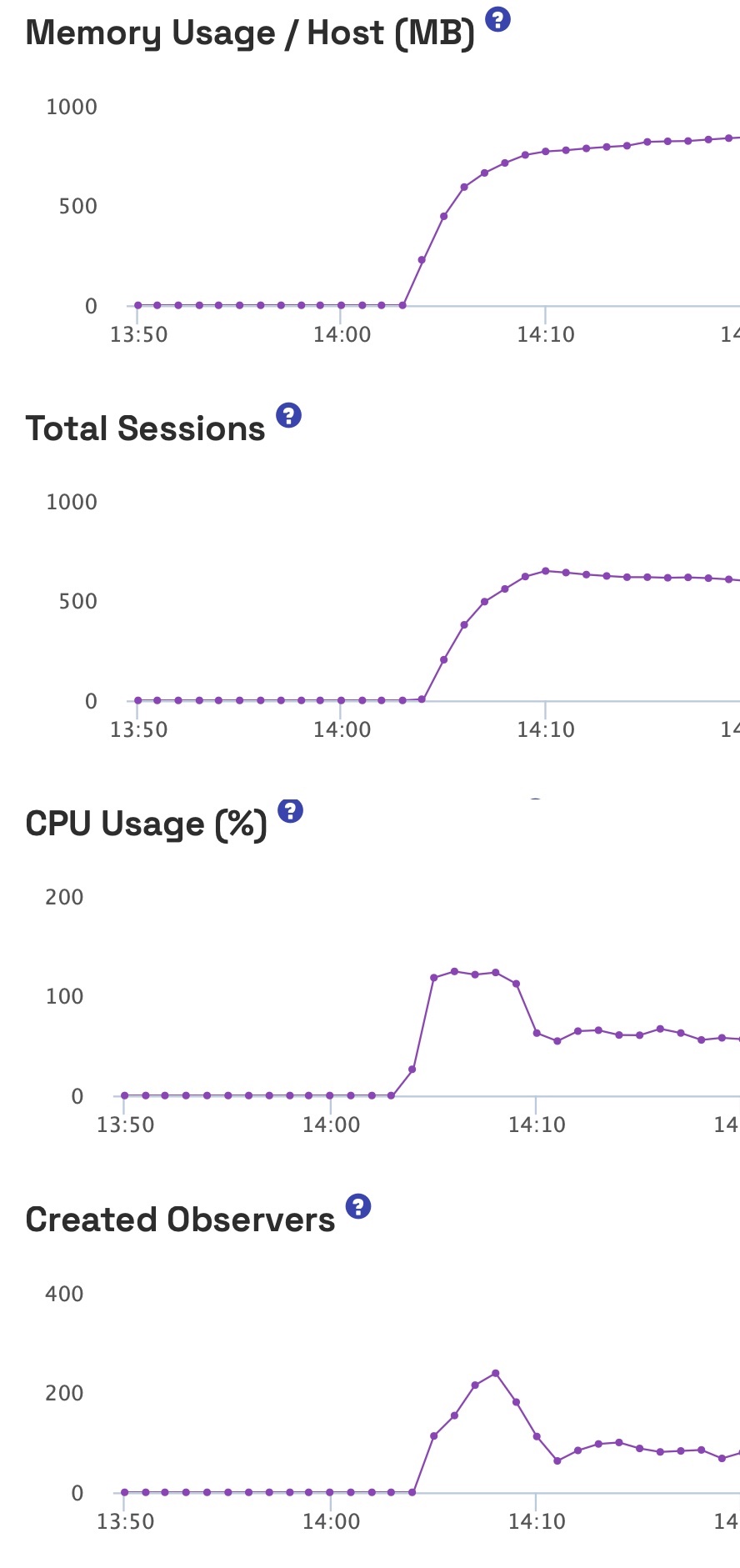
We’ve been using Galaxy since the beginning… and we have always had this problem. We are curious if any others folks have this problem and found a workaround.
The attached picture is what happens midday… off peak… when a new container starts up. It loads, gets 100% of new connections (b/c that is what Galaxy load balancer does) and the container thrashes for several minutes and the response times get crazy and all connections on that server are sluggish.
To mitigate, when we upscale, we add 10 servers at a single time. But during off-peak, here, Galaxy is “replacing the machine” to help with their cost pooling. So this means they killed a single container and started a single container.
So, to be super clear on the question: How are other apps handling cold-start containers that get flooded during start up? Is there app code that we are running that other folks aren’t? (we don’t think so), or is this just a problem that all meteor apps have? Is the only solution for Galaxy to have a “warm up” phase where they don’t send 100% of all new connections to a brand new container?
As we discussed in the past via tickets I believe the only option would be the warm up phase where Galaxy doesn’t load all the containers equally.
Galaxy team would need to keep the machines for longer and new containers should start to receive connections slowly.
Another approach would be to use smaller machines so the containers are more spread but in this case the amount of connections could still overload a specific container.
By nature Meteor apps are going to be intense when the connections are moved to another container so I don’t think this is a Meteor problem but just a characteristic.
Disclaimer: I’m no longer in the Meteor team but I used to discuss scaling issues with Eric very often when I was. The same with many other clients so I know this is a pain for others as well.
FWIW, I don’t think it’s a Galaxy thing because I’m on AWS Fargate and I have the exact same issue.
It seems to be mostly a result of all the subscriptions I’m using. I’ve pared them down to a minimum but in my case I still require subscriptions to publications with many thousands of rows, which bogs down the server when a bunch of new users are added at once.
I did some load testing to see how impacted different container sizes would be by a certain number of new users being switched over to a new instance. Keep in mind this is for my app, so YMMV (and will I’m sure).
New users
Delay on 0.5 vCPU
Delay on 1 vCPU
25
6s
4s
50
12s
8s
100
20s
13s
Went down a long rabbit hole of trying to come up with solutions like gradually moving sessions from the old server(s) to the new one(s), but no such solutions are doable with AWS. There’s an old Github issue for Fargate about having a warm-up period where CPU max is greatly increased, but it’s years old and unlikely to happen.
I’ve been reading about Redis Oplog and am hopeful that implementing that might make a difference with these cold start times, but I’m not sure if that’s actually true.
My workaround thus far has been to massively overprovision both the number of servers and the CPU count. This works… but it’s a big waste of money, as 99% of the time there are way too many servers that are each too large.
This strikes me as an opportunity for Galaxy to differentiate – if they could build a slow-start/gradual-rollover feature, it would mean that someone in my case could potentially save quite a bit of money by switching to Galaxy.
This is a mostly off topic reply to Banjerluke. Thanks for commenting. I hope my reply helps you too.
Redis oplog is a game-changer. You will start to notice the win at 5 containers and up. At about 30 containers, you need it or you cannot reasonably scale. Without redis, each new container spends the majority of its time ignoring updates that are not relevant to it. Redis does NOT help start up time.
We now only use 3 subscriptions at start up. (and only a few others sparingly) 2 of the 3 are required by meteor. (meteor.loginServiceConfig, meteor_autoupdate_clientVersions, userData)
We use Galaxy Triggers to auto-scale up. This means we can run very few containers off peak. We use the wall clock to trigger the first bump before peak, and then load triggers during peak. We add 11 containers during each increment. 11 is a bit overkill, but they get saturated reasonably quickly, and then we grab the next 11. Why 11? We tried 3 and 5, but during our peak time, users are just coming too fast, so we kept tweaking. Also, during 2020, when covid broke the internet, I think AWS had backlog provisioning machines. We would ask Galaxy for 11 containers, and sometimes it would only give us 8, and we’d have to wait up to 10 minutes before the last 3 dribbled out.
We currently do NOT use Galaxy triggers to down scale. They have some little bug in their counter which gets confused during deployment. So, when we push a new update, sometimes the triggers start downscaling, which is the worst time to downscale. So, we use their api to monitor and downscale ourselves. We could upscale this way (and indeed we used to), but their trigger is more robust than our externally connected bot and upscale is mission-critical whereas downscale is not.
Have a question, thought this thread could be a fit.
We’re rolling our own containerized deployment system for our app with Amazon ECS. It’s going good so far. Does anyone know how smooth rolling deploys is achieved when deploying new containers to replace old containers when a new version of your app is deployed? Similar to how Galaxy does where the Session is maintained? These seems like this logic would be above the app in the container orchestration layer.
Right. In thinking about it, the only state we really need is a user being logged in. In our use-case at least, it’s fine for them to reload and thus re-pub/sub, re-Method to load data, etc. We just don’t want them to have to log in again. Which they shouldn’t have to if the resume.loginToken in their browser matches up to the database.
One worry though, is we currently use Meteor’s Reload._onMigrate function to show a notification that allows the user to refresh when they’re ready. This works great in Galaxy. But I’m betting they have custom logic (which they mention right here in this AWS Invent video about the Galaxy implementation). In raw ECS, Reload._onMigrate probably isn’t going to work as the user is just moved to the new container and the app is loaded and hopefully their login resumes.
So an unannounced hard refresh upon deploying a new version is maybe the most we can hope for in raw ECS?
One concern is a client trying to load files from both servers running the old version and from servers running the new version. Enabling sticky sessions usually prevents this. One additional thing Galaxy does is provide a way for it to work correctly with cloud front since it could try to load an asset from a server running the wrong version. Some apps that use cloud front without Galaxy work around this by having cloud front load the files from s3.
We’re using containers and not using MUP. So we’re building a new app image using Disney’s meteor-base package. Uploading it to S3. Then updating ECS to revise the tasks with the latest app images. Which does something similar to Galaxy. Launches new containers then moves user to them from the old containers.
We do use Cloudfront for the bundle. I assume once a client is moved it would only connect to the new container.
This is why I worried that Reload._onMigrate wouldn’t run. From my understanding this runs when a newer version of the server is detected. But in a new container/old container scenario how/when does a client on an existing container know that a new container is being created and it will be moved to it? Like what ECS event triggers this? The old container stopping? How does it know a new container is available. I assumed Galaxy filled in the blanks with this with custom logic.
Reload._onMIgrate runs when it detects a new version of the client. The server creates a hash of the client files, and the client watches for when the hash changes from when it first loaded. There is nothing galaxy-specific with this.
It doesn’t know when it will be moved - the server (when using GitHub - meteor/ddp-graceful-shutdown) or the load balancer disconnects the client, or it is suddenly disconnected when the container is stopped. When it tries to re-connect, the load balancer connects it to a different container - usually a new one but that would depend on the load balancing strategy and how rolling deploy was implemented.
If the new server it is connected to has a different hash for the client files, it runs the hot code push process, including running Reload._onMigrate.
Requests made directly to the app would, but requests made through cloud front could connect to any of the servers. Galaxy works around this by having the app add the app version to the bundle url so it can send the request to the correct container (CDN | Galaxy Docs). mup-cloud-front works similarly by storing the assets in s3, with a different path for each version, and using the version in the URL.
We use Cloudfront to serve our application JS bundle, CSS, and all assets in the public folder like images, sound effects, etc.
All of the above have a version number appended to the URL (e.g. https://cloudfront_url/asset_url&_g_app_v_=version). So once the client is connecting to a new container with an updated version on the CloudFront URL to every asset, doesn’t that bust the Cloudfront cache for a given asset (e.g. the JS app bundle)?
Then once the client has a new JS app bundle, the sticky session (or even just the application load balancer) would keep it connecting the new/same container.
So I don’t understand how “requests made through CloudFront could connect to any of the servers.” If a client connects to a new container, all of it’s CloudFront requests would be to cache-refreshed assets.
BTW, we are now finding that Reload._onMigrate works as intended.
When cloud front doesn’t have a file cached, it requests it from the server (unless you have it configured to get the file from s3). The requests from cloud front to the app servers wouldn’t have the same sticky session as the client, so it could be sent to any of the servers, including an old server that doesn’t have the new asset.The g_app_v query parameter is galaxy specific.
I made the assumption that during the rolling deploy there would be both servers running the old and the new version at the same time so new requests could still go to an old server. That is the most common method for rolling deploys, but some aws services have other options.
Right, but CloudFront would be requesting an asset from the app because of a new deployment. Otherwise none of this is an issue. So a client gets moved (because a new container is ready), it reloads the app, hits CloudFront for whatever, and if CloudFront doesn’t have the cached asset, it requests it from the actual app, which I assume would go to a new container due to the ALB.
I guess if CloudFront is “connected” to an old container and it’s stickied to it, then it could reach out to an old container. I’m honestly not sure what CloudFront’s connectivity state/stickiness is. It seems like if CloudFront had a bunch of assets cached for some time then it would lose its connection/stickiness to the app, then it receives an updated URL with a new version query parameter, it would make a new request to get that asset and thus be routed to a new container because the ALB is rolling out a new deployment.
Yes and no. Yes, this comes from our original Galaxy setup. Now we’re migrating from Galaxy. So we’re just leaving that query parameter name as-is but giving it a value of APP_VERSION which is an internal version number we update on every deployment. Because our CloudFront is set to include ALL query strings in its keys, simply passing a new value here to any query parameter will bust the cache. Same thing Galaxy does I assume. It’s not the query parameter name that’s important. It’s that on a new version deployment, a new, unique version number gets appended to every request from CloudFront for all assets. So they’re always busted on a new deployment.
Yes, but only existing, non-moved sessions should connect to previous old/containers. Once a session is moved or is a new session, during the deployment process, I believe it would only connect to a newly deployed container. If there’s no newly deployed containers yet, then the session wouldn’t have moved yet so it would be fine to still connect to old containers.
It seems we both are making different assumptions on how the deployment process works.
If you use blue/green deployments with the All-at-once option, I think your comment would be mostly true. The other deployment strategies ECS provides would send some requests to the old servers, which could include requests from cloud flare.
@evolross
You have just deployed a new version. Client loads and … “Miss from cloudfront” on first load. I was looking for this version: ?meteor_js_resource=true&app_v_=581.0.0 but this version has never been pulled from Cloudfront before. This is the first time.
At this point, Cloudfront goes to the origin (1. Meteor v581, 2. Meteor v580, 3. Meteor v580) and tries to get v581 but hits the seconds server which has no version 581. Your client gets nothing…
After the first hit, your Cloudfront has the v581 bundle. All calls for it are being satisfied from Cloudfront (Hit from Cloudfront) until the maximum age of cacheing. When expired the first client loading the app triggers a new pull by Cloudfront from the Meteor origin (RefreshHit).
" I guess if CloudFront is “connected” to an old container and it’s stickied to it, then it could reach out to an old container."
I don’t think CloudFront uses stickiness of any kind. It just connects to an origin if it lacks an asset.
You can have Miss, Hit and RefreshHit
“RefreshHit from cloudfront: CloudFront found the object in the cache, but its age has passed defined TTL, so CloudFront revalidated its freshness with origin . Revalidate was successful and CloudFront refreshed the age of this object.”