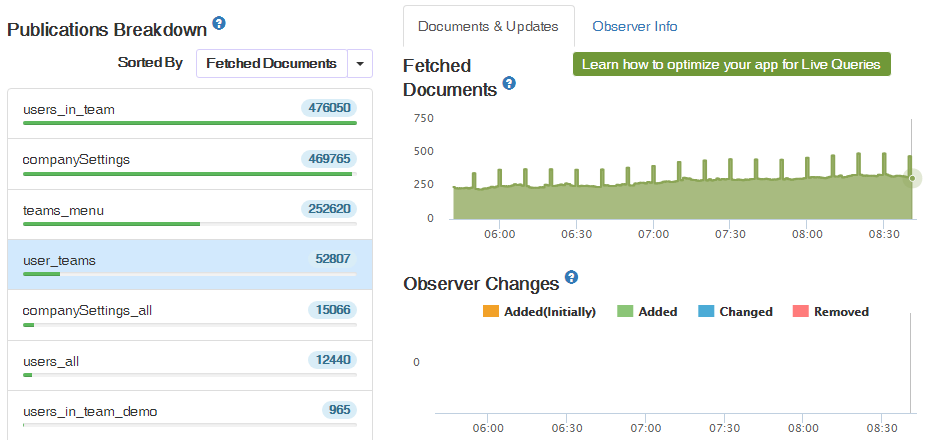
I have a single combined meteor server and MongoDB (I know, but it works for now!), and precicely every 10 minutes I see a CPU spike:
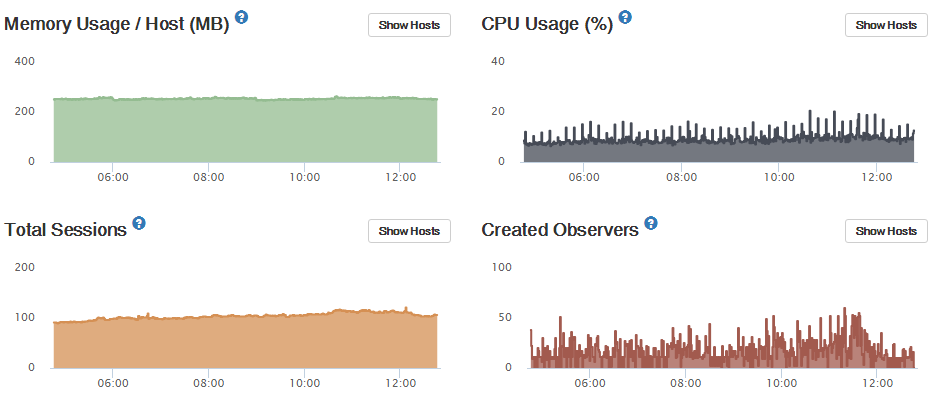
It’s not new but unfortunately I don’t know when I started seeing this. I’ve only just got around to investigating.
I’ve tracked it down to the following code in accounts-base/accounts_server.js:
const setExpireTokensInterval = accounts => {
accounts.expireTokenInterval = Meteor.setInterval(() => {
accounts._expireTokens();
accounts._expirePasswordResetTokens();
accounts._expirePasswordEnrollTokens();
}, EXPIRE_TOKENS_INTERVAL_MS);
};
I’ve proved this code is the culprit by changing EXPIRE_TOKENS_INTERVAL_MS to 15 minutes instead of 10 minutes and the spikes change accordingly.
To see how long this code is taking and how many tokens are removed I modified the code to:
const setExpireTokensInterval = accounts => {
accounts.expireTokenInterval = Meteor.setInterval(() => {
const a0 = new Date().valueOf();
const r1 = accounts._expireTokens(); // I've hacked this to return the number of records updated
const a1 = new Date().valueOf();
const r2 = accounts._expirePasswordResetTokens(); // I've hacked this to return the number of records updated
const a2 = new Date().valueOf();
const r3 = accounts._expirePasswordEnrollTokens(); // I've hacked this to return the number of records updated
const a3 = new Date().valueOf();
console.log('expire tokens:', a1-a0, a2-a1, a3-a2, 'total='+(a3-a0), 'removed:', r1, r2, r3);
}, EXPIRE_TOKENS_INTERVAL_MS);
};
This gives the following output:
20T22:48:37 expire tokens: 2825 447 1268 total=4540 removed: 0 0 0
20T22:58:38 expire tokens: 2572 630 2109 total=5311 removed: 0 0 0
20T23:08:37 expire tokens: 2810 1461 387 total=4658 removed: 0 0 0
20T23:18:36 expire tokens: 2132 784 519 total=3435 removed: 0 0 0
20T23:28:36 expire tokens: 2322 694 471 total=3487 removed: 0 0 0
20T23:38:36 expire tokens: 2280 1354 384 total=4018 removed: 0 0 0
...
Why is this taking so long even though no tokens are being deleted - I’ve seen some instances up to 7 seconds?! The execution time seems to increase during the afternoon (US time) when demand is highest
accounts._expireTokens() seems to be the worst offender of the three.
My users collection only contains 946 users, and 407 of these contain “services.resume.loginTokens.when”, but none of those tokens are over 90 days old. However, most of them contain multiple loginTokens.
When I run a similar query direct in the mongo shell using .explain("executionTime") it takes only a couple of milliseconds and seems to be using an index.
I guess my questions are:
- Why are these queries taking so long?
- Since no records are being updated, it can’t be to do with the Oplog or an observer on the users collection, could it?
- Is the reported execution time the actual time taken for the query, or is the
this.users.update()running asynchronously so other stuff might be happening in another fiber at the same time? - Would there be any downside to pushing
EXPIRE_TOKENS_INTERVAL_MSout to an hour or once a day?
Thanks!

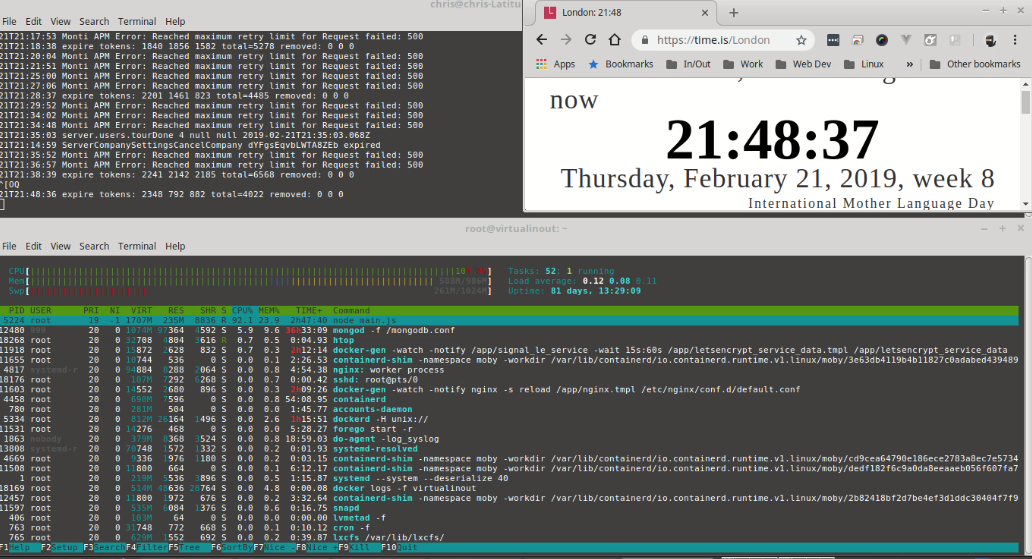
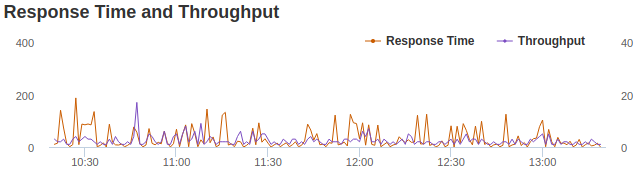
 . I’ll report back when I’ve had time to try that, may not be for a couple of days… I could also test different Meteor releases too.
. I’ll report back when I’ve had time to try that, may not be for a couple of days… I could also test different Meteor releases too.