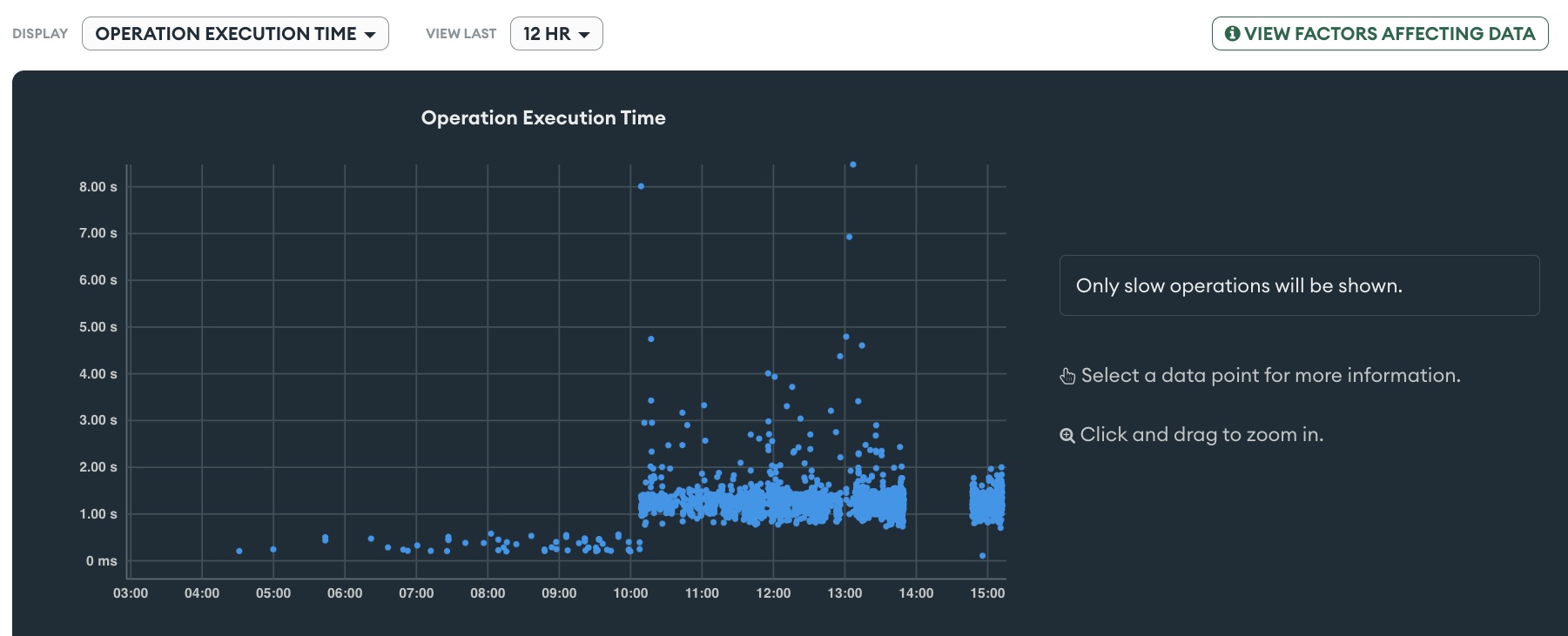
Our DB is on Atlas it it’s been always kept between at 10-15% CPU usage. As soon as we have one node process running Meteor 1.9.1 that has users connected to it, the CPU averages at 35-40% with peaks at 60-80% (never seen before).
I have not found any ticket or post regarding this. Has anyone else experienced this ?
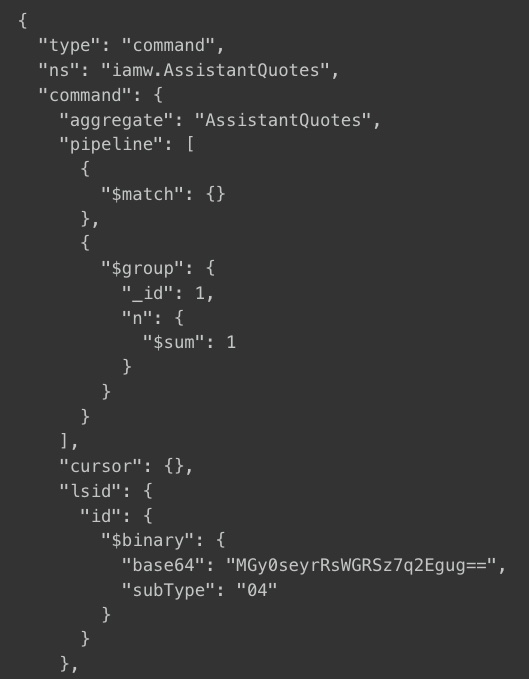
As soon as we restarted one of our node processes, Mongo started to receive “aggregates” queries from Meteor on a collection we have never used aggregates.
So it seems the mongo driver is doing something that is translated into an aggregate ?
Since those are slow, well, the CPU spikes a lot.
Same issue here, since we migrate from 2.7.3 to 2.9.1, we got a lots of slow collscan queries (same kind as burni13, queries using aggregate)
I rolled back to 2.7.3 four hours ago, and no more collscan
collection.find().count() has a similar performance as collection.find().fetch() wherein the db has to go through the entire cursor to count the results.