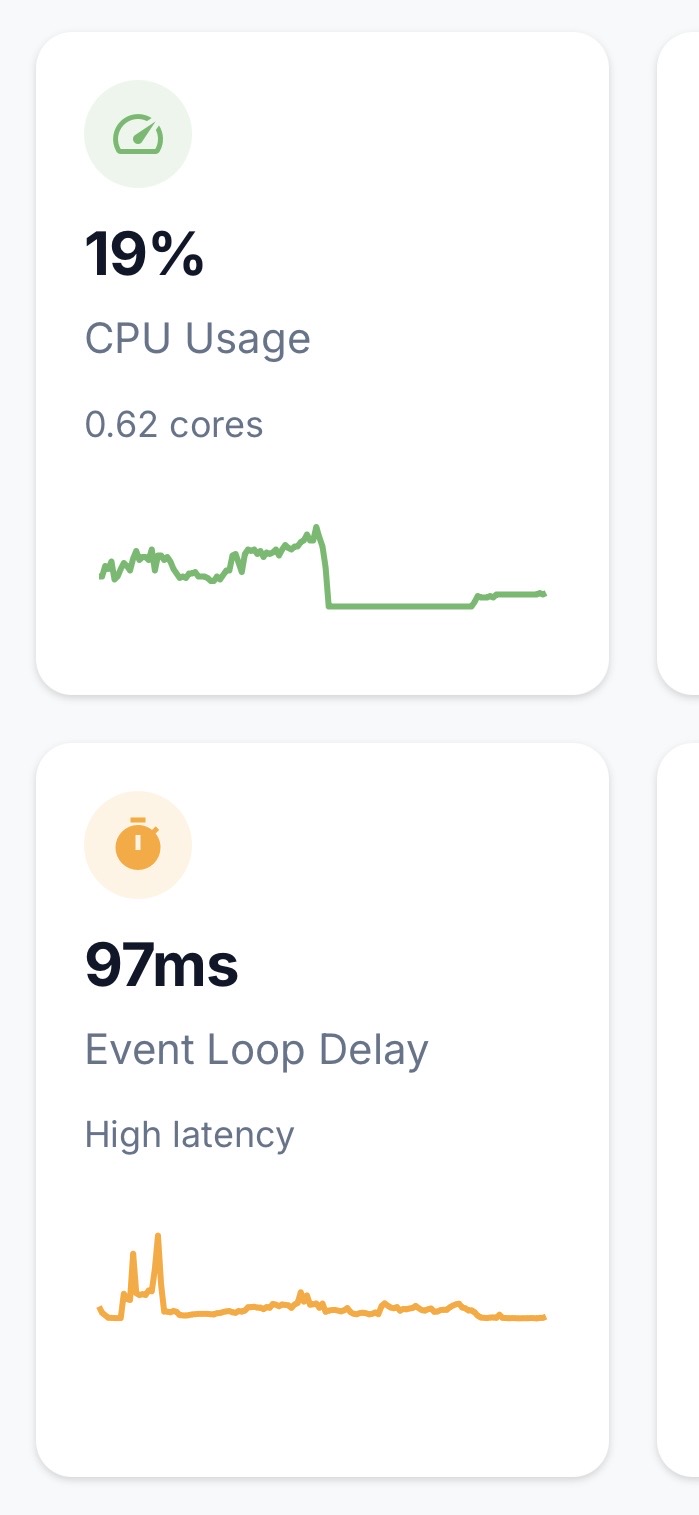
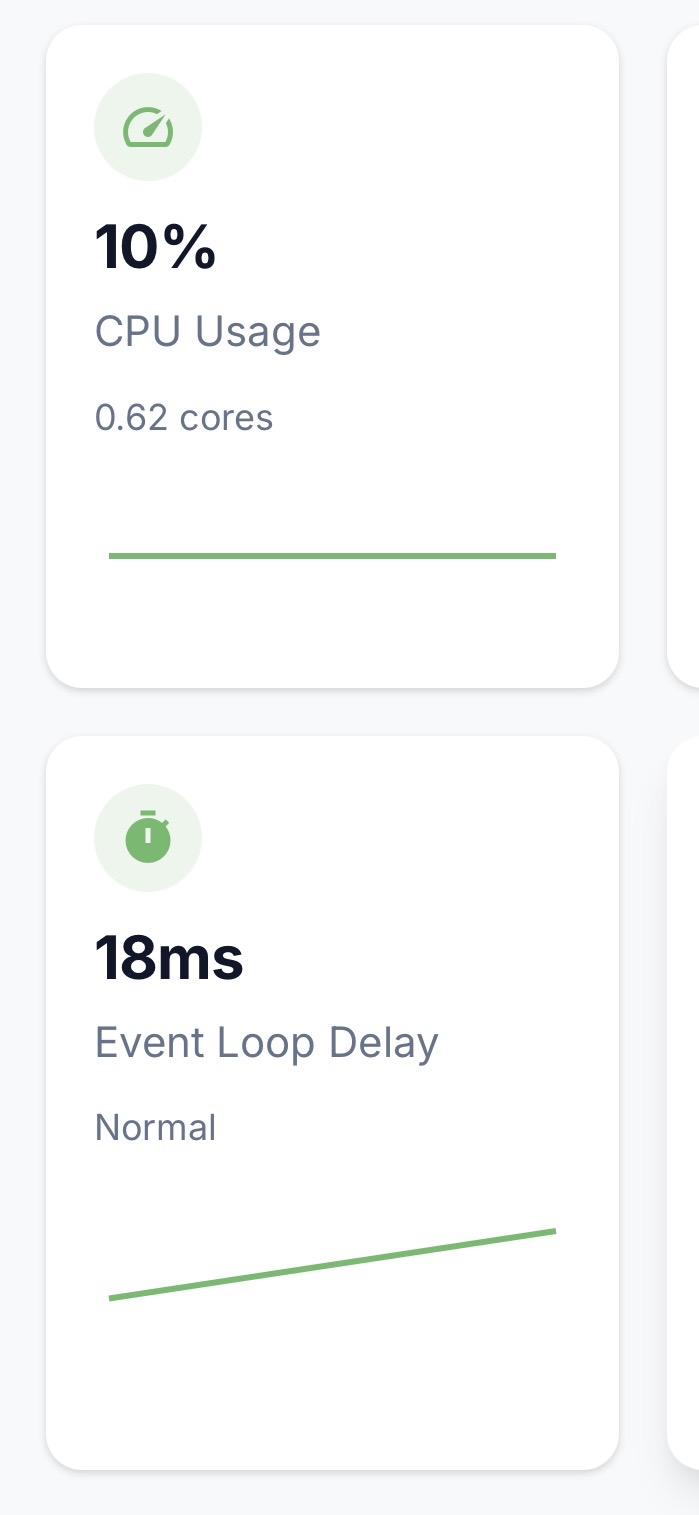
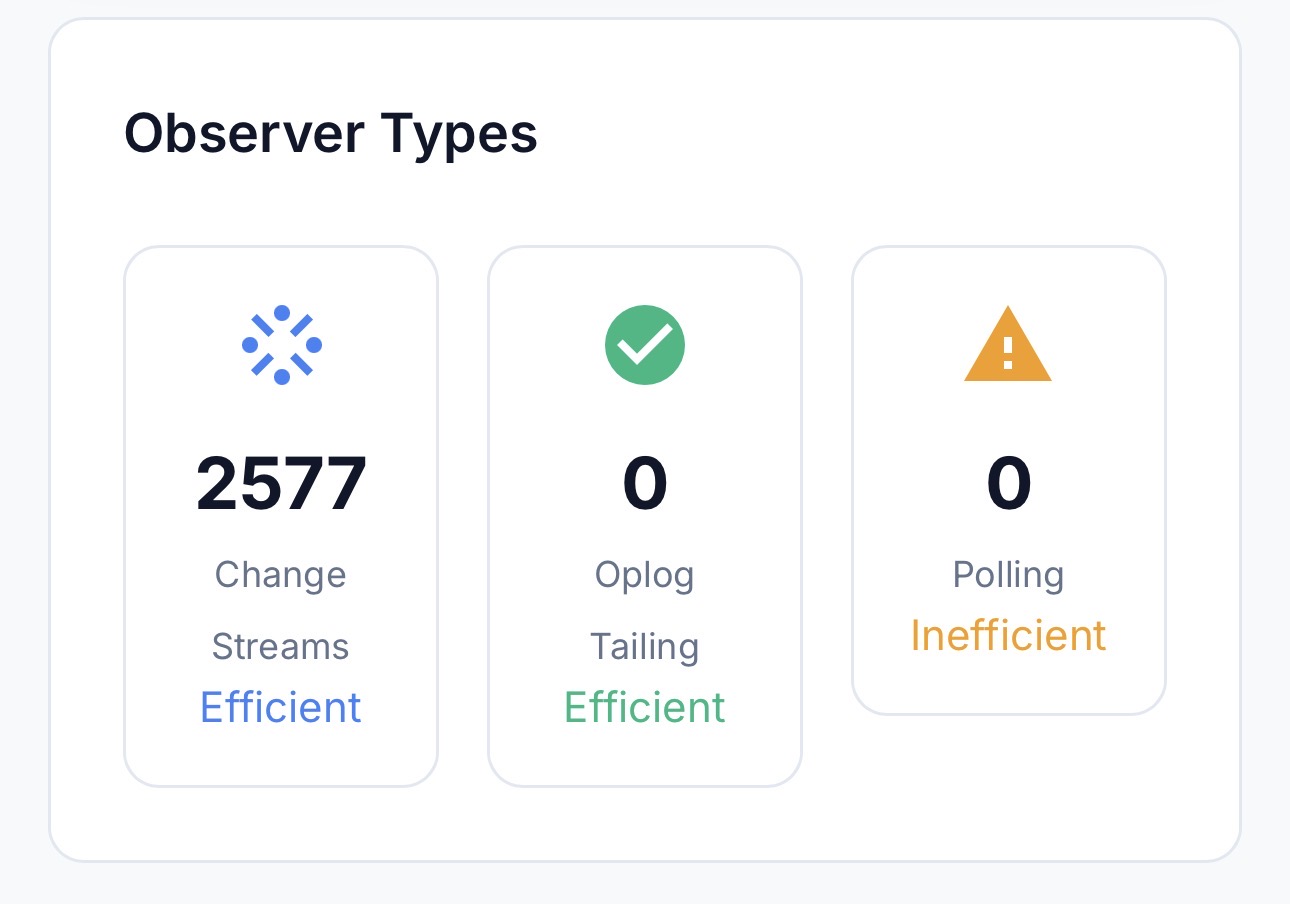
Not for each query but for each oberver, when we do a find in a publication, we do not return the result directly, we return an oberverDriver, the observeDriver is the responsable to watch(via polling, oplog or cs) the query and magically send the data to client
So it’s 1 CS per publication(observer) per connection
Following my benchmark, I opened approximately 800 parallel connections, each with its own change stream, on Galaxy. Are you able to share a benchmark from your application? I’m curious to see how it behaves under those conditions.
using change stream you dont need to care about hot collection affecting your meteor app performance.
Today you can do it but I guess it isnt documented
1. Per cursor
collection.find(selector, {
pollingIntervalMs: 5000, // default: 10,000ms (10s)
pollingThrottleMs: 100 // default: 50ms
});
pollingIntervalMs — how often the query is re-executed to detect changespollingThrottleMs — minimum time between re-polls (increasing saves CPU/mongo load, decreasing is not recommended)
2. Environment variables
METEOR_POLLING_INTERVAL_MS=5000
METEOR_POLLING_THROTTLE_MS=100
Apply server-wide defaults when not specified on the cursor.
while I was diving into the code to bring the pollingInterval feaure, i just find a disableOplog flag, following it I can implement that for changeStream as well, covering your request to enalble it per cursor
Meteor.publish("currentRoom", function (roomName) {
return Rooms.find(
{ name: roomName },
{
disableOplog: true,
pollingIntervalMs: 5000,
pollingThrottleMs: 5000,
}
);
});
disableOplog should be documented via jsdocs but for somereason it isnt in our published docs, i’ll investigate why