How can Meteor position itself for the LLM age?
Hey everyone,
Over the past few weeks I’ve been noticing scattered conversations across GitHub, the forums, and the broader dev ecosystem about Meteor and AI. Each thread touches on a different angle, but together they start to paint a bigger picture: ** How can Meteor position itself for the LLM age?**
This post is an attempt to gather everything in one place, spark a broader discussion, and hopefully turn some of these loose threads into a real direction for the framework.
What we already have
llms.txt , AI-ready documentation
The Meteor docs ship with an llms.txt file following the llmstxt.org convention by @grubba . You can download the full docs as a single text file (curl https://docs.meteor.com/llms-full.txt) and use it with any LLM tool, LM Studio, Claude, whatever you prefer. A small but important step that makes Meteor a first-class citizen in AI-assisted development workflows.
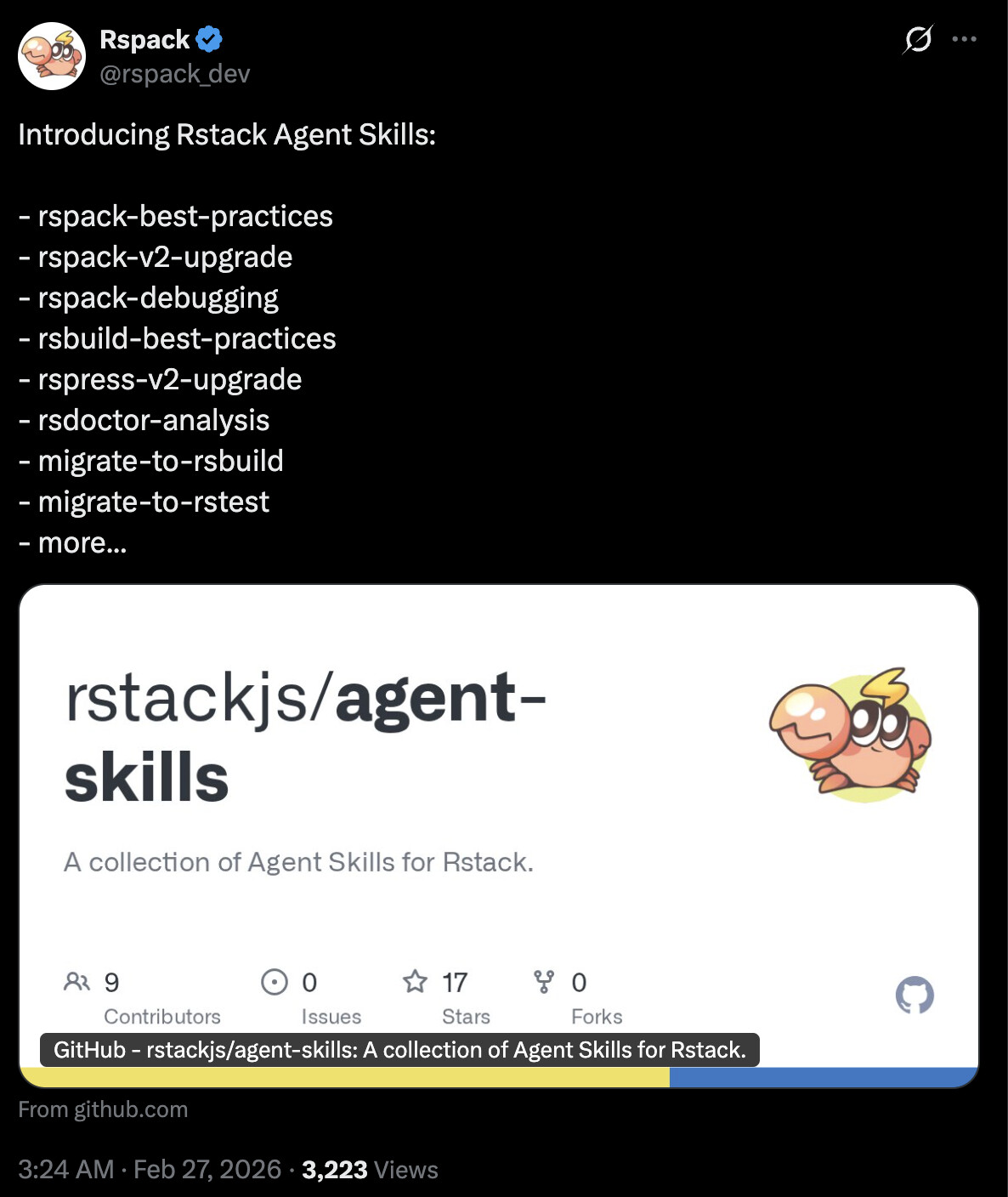
Cross-platform AI agent context for the Meteor source (PR #14116)
Merged in February 2026, @nachocodoner adds a structured AGENTS.md / CLAUDE.md documentation to the Meteor repo itself, so AI coding assistants can understand the codebase when contributing to Meteor core. The approach is token-efficient: a small root file loaded on every request, with a set of skill files under .github/skills/ that agents load on demand depending on the task (testing, build system, conventions, etc.). A great pattern that could also be adopted by Meteor app projects.
The conversations happening right now
Meteor needs server-to-client streaming , especially for AI (Forums)
In the Meteor 3.5-beta thread about Change Streams, an important piece of feedback was raised by @msavin : Meteor is still missing a clean, first-class way to stream data from server to client. The commenter explicitly calls this out as critical for AI use cases, since every major AI service now streams its results token by token. You can work around it today using WebApp, but there’s no neat solution with Meteor.user(), permissions, and subscriptions all playing nicely together. This is a real gap.
Meteor could be much more , and WebMCP is part of that (GitHub Discussions #13818)
In a broader discussion about Meteor’s future, the idea came up that making any Meteor server MCP-capable by default could be a genuine differentiator in the LLM era. One interesting angle by @dchafiz : Chrome’s recent introduction of WebMCP , an in-browser MCP implementation , could allow Meteor Methods to become natively discoverable by AI agents without any extra setup. If Meteor shipped WebMCP support out of the box, with certain methods auto-discoverable, it could be a compelling story for building agentic web apps.
Building an MCP for Meteor (Forums)
@dchafiz is already building meteor-mcp , an MCP server designed specifically for Meteor apps development, providing complete Meteor.js v3 API docs, code examples, and architectural guides to AI coding assistants like Claude, Cursor, and Windsurf. It’s a community-driven effort aimed at making Meteor the go-to choice for vibe-coders. Worth watching and contributing to.
The idea: make any Meteor server an MCP server by default
A specific proposal I land in the discussions: what if meteor run gave you an MCP server out of the box? Certain Methods could be auto-discoverable by AI agents, turning every Meteor app into something that LLMs can interact with natively. There’s healthy debate about whether MCP is the right protocol right now vs well-documented REST/DDP, but the underlying idea , that Meteor could be LLM-native by default , feels worth exploring seriously.
Agent instructions by default on project creation (Forums)
Motia, another framework shared by @paulishca , now generates an AGENTS.md file automatically when you scaffold a new project, making every new project AI-agent-ready out of the box. The question for us: should meteor create do the same? Shipping a sensible default AGENTS.md with every new Meteor project , with correct Meteor 3 patterns, async/await usage, and links to the llms.txt , would directly address the version confusion problem and be a low-effort, high-signal move.
What other frameworks are doing around AI
It’s useful to look at what the rest of the ecosystem is building to understand where the gaps are and where Meteor could leapfrog.
Vercel has built a TypeScript toolkit specifically for integrating LLMs into apps , standardizing text generation, structured output, tool calling, and streaming across providers like OpenAI, Anthropic, and Google. The SDK includes AI SDK UI, a set of framework-agnostic hooks for building chat interfaces and generative UIs with real-time streaming out of the box. It works with Next.js, SvelteKit, Nuxt, Svelte, and others. Notably absent from the getting-started guides: Meteor. This is a gap we could fill with a community integration.
LLM-first Web Framework (Minko Gechev)
A thought-provoking post from an Angular core team member exploring what a framework designed from the ground up for LLMs would look like. The key insight: LLMs perform best with opinionated, minimal APIs , a single way to do things, less surface area to “learn”. He also highlights two core problems that affect all frameworks today: API version mismatch (LLMs generating code for outdated versions) and lack of training data for newer patterns. Meteor has both of these challenges. His proposed solution , including full framework context in the LLM context window , is essentially what our llms.txt and AGENTS.md work is already doing.
Vinext: Agent Skills for framework migration (Cloudflare)
Cloudflare built Vinext , a full reimplementation of the Next.js API surface on Vite, built by one engineer with AI in a week. What’s most relevant for us is the migration pattern they introduced: Vinext ships with an Agent Skill that any AI coding tool can install with npx skills add cloudflare/vinext. The skill understands the compatibility surface, handles dependency changes and config generation, and flags what needs manual attention , all inside your existing AI coding assistant (Claude Code, Cursor, Copilot, etc.). This pattern could be exactly what Meteor needs for the v2 → v3 migration path. Imagine npx skills add meteor/migrate-to-v3. The tooling exists today.
Thesys React SDK , Generative UI
Thesys is building a React SDK that turns LLM responses into live, interactive user interfaces in real time , no copy-paste, no dev server restart, no manual wiring. They call this “Generative UI”: an interface that assembles itself dynamically based on LLM output, rendered on the spot. It’s an early but important signal that the frontend layer itself is becoming AI-driven, and frameworks need to support streaming, reactive state, and real-time UI updates natively to play in this space. Meteor’s reactivity model is arguably a better fit for this than Next.js, if we build the right bridges.
Thoughts?
Would love to hear thoughts , especially on the streaming gap, the migration skill idea, and the WebMCP angle. Who’s working on what, and where should we focus first…