Hello,
We are having major problems with out internal Meteor app which has about 300 clients connected at all times. For the last few weeks we have been pulling our hair out trying to resolve a bug in the client-server sync.
What happens is that seemingly randomly clients fall out of sync with the server for some collections. It seems like all (or at least most) of the clients fall out of sync at the same time.
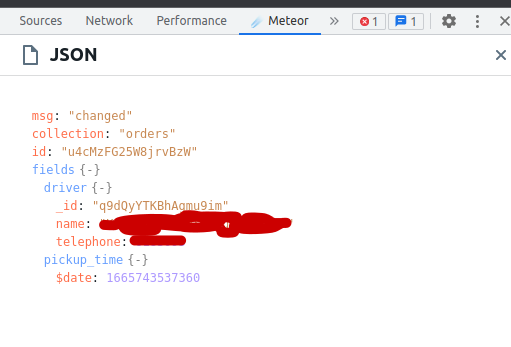
The way it seems to manifest is that some documents in the collection seem to “freeze” at an older stage and no longer respond to collection updates. With Meteor devtools we can confirm that the update message is being sent to the client but Minimongo never registers the update. What’s more is that the document seems to be fully disconnected from the subscription. If we stop the subscription altogether we see all the documents in the collection drop and get removed from the collection except the ones that are causing the problem.
It does seem like this may be (?) related to nested object updates since the problem seems to mostly arise when we set a nested object onto the document. We’ve read on the GitHub that there was a problem with this that should be solved on Meteor 2.8 so we updated our production app to Meteor 2.8-rc.0 but the problem persists.
Notably we have two main servers, server A serves the majority of the clients and does the majority of the logic and server B hosts fewer clients but also runs the MongoDB which both servers connect to. It seems like the clients on server A are mostly affected although we are not fully sure how absolute that is. The load on both servers is well within limits for both CPU and memory.
What we have tried:
- Updated to Meteor 2.8 rc.0 (problem was first noted on Meteor 2.2 on MongoDB 2.6 and we upgraded first to Meteor 2.7 and MongoDB 6 but when that failed to resolve the issue we upgraded to Meteor 2.8)
- Refreshed subscriptions regularly (on an interval)
- Gone over the publish and subscription logic with a fine comb, going so far as to disable most of the security logic to make sure it’s not being stopped at any stage.
- Drastically limited the fields being published to reduce overhead.
- Restarted the clients and servers multiple times.
For reference the collection in question typically has 1-10 documents per client being a few kB each except for our admin overview which subscribes to hundreds of documents for a few MB in total.
Luckily we control all the client hardware so our current workaround is hard refreshing all clients through our device management system on a three minute interval which is obviously a terrible long term solution but this app is critical to our business so it’s preferable to having unreliable reactivity.
Any advice, suggestions or ideas are most appreciated because to be honest we are at a loss here.
Edit: should have mentioned this: We are unable to reproduce this problem while running the server on our development machines. Even when connecting Meteor to the same production MongoDB instance that our production servers use.