that are out of your control. Flux isn’t as much about dispatching and updating as it is about a functional programming pattern for reactivity involving pure functions. So creating a thin layer on top of Meteor to incorporate Flux is pretty much worthless so long as you’re imperatively calling Meteor.subscribe and Meteor.unsubscribe within the lifecycle of your views. Now this probably sounds vague, but consider something like time-travel. Flux sets you up really nice for time-travel. To do time-travel properly, you need your entire application to be a pure function. With minimongo sending side-effects that are out of our control, you’ll never be able to create a slider that can show you the state of your entire application (including the minimongo cache).
I’ve been working on a little project of mine called elmish and I’m building some tutorials right now. You should check them out and let me know what you think. And let me know in an issue ticket if theres anything I should clarify. @SkinnyGeek1010, I’d love to hear your thoughts as well.
2 Likes
It looks like there are multiple versions of LINQ for javascript that might make that a bit more palatable.

Hey @SkinnyGeek1010 and @ccorcos I wrote an entire medium article response to your comments here:
HERE IT IS:
The summary is the problem is one thing:
- tracker re-runs functions many times more than they need to be re-run (which is the sole cause of Blaze rendering jankiness).
and a fair fight would be “Tracker 2.0” vs. Redux, and what Tracker 2.0 would have fixed is:
- re-runs only occur if the precise dependent data utilized changes, not just because
dependency.changed()was called - “property-level cursors” that automatically populate the
fieldsoption, eg:post.titlewithin Spacebars automatically makes yourfieldsoption become:Posts.find(selector, {fields: {title: 1}}) - an
optionsparam toTracker.autorun(func, options)to further constrain what triggers re-runs - once re-runs don’t run more than they have to, snapshotting
MinimongoandReactiveDictbecome a real option, and we can time travel (even if Minimongo is made of mutable state) - we need a Chrome devtools extension to visualize tracker dependencies between functions (graph diagram) as well as a 2nd visualization that depicts the stack frame of dependent autoruns sequentially. Picture “branches” of the graph highlighting as they update similar to the React devtools for components. Now you would know exactly what your autoruns are doing!
6 Likes
I would add to this conversation this excellent article from the creator of Mobservable (a Tracker-like library for React): https://www.mendix.com/tech-blog/making-react-reactive-pursuit-high-performing-easily-maintainable-react-apps/
A combination of a controlled/optimised Tracker (like @faceyspacey suggests) and the React virtual-dom (or BlazeReact) would give us the best of both worlds: control invalidations in the logic and in the DOM.
2 Likes
…I think you meant “TrackerReact”.
…Regarding Michel Weststrate, the creator of Mobservable, here’s a talk he just gave 2 weeks ago along guys like @staltz (creator of Cycle.js) at Reactive conference:
My point in sharing that and Mobservable in general is to indicate that there is a model and a path forward for “Transparent Reactive Programming,” which is the model of reactivity autoruns was always a part of (not sure why I never heard that term until recently). It’s always felt like Meteor’s been the only one to implement reactivity like “autoruns,” but the reality is there are other examples, and it’s looking like even better examples.
Here’s one more article from Michel Weststrate worth checking out:
4 Likes
Nice article! Just wanted to add that I agree with your last point:
Redux is for “UI STATE” and Relay is for “DOMAIN STATE”. In Meteor, Minimongo is also for “domain state” but we have no good “ui state” pattern. Conversely, people using Redux for “domain state” are doing it wrong and will likely change to Relay as it evolves (that’s my prediction).
Redux works very very well for ‘transient’ UI State but it’s not ideal for database state or ‘Domain State’ as you referred to it. I’ve primarily used Redux for domain state in React Native where neither Relay nor Minimongo exist and it’s ok in a simple app but it cant be complicated to invalidate your cache on complex apps.
I’ve experimented using Redux for domain state in Meteor and the only advantage to doing that is to work around Tracker inefficiency, as getMeteorData is much easier to use than Redux. I do love the approach of Relay though, the UI just says what data shape it wants and Relay gets it.
3 Likes