Hey everyone,
I’ve been thinking a lot about where Meteor is headed, and I wanted to share something I’ve been prototyping. It’s not a PR, it’s not production-ready, and it’s not a proposal to change anything right now. It’s a concept — a proof-of-concept for what Meteor’s data layer could look like once the codebase modernization is further along.
The idea: Adaptive Federated Streams (AFS)
The core question is simple: what if Meteor’s reactive data model wasn’t married to MongoDB?
Meteor’s reactivity is genuinely one of the best things about the framework. The tight loop between database changes, DDP, publications, and Minimongo on the client — it’s elegant, and it’s the reason building real-time apps in Meteor still feels better than most alternatives. But it’s always been coupled to MongoDB, and that coupling has been a dealbreaker for a lot of teams and projects over the years.
AFS is an abstraction layer that separates “Meteor’s reactive collection API” from “the database that stores the data.” The goal is that your app code stays exactly the same — find, insert, update, remove, observe, publish/subscribe — but the storage backend becomes pluggable.
Instead of Mongo.Collection, you’d write:
const Todos = new Postgres.Collection('todos', {
schema: {
title: { type: 'text', required: true },
completed: { type: 'boolean', default: false },
created_at: { type: 'timestamp', default: 'now' },
},
});
And then everything else is exactly what you already know:
Meteor.publish('todos', function () {
return Todos.find({}, { sort: { created_at: -1 } });
});
Meteor.methods({
async 'todos.add'(title) {
return Todos.insertAsync({ title, completed: false });
},
});
Publications, methods, client-side queries — all identical. The client doesn’t know or care what database is behind the collection.
How it works
AFS introduces a StreamProvider — an adapter interface that any database can implement. A provider handles three things:
- Queries — translate MongoDB-style selectors into whatever your database understands
- Writes — translate
$set,$unset,$inc, etc. into native operations - Reactivity — observe changes and fire
added/changed/removedcallbacks
The reactivity mechanism varies by database. PostgreSQL uses LISTEN/NOTIFY. Redis would use pub/sub. SQLite would poll-and-diff. A REST API wrapper would poll on an interval. The point is that AFS doesn’t care how you detect changes — it just needs the callbacks.
Client (Minimongo + DDP) Server
┌──────────────────────┐ ┌──────────────────────────────┐
│ │ │ AFS.Collection('todos') │
│ Todos.find() │◄── DDP ──┤ │ │
│ Todos.insert(...) ├── DDP ──►│ StreamProvider │
│ │ │ ├── PostgresProvider │
└──────────────────────┘ │ ├── MongoProvider │
│ ├── RedisProvider │
│ └── ... │
└──────────────────────────────┘
You can even mix providers in the same app:
// Persistent data in PostgreSQL
const Users = new AFS.Collection('users', { provider: pgProvider });
// Ephemeral sessions in Redis
const Sessions = new AFS.Collection('sessions', { provider: redisProvider });
Both work identically from the client.
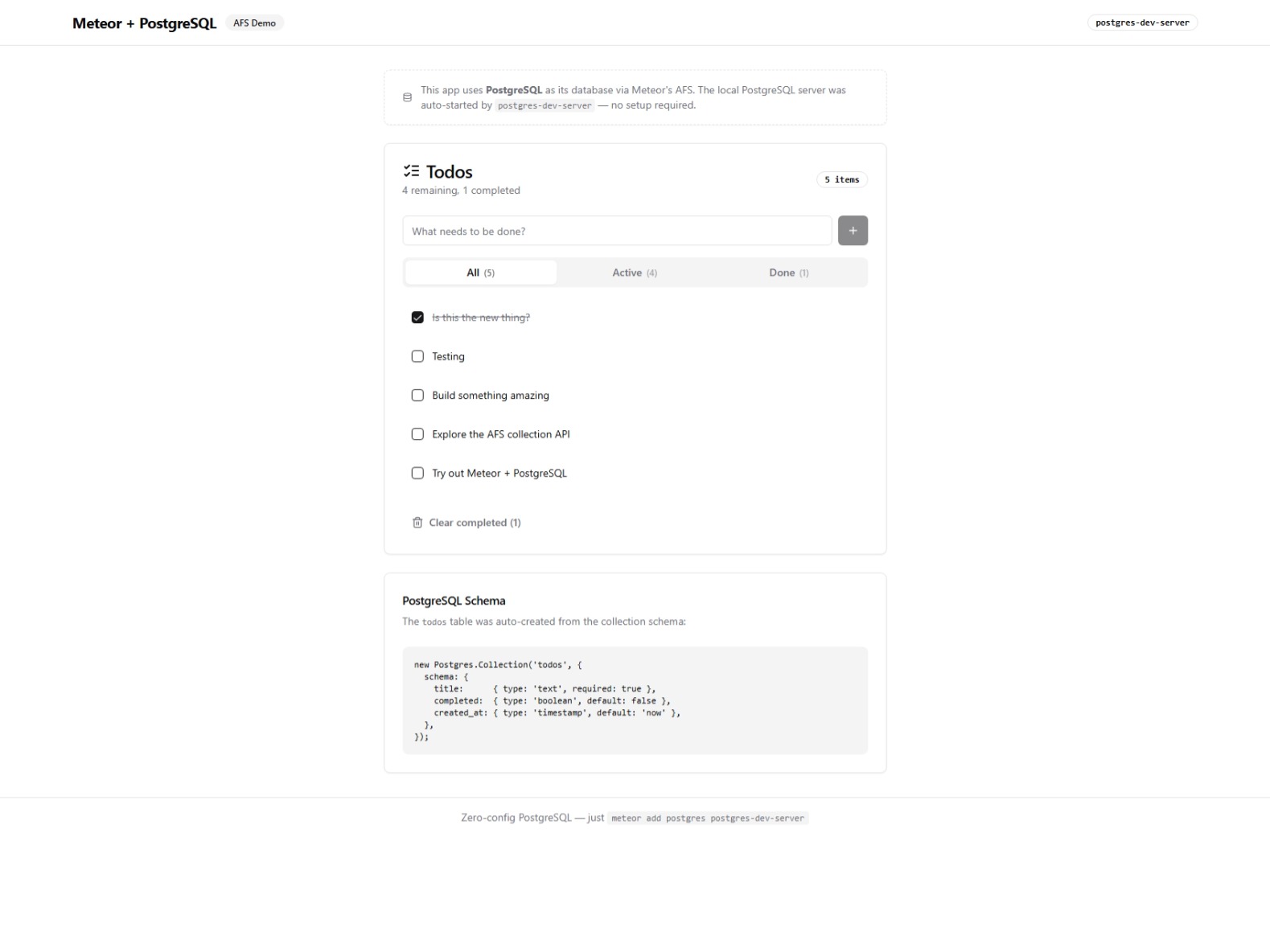
The demo: a working todo app on PostgreSQL
I built a demo app — a standard todo list with React and a modern UI — that runs entirely on PostgreSQL instead of MongoDB. It uses Postgres.Collection with a typed schema, and the experience is indistinguishable from a normal Meteor app.
The dev experience is also preserved. Just like mongo-dev-server auto-starts a local MongoDB, the demo includes a postgres-dev-server package that auto-downloads the PostgreSQL binary, starts it on the next available port, and sets POSTGRES_URL — zero config. meteor add postgres postgres-dev-server and you’re done.
Why not now? Why share this at all?
I want to be upfront: I don’t think this should be built yet. And I don’t think the current codebase is ready for it.
Meteor is in the middle of a real modernization push, and that work needs to come first. The 3.x line brought critical foundational changes — proper async/await throughout, dropping Fibers. The upcoming work (things like 3.5’s MongoDB Change Streams support) is exactly the kind of infrastructure improvement that makes something like AFS viable later.
Change Streams in particular is relevant because it replaces the oplog tailing approach with something much more robust and scalable. That same pattern — native database change feeds driving reactive queries — is exactly what AFS’s StreamProvider.observeChanges() is designed around. Getting that right for MongoDB first means the abstraction will be battle-tested before anyone tries to generalize it.
So the sequencing I’d suggest is:
- Now: Keep modernizing. Finish the async migration, ship Change Streams, improve the build system, all the stuff that’s already in progress.
- Later: Once the core is modern and stable, then look at whether abstracting the data layer makes sense. AFS is one way it could work. There might be better approaches once the dust settles.
I’m sharing this now because I think it’s worth having the conversation. Not “should we build this tomorrow” but “is this the kind of thing that could matter for Meteor’s future?”
What this could mean for Meteor
If I’m being optimistic — and I am — I think Meteor is heading into a renaissance. The framework’s core ideas (reactive data, isomorphic code, zero-config dev experience) are as relevant as ever. What held Meteor back wasn’t the ideas — it was the implementation constraints. MongoDB lock-in. Fibers. The build system.
Those constraints are being removed one by one. Fibers are gone. The build system is getting modernized. If the database lock-in goes too, Meteor becomes a genuinely compelling choice for a much wider audience. Teams that need PostgreSQL for compliance. Projects that want SQLite for simplicity. Apps that already have data in Redis or behind REST APIs.
And the beauty of this approach is that nothing breaks. Existing MongoDB apps continue working exactly as they do today. Mongo.Collection isn’t going anywhere. AFS just gives you more options.
The StreamProvider interface (for the curious)
Writing a provider isn’t complicated. Here’s the skeleton:
class MyProvider extends AFS.StreamProvider {
async insertAsync(collectionName, doc) { /* ... */ }
async updateAsync(collectionName, selector, modifier, options) { /* ... */ }
async removeAsync(collectionName, selector) { /* ... */ }
find(collectionName, selector, options) { /* return cursor */ }
async observeChanges(cursorDescription, ordered, callbacks) { /* ... */ }
}
Five methods. That’s the core contract. Providers also declare capabilities so the framework knows what they support (transactions, full-text search, joins, etc.) and apps can make smart decisions.
Each provider can also ship a -dev-server package for the zero-config local experience:
| Package | Dev server | Reactivity |
|---|---|---|
postgres |
postgres-dev-server |
LISTEN/NOTIFY |
mongo |
mongo-dev-server |
Change Streams / oplog |
sqlite |
(none needed) | Poll and diff |
redis |
redis-dev-server |
Pub/sub |
Try it yourself
If you want to kick the tires, here’s how to get the demo running locally. You’ll need a local checkout of the Meteor fork since AFS isn’t in mainline Meteor.
1. Clone both repos:
git clone -b adaptive-federated-streams https://github.com/mvogttech/meteor.git
git clone https://github.com/mvogttech/meteor-afs-demo.git
2. Install npm dependencies in the demo app:
cd meteor-afs-demo
../meteor/meteor npm install //Or Wherever your Meteor checkout is
3. Run the app using the local Meteor checkout:
../meteor/meteor run //Or Wherever your Meteor checkout is
That’s it. On first run, Meteor will:
- Download a PostgreSQL binary automatically (this takes a minute the first time)
- Initialize a local data directory at
.meteor/local/pgdata/ - Start PostgreSQL on port
3002(your app port + 2) - Set
POSTGRES_URLin the app’s environment - Create the
todostable from the collection schema - Seed a few sample todos
You should see Started PostgreSQL. in the console output, and the app will be running at http://localhost:3000. Everything — inserts, toggles, deletes, reactivity — is hitting PostgreSQL, not MongoDB.
If you already have PostgreSQL running and want to use that instead:
POSTGRES_URL=postgresql://user:pass@localhost:5432/mydb ../meteor/meteor run
When POSTGRES_URL is set, the dev server is skipped entirely.
To start fresh, meteor reset wipes both the MongoDB and PostgreSQL data directories.
Wrapping up
This is an experiment, a conversation starter. The code exists, the demo works, but this isn’t ready for production and that’s fine. The point is to show that Meteor’s reactive model is more general than MongoDB, and that decoupling them is both possible and natural.
I’m curious what people think. Is database flexibility something that would matter for your projects? Are there databases or data sources you’d want to use with Meteor’s reactive model? What would need to be true before you’d trust something like this in production?
Looking forward to the discussion.
Links:
- AFS branch (Meteor fork) — the AFS package, PostgreSQL provider, and dev server integration
- Demo todo app — a working Meteor app using
Postgres.Collectionwith React and a modern UI