I made it because I need it, but can be useful to someone too: npm module (CLI) extracts schema from Mongo database into .json or .html (open output html in browser and it will render ER model).
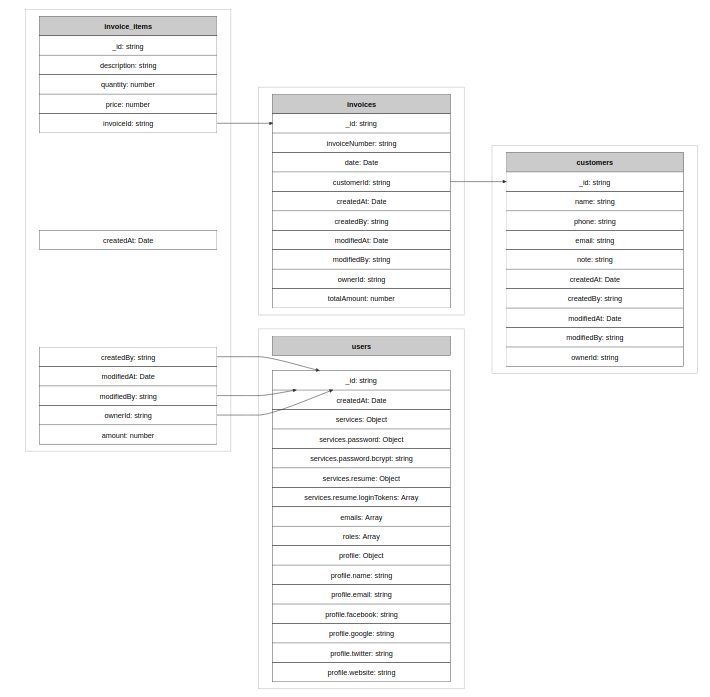
Example output (screenshot of resulting html rendered in browser) :
extract-mongo-schema -d “mongodb://localhost/test” -o schema.html -f html-diagram
=> fail. “mongodb://localhost/test” is a connection path actually used
---------- log:
Extract schema from Mongo database (including foreign keys)
Extracting…
TypeError: Cannot read property ‘function’ of undefined
at getDocSchema (C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\extract-mongo-schema.js:41:31)
at getDocSchema (C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\extract-mongo-schema.js:59:5)
at C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\extract-mongo-schema.js:111:4
at Array.map (native)
at C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\extract-mongo-schema.js:110:8
at Array.map (native)
at getSchema (C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\extract-mongo-schema.js:100:18)
at printSchema (C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\extract-mongo-schema.js:125:16)
at C:\Users\Administrator\AppData\Roaming\npm\node_modules\extract-mongo-schema\node_modules\wait.for\waitfor.js:15:31
Some table name is not displayed in html. (body is displayed though. viewing source, everything is ok)
Hi @diaconutheodor thanks. How it works? Very simple - get value of randomId and searches all collections trying to find that value in their _id fields.
That is so smart. , must it end with Id or does it apply to all strings ? Or does it try to identify if the field looks like an id ? Does it do this for all documents ? Or just for the first one that it finds with that pattern, and learns from it ?
Script reads 100 documents from each collection and makes statistics for fields (the same field can be string or number or whatever in the same collection). Most frequent type is choosen. If field value “looks like” id (and is not already marked as foreign key) program searches all collections for that id. (for each of 100 documents where field looks like id until it is confirmed “foreign key”)
=>
The number of documents in tasks collection is not so large, but over 100.
Presumably, this seems to be relevant to the cause.
Looked into error lines of code.(but as expected, this gave no specific clue)
Q: …But we are facing cursor timeout kind of problems.
A: Instead of using a cursor over the entire collection you can try paging through the collection by the _id.
So each time query for 100 documents (order by _id) and keep the last _id you encounter.
Then on each consecutive query use a condition to fetch documents where _id > last _id from previous fetch.
 , must it end with Id or does it apply to all strings ? Or does it try to identify if the field looks like an id ? Does it do this for all documents ? Or just for the first one that it finds with that pattern, and learns from it ?
, must it end with Id or does it apply to all strings ? Or does it try to identify if the field looks like an id ? Does it do this for all documents ? Or just for the first one that it finds with that pattern, and learns from it ?