I just added the first Spacedojo guest post to the blog. It covers how reactive data will be changing in 1.3.
Big thanks to @devan for working on this!
I just added the first Spacedojo guest post to the blog. It covers how reactive data will be changing in 1.3.
Big thanks to @devan for working on this!
Thanks for posting this, @joshowens & @devan!
It would be nice to see MDG take a stand on this and it sounds like going in the direction of TrackerReact would be a good idea…
Thanks for the feedback. I sure hope @tmeasday reads it, but I have a feeling they’ve already picked another direction based on some docs I saw. Sadly a weird copy of react-komposer, not sure the point of reinventing that particular package…
Our implementation is basically just slightly different syntax to komposer, but built on ReactMeteorData.
However it’d be simple to reimplement building off komposer in the future (in fact this has already been done as a first pass: https://github.com/meteor/todos/blob/a0ae5d1019ab7f378d6d2912a45f8cf9b955bd11/imports/ui/helpers/create-container-with-komposer.js)
The reasoning for using ReactMeteorData is simply that ReactMeteorData has been out in the wild and used by lots of people for a while now. It’s not perfect but seems to work pretty well.
Using HOC to inject data dependencies is a pretty standard pattern in React these days, and in fact the same pattern that we recommend for all view layers.
I wasn’t really disputing the use of HOC, the article from the post shows off how to do that with TrackerReact. My issue is that use plain JS to render the HOC is less easy for people to grasp imo. Having already taught a class that shows both Tracker-React and React-Komposer, I can tell you that people seemed to get the concepts must faster with Tracker-React. I also find it feels more natural to see those calls in JSX vs a JS container file that is returning a bunch of stuff…
Just my $0.02.
I’d also be curious to measure out the difference between the Tracker computation rerunning for all the data you need a container to pass on vs having smaller Tracker computations running for individual data you care about updating…
Just want to note that I resurrected TrackerReact because it puts you closer to the metal of setting up your own “smart” container. Experiencing first hand the marriage of meteor with react while understanding what’s going on.
I am not sure why so many wrapper libraries exist. Seriously, how many smart containers does one need?
I.e. @tmeasday in your meteor todos example in react you have 15 jsx components/files. Of which there are just 2 “smart components”
AppContainer.jsxListContainer.jsxthose, nonetheless, require an additional helper create-container.jsx to just compose two other components App.jsx and ListPage.jsx?
I mean, this is a crazy way of showing someone the benefits that meteor brings to react. No?
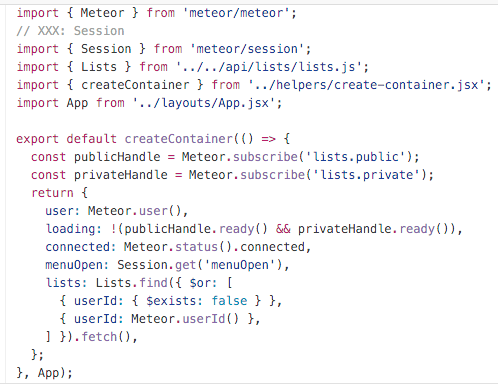
###VS
I use this as a recruiting tool in the hiring process to probe a candidate. Those mostly experienced with react/angular of how well he/she manages to learn from code and instrument value out of react (the view layer) with meteor (the data layer). Building features.
As a result, they often build compositions themself. Best practice. But then I know they understood what meteor does and do not think meteor needs - or is - some magic scaffolding.
Getting state from the outside into react is one of the biggest pain-points. Showcasing minimongo and tracker as a lightweight state machine is eye-opening… but instead we abstract the light bulb away…
I would like to re-visit this when we are close to 1.3 release for the guide. Right now this part is written for people who know (a little bit of) react and meteor. Not for the outer JS community for which the full flux stack is just too much for small/medium sized projects.
This helper is just coming from the react-meteor-data package (I’ll publish a beta soon!). Think of it replacing the ReactMeteorData mixin. So expect to see that create-container.jsx file to disappear from the app very soon. Does that help the added complexity here?
I think it has been expressed many times elsewhere but I’ll say it again here. There is a very good reason why we did not go in the TrackerReact direction. Experience and best practice says that it’s not a good idea to couple your view layer and data layer if you can help it.
One of the key benefits of React is that you can reliably reason about how a component renders based on it’s props and state. Having tracker-based changes randomly (for all intents and purposes) cause a component to re-render makes it difficult to debug and hard to reason about. This is one of the key learnings from Blaze that I think most folks would agree with.
As nice as it is when you get started, there’s just too much magic in this kind of approach, IMO.
I’ve only built very simple apps using Meteor and React and I was already bitten by using a TrackerReact-like approach because I started putting too much interesting stuff in render. Plus, it’s very very clear that the React community has agreed on container functions as the way to go.
@tmeasday am not really sure where this was expressed elsewhere. But TrackerReact is an overhaul proposal of getMeteorData - a practice wise outdated mixin - and not a proposal of best practice.
The Example is for showcasing its functionality. So please don’t over read this part:
As of using TrackerReact, you don’t put reactive data sources next to html and other components, you follow best practice and return one single component in which you pass reactive data sources down as props. It’s best practice. A practice that anyone can reason about after they understood the role of meteor in that context.
Rendering
As of re-rendering, you should check MeteorGetData. It re-runs all the time. @faceyspacey elaborated that in an older thread a while ago; also regarding Trackers quirks. TrackerReact runs once. That’s it.
There is also no mix of the view and data layer. Meteor provides reactive states that change while the component is rendered. Wrapping all that away under a “getMethod” that is de facto not a getter - to than return its value under a data property - instead of simply using class methods is pretty far away from flux. It is not even maping to state like you would in redux. To me it looks like a prototypical approach (getMeteorData) carried over on accident without being revisited.
Comprehensabilty, than Best Practice
Because after all it boils down to this: I report that TrackerReact seems to let experienced developers grasp much quicker the value proposition of meteor for react and replicate best practice with it. @joshowens, running space dojo, reports newbies understand more quickly what’s going on between meteor and react. Searching through the forum for TrackerReact and looking at the response of the past it seems quite a few people seem to feel more comfortable to see a plain connection between meteor and react.
So my question is: Where is this resistance coming from?
To revisit getMeteorData is clearly useful before the 1.3 release and was asked for with its first emergence. The abandonment of mixins is also a good excuse to really check its appropriateness.
So My goal is not to push TrackerReact as primary adoption but to have a discussion about a very transparent, low level implementation of getMeteorData that is as easily understood as TrackerReact. With that, one can build abstractions and follow best practices. Also in the guide. But not the other way around.
Right now: Just build a container creator with TrackerReact and you have both. Best practice and great reasoning what’s going on.
-> I am excited to see the react-meteor-data demo. But we need an easy no-scaffold/wrapper implementation to onboard people. Would love to chat with you about my experiences one time.
I feel like you are saying you didn’t follow a pattern and therefore we need to figure out a way to strictly enforce that pattern so others don’t make the same mistakes you did?
It looks like the Redux community has agreed on container functions, but an HOC doesn’t have to be a function to work. My issue here is that getMeteorData ties all your reactive sources into one big autorun that will rerun any time 1 reactive source changes for a container. Seems expensive and unnecessary.
One more data point is Relay. I think Reflux does it as well? Do you have any examples of popular React data libraries that don’t use a function for the container? It would be interesting to see what they look like.
Apologies @dinos, but I’m not sure I’m following everything you are saying, so excuse me if I mis-represent you / miss something.
I guess it depends on which people you mean. I’d contend that existing React developers would not find the createContainer syntax confusing or hard to understand, because it agrees with the patterns of the majority of current React data handling libraries.
If people want to use TrackerReact and not clearly separate the action of Tracker and the re-rendering of components, then go for it! But I don’t feel like we should recommend it in the guide as it feels like an anti-pattern, especially from the perspective of React’s philosophies (as I outlined above).
This is a reasonable objection. I’ll just briefly note that komposer has this same limitation.
Of course this is the way Blaze works. Do you have an example at hand that we could discuss wrt this?
Hopefully I’m not hijacking the thread here, but…
@tmeasday - I can’t seem to use createContainer , even in Meteor 1.3 RC2. Is there something special I have to do?
Try meteor add react-meteor-data@0.2.6-beta.16
I put up some examples at http://container-efficiency.meteor.com/ (until Friday :)) to illustrate what @joshowens is talking about (source code here). The effect is obvious just by playing with it but there is timing info in the console if desired.
It illustrates the UI impact of lumping all reactivity into a single autorun vs
isolating them like we did in Blaze.
In the sample, there are two reactive functions, one that’s “fast” (50ms) and
one thats “slow” (500ms).
Blaze: incrementing either takes 50ms or 500ms, respectively.
CreateContainer: incrementing either takes 550ms, the sum of both.
TrackerReact: I expected this to be different but I might have
misunderstood how it’s meant to work. Same as above.
GadiContainer: Works more like Blaze, read on…
I wanted to show that there’s really no reason we can’t do this better in React
so I made a super quick example, obviously it’s nothing fancy.
I also prefer the HOC pattern, so just modified it slightly like this: (the pattern resembles how the blaze, etc versions are created too.
So the container func is no longer reactive (which I think is safer), but
it can provide functions in a reactive key, which are run reactively
in isolation. Obviously any number of alternative patterns are possible.
The super simple code is here.
I feel like the answer is that 500 ms functions don’t belong in your UI components. Those should be handled in a separate module and cached.
Haha, you’re right, of course… this was an extreme example for illustration purposes. The point is just, is it a good pattern to rerun every reactive function each time any one of them gets invalidated? Should developers be responsible for implementing their own caching layer when using multiple reactive functions?
Obviously if it’s a reactiveVar get() there’s almost no overhead. But a mongo fetch() is more expensive and the developer may well have further processing on the data after retrieval. These kinds of things definitely add up on mobile.
Well, just quickly, I did not check your implementation, but that is the reason why I implemented TrackerReact Profiler (shelved until the release of Meteor 1.3) but just check this “animation”.

However, can be I am not sure if you’re testing reactivity to screen.
But as sashko said - if you have 500ms functions, you need to UI decouple and inject them asynchronously.
Seems there’s more involved in using createContainer:
Error: Can’t find npm module ‘react-addons-pure-render-mixin’. Did you forget to call ‘Npm.depends’ in package.js within the ‘modules-runtime’ package?
