I’ve run into a problem where memory usage starts increasing nonstop as soon as I load the index page. Using Chrome DevTools I can see that when I start the server, the memory is fine sitting at around 90MB. However as soon as I load the site at http://127.0.0.1:3000/, the memory usage starts increasing to the node heap limit (which I’ve increased to 8GB) and it crashes.
To confirm this isn’t an issue specific to my app, I spun up a fresh meteor app, and populated the db when the server started inside Meteor.startup like so:
for (let i = 0; i < 1000000; i++) {
TasksCollection.insert({
'test': '1231aoidwjdoiajwdoiajwd oaijdo awidja owidj aowidj aowidjaowidj aowidj aowidj aowidj aowij'.repeat(10)
})
}
Indeed I saw the same behavior. Memory was fine until I load the web page and it shot up to 1.8GB.
Can anyone provide insight as to why Meteor behaves like this and what I can do to prevent this? It seems unlikely the framework was be designed without this level of db traffic in mind. Thanks!
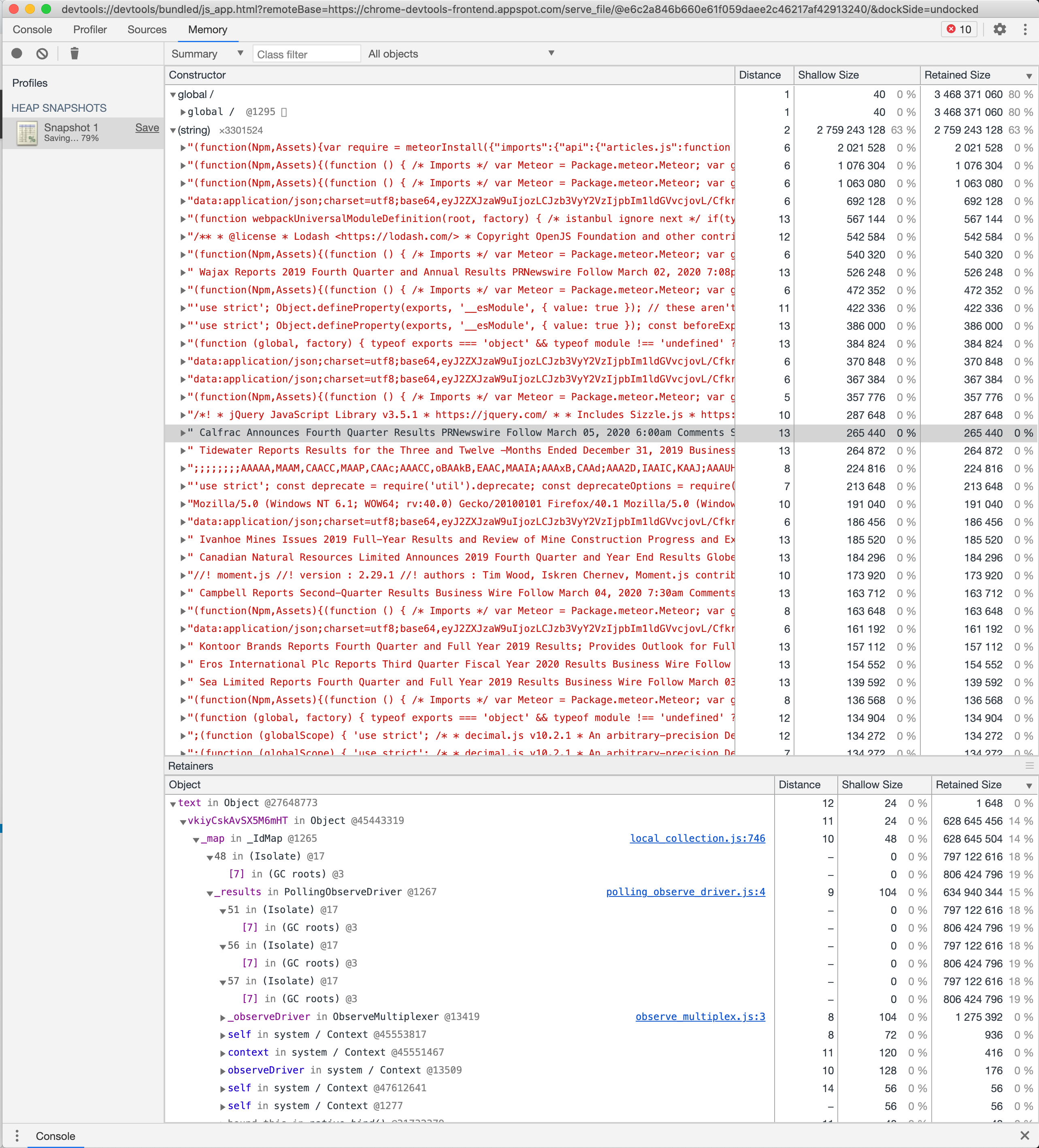
If it helps, this is from a snapshot of the heap, these strings are articles that my app processed in the past (not on this particular load) and you can see they’re getting loaded from some _IdMap object that rolls up to something called PollingObserverDriver then ObserverMultiplexer
 .
.