Same here, our app won’t restart anymore, any hints what’s going on? Seems to have happened out of the blue, app went to max RAM usage unexpectedly and got killed (our app is usually in the 50%-60% of RAM usage, we didn’t have more users than usual).
@maxhodges When was your last deploy before those three? Basically, that error message means that the container did not seem responsive so it was reaped in order to launch a new (hopefully functional!) version.
@AndreasGalster Is this an app that you’ve just deployed again or is this an existing app which started behaving this way? Anything in the logs? Definitely contact Galaxy support if you haven’t already.
Currently it’s stuck running two different versions for like an hour. Not a good situation because we are trying to deploy a new version for good reasons.
Chiming in alongside @maxhodges (we’re working together on the project).
We pushed a new version, and during the deployment of that new version, the new containers appeared to hit this error before ever being started. At first we assumed it was a problem in our latest version, but we found that eventually the new version would be deployed. It seems like starting the new containers with the new version will fail several times, or simply take a very long time (>30 minutes) before we get a container running the new version.
The biggest issue is probably that for a significant period of time, we have containers running different versions.
It’s an existing app. Starting/stopping did not help, eventually we re-deployed the app and that did do the trick. Btw. it’s kinda weird that daily logs show the time from 12am -> 6am -> 12pm -> 6pm… it’s kinda problematic for us to wait until the end of the day to see the last few hours before the crash
Did anyone else get server crashes due to being out of memory? I just want to make sure that our RAM issue did not concide with the overall crashes here.
We are using ~20% of memory and I haven’t seen any spikes recently (although I just glanced at the graph, haven’t checked in great detail, and our old containers are gone, so we have no graphs for them).
@maxhodges Generally that behavior is typical of a borked deploy that just won’t (ever) start. Essentially, it keeps failing and failing (due to some error in the application) and eventually Galaxy will restart that container because it isn’t responsive (since the server never actually could start). Have you checked your logs for errors?
@AndreasGalster / @chmac Running out of memory is another reason why a container can become unresponsive. If a container OOMs (Out-of-Memory), it will generally stop responding to the requests which are used to determine if it is still healthy. I would suggest you watch your memory graphs on containers which might be exhibiting this behavior, or any container which when observed over time appears to be growing and growing (in which case it will ultimately fail).
All in all, Galaxy support should be able to help you with these issues!
I am seeing the same thing. Just deployed a new version but it is not being started, apparently. All the galaxy status messages say that the new version has been built and deployed, but I don’t see it.
2017-06-20 16:26:45-07:00Removing intermediate container 4b20fc1acba1
v215
2017-06-20 16:26:45-07:00Successfully built 11eb0cef8fb9
v215
2017-06-20 16:26:45-07:00Pushing image to Galaxy's Docker registry.
v215
2017-06-20 16:27:13-07:00Cleaning up.
v215
2017-06-20 16:27:15-07:00Successfully built version 215.
dbtn
2017-06-20 16:37:55-07:00The container is being stopped because it has failed too many health checks.
Hi folks. In conjunction with a few users who wrote in to support, I discovered a longstanding infrastructure problem that in certain conditions can make container startup very slow. (Specifically, it could take a very long time to pull your app’s Docker image to the app machine.) I just scheduled a maintenance window for Monday to roll out new app machines without this issue. I think the results will be pleasing.
While this issue isn’t new, the new unhealthy container replacement feature made it worse. Before that feature, container startup times could be slow but at least would eventually finish. With the feature, Galaxy kills any container that stays unhealthy for too long, including at startup time, and so it could kill these containers which were taking too long to pull the image before they even started. I’ve raised the timeout for killing unhealthy still-starting containers to a high enough value that hopefully this won’t occur for folks before we fix the underlying issue on Monday. (The timeout for unhealthy containers that have successfully started is unaffected.)
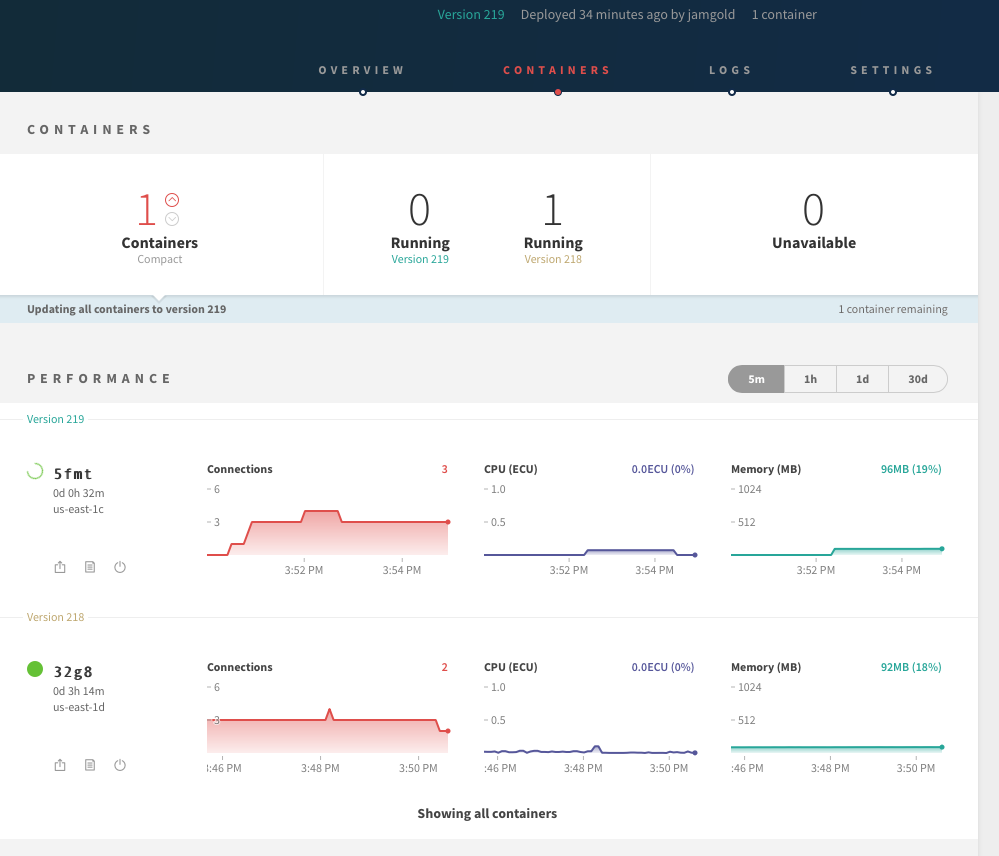
I just deployed a new version of my app to galaxy (35 minutes ago) and have now two containers with different versions of my app running. Can this be related to the changed timeouts?
Even though it says 0 Running for v219 I can connect to it. When I try to connect to the container 32g8 I get
502 Bad Gateway: Registered endpoints failed to handle the request.
UPDATE: container 32g8 is now gone, but UI still says updating
Yes, I can confirm that this was the issue in question — your container was blocked for a long time from being fetched to the machine. Our fix for this is in our QA cluster. Unfortunately, due to our maintenance scheduling policy, we cannot deploy it until Monday.
I hope the infrastructure update Monday fixes this. I’m super frustrated with Galaxy right now, and have been over the past few weeks. Deployments take forever, and often fail (10 minute kill due to failed health checks). Really disappointing for a platform at this price point.