There are plenty of things to be excited about here. See this list for advantages of FDB over Mongo. Also, I believe since the Document Layer is just a stateless layer, the data behind it could could be queried in other ways e.g. as keys and values, giving us possibilities that Mongo doesn’t.
We should investigate to see what advantages like better performance FDB could provide.
Currently, FDB doesn’t have an Oplog since it doesn’t need it itself, however they are talking about adding one.
It would be especially great if it could provide us with this ability: https://jira.mongodb.org/browse/SERVER-31720 - “get a notification when a document stops being matched by a query”. That could give meteor apps a huge performance boost.
That should be no problem since MiniMongo runs on the client, and just cares that it is populated with documents from the server.
There could be a possible issue if you wrote a method that you expected to run identically on server and client, but that used a feature that worked differently on FDB. I don’t know what cases of that there might be. This is similar to the current situation anyway since MiniMongo doesn’t implement the whole MongoDB API identically either.
This is really cool - thanks for sharing. Never heard of it before. Seems like a very robust database that is easy to scale.
Concerning oplog, use redis-oplog - who uses regular oplog anymore
Minimongo is independent of the sever-side dB. As long as livequery can get data out of the dB, you are good to go (you can even use other DBs such as MySQL for example server side and publish to minimongo)
RedisOplog is a temporary solution until ChangeStreams comes to the mongodb node driver. […] reality is that once Notifications API comes to life, that is it, that is the way to go.
Unfortunately, the current Change Stream API in MongoDB isn’t as suitable for this purpose as it first seemed, as you can read in the rest of that thread, and in the JIRA link in my original post.
Redis-oplog also isn’t so suitable in cases involving querying of arbitrary fields which is something I’m personally doing (letting users define queries).
A proper Change Stream API, if we got one from either MDB or FDB would be magic for meteor performance.
Redis-oplog works really well @gunn and has made huge difference in scalability and cost.
All the big prod apps using meteor (that we know of, including ours) uses it.
The only thing is you need to have at least one redis-server instance running (on AWS use elaticache)
@antoninadert, @diaconutheodor, Yes I agree that the current MongoDB Change Stream API isn’t useful, and that redis-oplog is. That’s what I meant in my second sentence.
It’s also why I’m hopeful about a “proper” API for this, either from Foundation DB, or MongoDB in the future.
That’s my understanding from what you say here about FLS / filter, limit, skip queries.
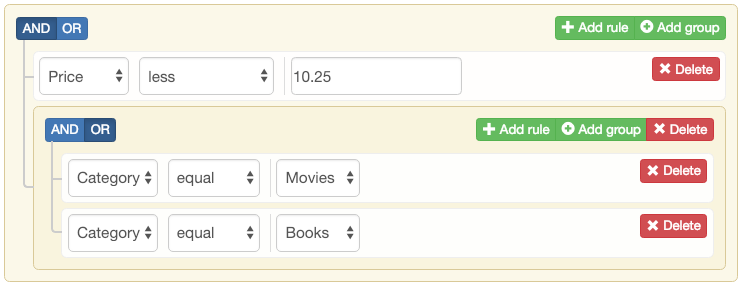
In my case I want to let users define queries either directly with code, or through an interface like this:
Why would RedisOplog stop you from doing that ? How did you come to this conclusion ? When you subscribe to a publication you can pass your own custom filters however you wish.
I said not so suitable. I got this impression from the GH thread where you said:
Given a publication for collection “users” that contains some filters, limit and optionally skip options.
In order to make sure that the image on the client is the correct one we have to listen to all updates inserts and removes on “users” collection. Given the scenario that “users” collection changes a lot, the watcher from Redis is still going to be bombarded.
Did I misunderstand?
Regardless, the wider situation seems clear: redis-oplog is currently the best option, but improved support at the database level could let us do even better.
LFS queries are always hard to make efficient. But with RedisOplog you could still concentrate them on a specific namespace. Give the full docs a read, everything will be much clearer.
 - who uses regular oplog anymore
- who uses regular oplog anymore