I am currently hosting our small meteor application on a basic VPS (2 vCores, 2.4 GHZ, 4 GB RAM).
It hosts both Meteor and MongoDB. And performance wise it works fine, but we currently also just have at max 3 concurrent users.
We want to slowly move some steps ahead and wanted to move Meteor to Galaxy Cloud and Mongo to Atlas.
But unfortunately the application got unbearingly slow. The starting screen is a dashboard, which shows recent docs and some counts. On the VPS it takes 2 sec max if an user has lots of related docs. On Galaxy it takes 10 secs and more.
I am using APM to try to identify the culprit and this is what I found:
I am using publish-composite to get some documents related to an user.
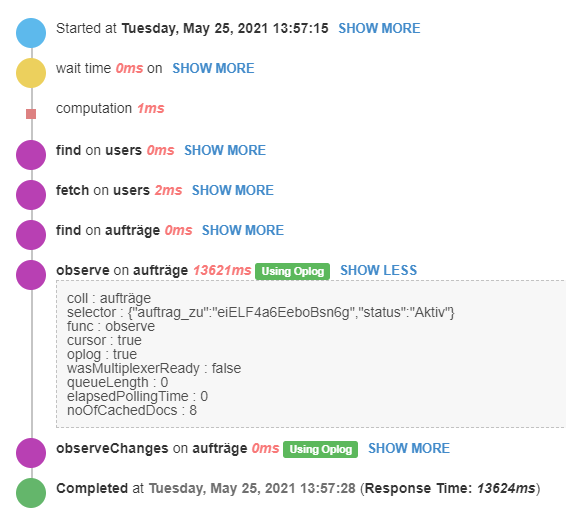
This is the publication:
return {
find() {
if (!this.userId) return
else {
return Aufträge.find({status:"Aktiv", auftrag_zu: this.userId})
}
},
children: [
{
find(auftrag) {
return Collection1.find({auftrag_id: auftrag._id})
},
children: [
{
find(col1, auftrag) {
return Collection2.find({_id: col1.col2_id}, {vorname: 1, name: 1, arbeitgeber: 1})
},
children: [
{
find(col2, col1, auftrag){
return Collection3.find({'meta.id': col2._id}).cursor // Meteor Files Collection
}
}
]
}
]
}
]
}
It usually finds up to 10 parents, up to 100 children per parent, 1 grandchild per child and 1 grandgrandchild per grandchild.
What could be the reason that the observe step for this publication takes 13621ms? Where could I start finding the root cause for that?
When I remove the children this publication is fast again. Is this just a limitation of publish-composite? Is there a better way to do this? Why does it work fine on the VPS?
This is the APM Dashboard:
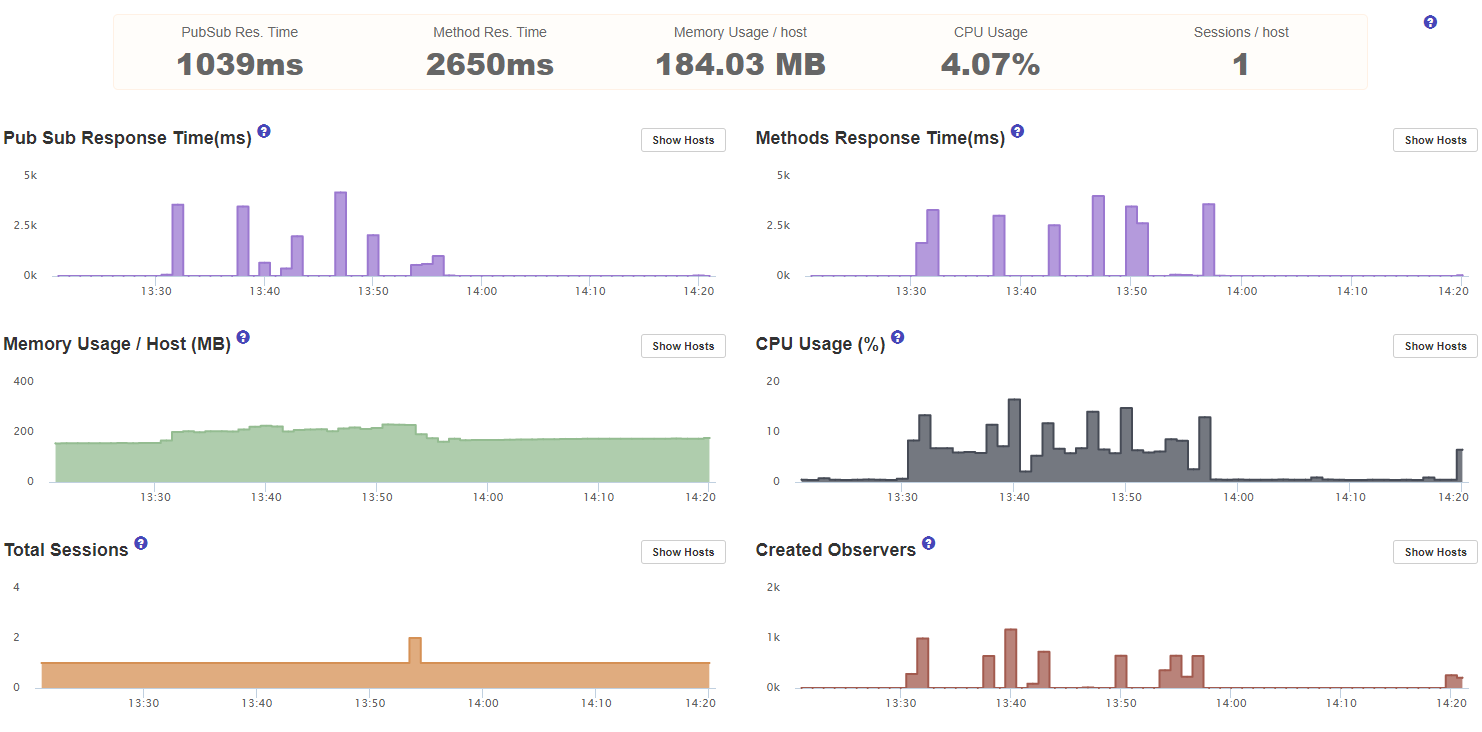
Upgrading the container helps, but the cpu usage maxes out at about 1.5ghz.
Enabling/disabling Oplog doesnt do anything.
Upgrading Mongo Atlas to a dedicated cluster didnt do anything.
Any help would be greatly appreciated
 .
.


