@maxhodges I don’t think compensation would be appropriate here, since (at least for me), it’s not downtime. It’s just sitting in front of my computer for 30 minutes waiting for my code to deploy.
I don’t know whether it’s a shortcoming of Meteor or Galaxy, but a single 1GB container choking on spinning up a Node.js app and spending 10+ minutes doing so, just doesn’t make any sense.
@ffxsam I’m not trying to defend our container start time speed — on the contrary, I’m very excited to get improvements out on Monday and to continue improving over time.
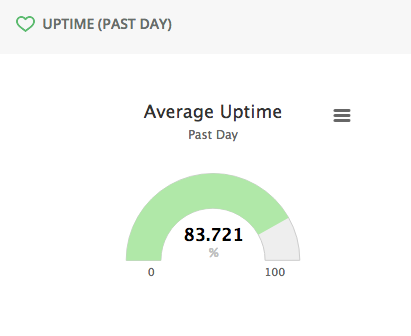
I’m merely saying that single-container apps contain single points of failure and aren’t appropriate for anything that expects 100% uptime. As you said, you didn’t have downtime from this issue. We strive to get even single-container apps as close to 100% uptime as possible, but single-machine failures are always possible in the real world and there’s only so much sympathy I can have for customers who depend on 100% uptime but are unwilling to run more than one container. (And I’m not saying you’re one of them!)
For us one of the deploys was choking for 56 minutes. We deployed multiple times hoping we’d get a healthy container. So cost me quite a lot for me and my 100 euro per hour developer to spend our hours redeploying and reading the logs and trying to figure out what to do. So this kind of issue sadly costs us hundreds of dollars.
The real issue wasn’t downtime but the danger of running two different versions. We were deploying a feature which creates bookkeeping required via our accounting system API. Running two different versions could results in bit of a disaster: some customer, invoice and payments records get written to one account system, and some get written to another.
When you charge a premium price, people expect a premium service. Please test changes before you deploy to production
Generally when deploying an important change is it safer to STOP the existing app and deploy the new one and suffer a bit of downtime? That would prefer running two different versions, for half an hour or how ever long, if something goes wrong with Galaxy container orchestration?
hey now we’ve been down for three hours. I’m in Japan so often I notice problems with Galaxy ahead of other regions.
Galaxy status mentions issues logging into Galaxy, but our actual app is dead. We are losing revenue. This is awful @marktrang
trqnw
2017-06-27 17:55:15+09:00The container is being stopped because it has failed too many health checks.
4knrq
2017-06-27 17:57:38+09:00The container is being stopped because it has failed too many health checks.
dm6a0
2017-06-27 18:08:15+09:00The container is being stopped because it has failed too many health checks.
x22wp
2017-06-27 18:09:52+09:00The container is being stopped because it has failed too many health checks.
80vz0
2017-06-27 18:18:25+09:00The container is being stopped because it has failed too many health checks.
6jxd7
2017-06-27 18:28:35+09:00The container is being stopped because it has failed too many health checks.
1hdt9
2017-06-27 18:29:18+09:00The container is being stopped because it has failed too many health checks.
nk6aw
2017-06-27 18:39:29+09:00The container is being stopped because it has failed too many health checks.
2h9tp
2017-06-27 18:42:33+09:00The container is being stopped because it has failed too many health checks.
q27yz
2017-06-27 18:49:38+09:00The container is being stopped because it has failed too many health checks.
9n7nz
2017-06-27 18:52:45+09:00The container is being stopped because it has failed too many health checks.
fgrm0
2017-06-27 18:59:49+09:00The container is being stopped because it has failed too many health checks.
k1nnt
2017-06-27 19:04:30+09:00The container is being stopped because Galaxy is replacing the machine it’s running on.
jsb45
2017-06-27 19:10:14+09:00The container is being stopped because it has failed too many health checks.
h1v1j
2017-06-27 19:14:58+09:00The container is being stopped because it has failed too many health checks.
b9vza
2017-06-27 19:20:16+09:00The container is being stopped because it has failed too many health checks.
gp7wf
2017-06-27 19:30:25+09:00The container is being stopped because it has failed too many health checks.
1pf5r
2017-06-27 19:40:39+09:00The container is being stopped because it has failed too many health checks.
8hrxj
2017-06-27 19:54:54+09:00The container is being stopped because it has failed too many health checks.
Having the same issue as @maxhodges here. Our site and app are down and all the logs are telling us is that “The container is being stopped because it has failed too many health checks.”
v0239
2017-06-27 20:23:52+09:00Removing intermediate container 83da43b893f2
v0239
2017-06-27 20:23:52+09:00Successfully built 277ac5ad3101
v0239
2017-06-27 20:23:52+09:00Pushing image to Galaxy’s Docker registry.
v0239
2017-06-27 20:24:28+09:00Cleaning up.
v0239
2017-06-27 20:24:30+09:00Successfully built version 239.
sth6g
2017-06-27 20:25:21+09:00The container is being stopped because it has failed too many health checks.
same here. apps are down. Everything worked till last night and stopped today. Redeploying doesn’t help
017-06-27 10:46:28+02:00The container is being stopped because it has failed too many health checks.
ex7c0
2017-06-27 10:56:44+02:00The container is being stopped because it has failed too many health checks.
2w2g1
2017-06-27 11:09:53+02:00The container is being stopped because it has failed too many health checks.
vjz7x
2017-06-27 11:20:18+02:00The container is being stopped because it has failed too many health checks.
r2e0j
2017-06-27 11:39:06+02:00The container is being stopped because it has failed too many health checks.
7b758
2017-06-27 11:53:24+02:00The container is being stopped because it has failed too many health checks.
nkje5
2017-06-27 12:16:42+02:00The container is being stopped because it has failed too many health checks.
bf1nj
2017-06-27 12:30:05+02:00The container is being stopped because it has failed too many health checks.
ghh56
2017-06-27 12:57:36+02:00The container is being stopped because it has failed too many health checks.
xp1nd
2017-06-27 13:16:15+02:00The container is being stopped because it has failed too many health checks.
sgvhs
2017-06-27 13:26:43+02:00The container is being stopped because it has failed too many health checks.
I’m not a part of the Galaxy team but from what I understand apps which have IP Whitelisting enabled are not experiencing this issue. As a suggested workaround, consider enabling that additional feature temporarily in the Galaxy dashboard.
There is no need to actually whitelist anything (and you shouldn’t if you intend on turning it off later), but just merely having the feature active should be enough to work around the problem.
Meteor APM is currently catching up on a backlog of APM stats. It will recover and stats were always being collected (though it’s worth pointing out that non high-availability apps which were down will not have stats to offer during their downtime).
Apps with existing “high-availability” deployments (those who pre-incident had their number of containers set to 3 or higher and were not affected by this outage), will have the Meteor APM data points aggregated and logged soon.
It is my understanding that all affected apps should be back online.