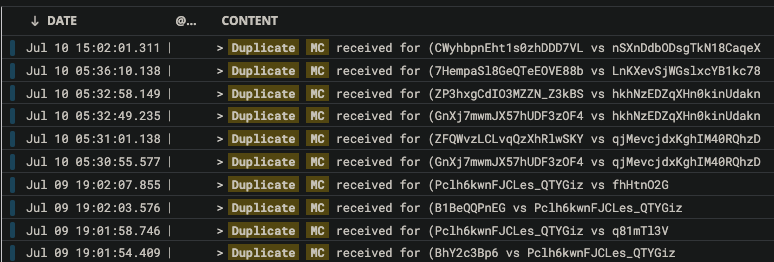
We have a problem with a remote.call being executed twice in as little as 2ms (based on timestamp in backend log file).
The difference is so little (largest example below is 9ms) that our prevention method (sending a randomId with it and persisting it into a doc, thus if it exists its firing twice) is failing
do {
// lot's of code including a setTimeout delay function of a couple of seconds
// send to BE
await remotePromise('triggerIBDComparison', kitUser, userId, cardId, kit1, kit2, ibdObj, isTrial, Math.random());
} while (comparison !== null);
WriteConflict in MongoDb caused by this RC firing twice (in this case with 9ms difference):
No, not this specific function (you mean the remote call, right?).
We only have used debounce for one click event which is used very often. I didn’t think that this remote call could actually fire multiple times but as we’re using throttling already in this do … while loop (which calls the RC) I thought we’re safe.
I guess this is the “Method retry” problem. From the Meteor Guide:
If you call a Method from the client, and the user’s Internet connection disconnects before the result is received, Meteor assumes that the Method didn’t actually run. When the connection is re-established, the Method call will be sent again. This means that, in certain situations, Methods can be sent more than once. This should only happen very rarely, but in the case where an extra Method call could have negative consequences it is worth putting in extra effort to ensure that Methods are idempotent - that is, calling them multiple times doesn’t result in additional changes to the database.
Many Method operations are idempotent by default. Inserts will throw an error if they happen twice because the generated ID will conflict. Removes on collections won’t do anything the second time, and most update operators like $set will have the same result if run again. The only places you need to worry about code running twice are MongoDB update operators that stack, like $inc and $push , and calls to external APIs.
The solution in your case appears to be either to check whether the document already exists before attempting to create it, or to specifically ignore that kind of error.
we do have this in place but like I wrote it doesn’t help in identifying twice in 2ms. Problem is that we don’t have any in-memory store at the backend that we can use for this type of problem (at the frontend we can use Session Vars for it).
It’s also strange that Meteor thinks that in less than 2ms there is a disconnect and fires again.
It does more harm than good as we’re using transactions and there are even more use cases (other than the one described in the guide) which trigger a WriteConflict in MongoDb.
Luckily, we’re not a bank. Imagine that each Method call would be a transaction and people would “lose” too much money becomes sometimes it transfers twice (which just recently happened in a local bank here in Singapore, was quite the shit show).
IMO this “functionality” should be tweaked and rather have a much longer “grace period” before it retries.
I do agree that the phenomenon is very strange, esp. firing the Method for a second time after just 2ms, so it’s entirely unclear why that is happening. I guess all we can do is to mitigate the problem in our code once that happens.
As for an in-memory store, I use js-cache in my app on the server side, and it works very well. You can assign a TTL to each entry so you don’t need to worry about the store growing excessively.
This looks like a great solution where I could replace my MongoDb collection (called MethodCalls, I wonder why LOL) with this in-memory solution. It will reduce stress on the MongoDb server and improve overall speed at the backend.
I’m also using a TTL so the fact that js-cache has it makes it even better!
The only caveat is that if you have multiple Meteor server instances, each will have their own js-cache, so theoretically conflicts could still occur (or not, depending on your use case). If that turns out to be a problem, a shared redis db, which quite handily also comes with TTL, would be a possible solution.
I’ve come to the conclusion that this isn’t a problem of our code on the frontend. So debounce won’t help us there. It’s Meteor core (as per Peter’s reference) that is retrying way too early.
I’m still getting duplicate firing of the remote.call but now the difference is 1ms and even 0ms. Yes, the log shows that they both reached our backend at the same time.
So unless that core behavior is changed and fixed (I guess most of you don’t even know that it fires regularly twice because it does no harm other than creating an unnecessary workload) the only way to handle this is at the Method call at the backend.
I’m currently still working with persisting with two methods to a collection with a TTL but will now try additionally to use a in-memory store to save it there without any latency.
It’s really a big problem for any Production app that relies on getting only a single firing method call
Interesting. We recently noticed something possibly related in our app, although the difference in time was more like 100 or 200 ms each time IIRC. We have noRetry: true on all our methods so it’s definitely not the loss of the connection (which probably wouldn’t be possibly anyway - not sure what the timeout is for regarding the connection as lost and then reestablished).
Ours happened mostly twice but in one occasion we saw it fire three times in a row. @a4xrbj1 - Are you able to reliably reproduce this somehow?
Unfortunately not, Mark. It seems like random and at first we thought that the users had found a trick to bypass all our restrictions and clicked the card twice (we use a Bootstrap card to identify information and when the user clicks a certain type of card it triggers this remote call/method call).
But it happened even to my own account today.
I’ve posted the code in my original post and so far I haven’t heard from anyone that something is wrong with it.
The reason why no duplicate firing is happening above the 1 ms is because of all the countermeasures we have in our code. Eg. we’re sending a random number as one of the parameters and check at the backend if that random number is the same.
Yeah, we have almost identical code to yours at the root of our problem too. How often are you seeing it? We’ve seen it very little (like 5 or 6 times in total) but that’s not to say it’s not happening more. If only we could figure out how to repro it
If you see the same random number in your logs multiple times for consecutive method invocations, I can’t think of any other explanation than Meteor itself firing the same invocation more than once. The trick with the random number parameter is a great idea, so you can be dead sure it’s not your front-end code itself that invokes the method multiple times.
// lot's of code including a setTimeout delay function of a couple of seconds
We’re talking about several functions and over 100 lines of code. So no, it’s not called multiple times fast in succession. It’s one of the main functions on our frontend.
This is the backend code and it’s working well for years (except when the doc isn’t persisted yet from the previous call, which happens on these 0-3 ms repeat calls:
Just to be sure that we are covering everything, I am not sure how setTimeout matters in that code. Can you explain further?
Let us say that the function will loop 3 times as an example.
If the method call is outside the setTimeout, the method call will be immediately called consecutively 3 times without consideration to the setTimeout.
If the method call is inside the setTimeout, the method call will be immediately called 3 times in succession after 2 minutes.
Can you enlighten me how the setTimeout affects this discussion?