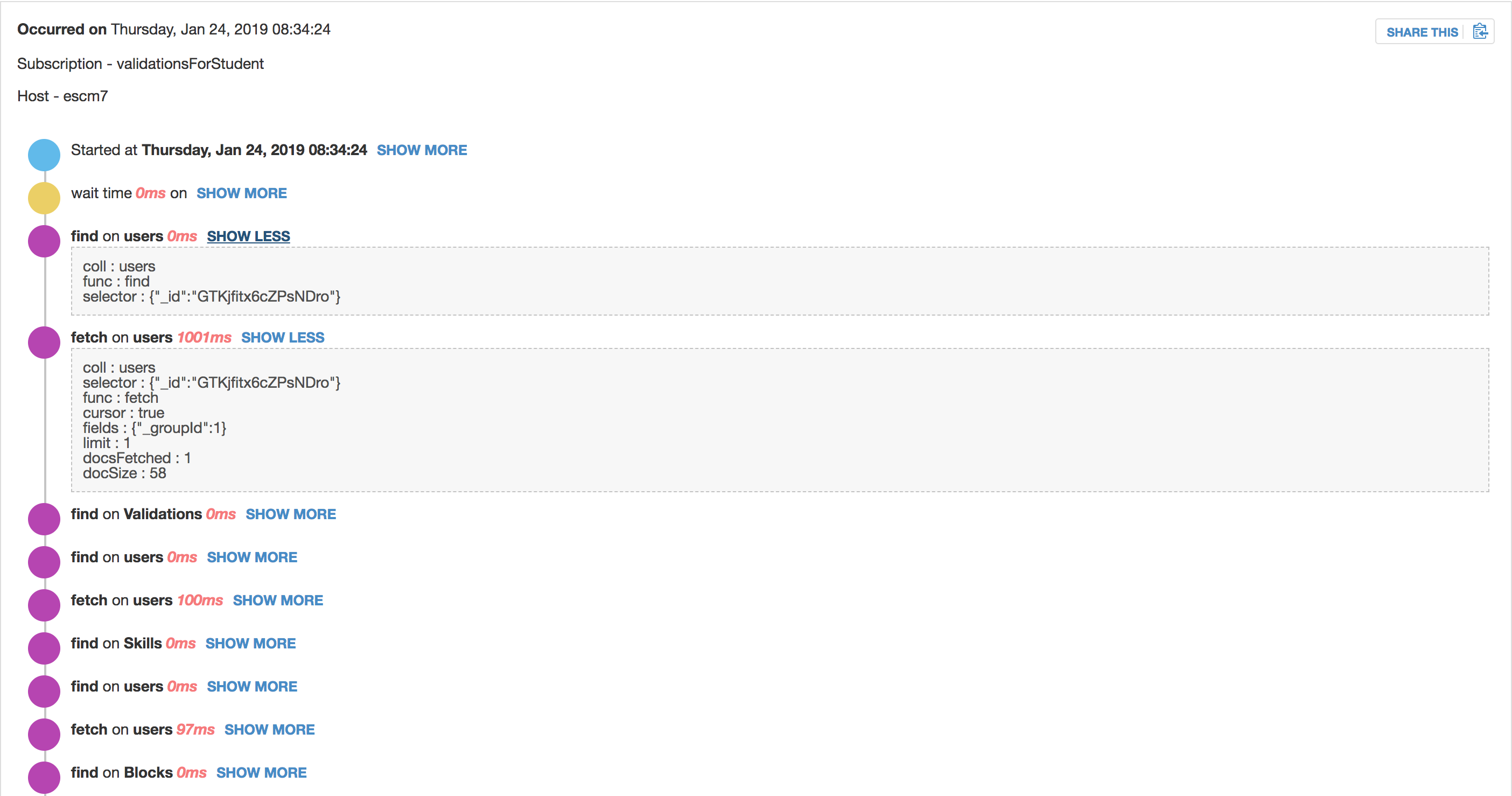
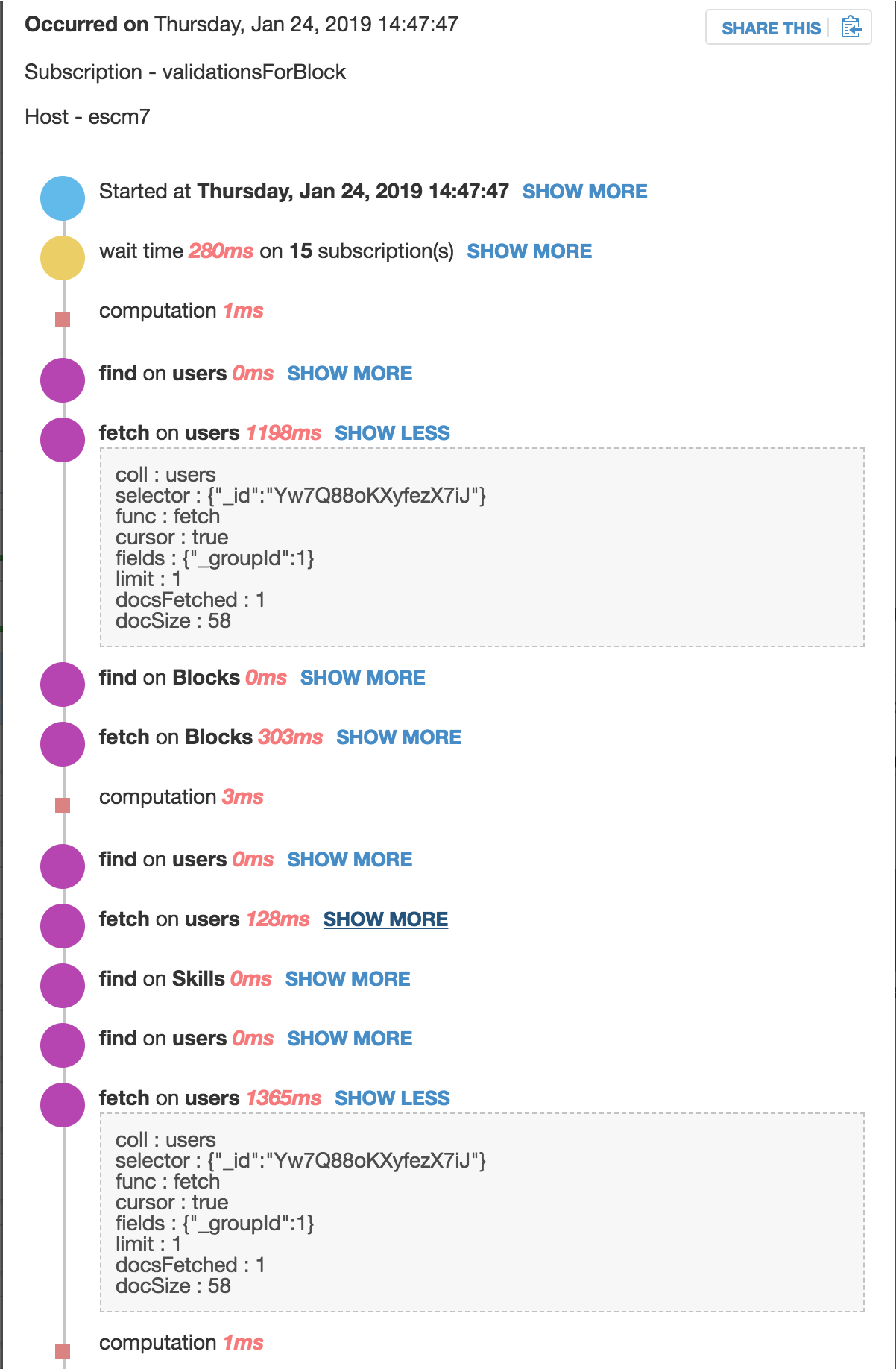
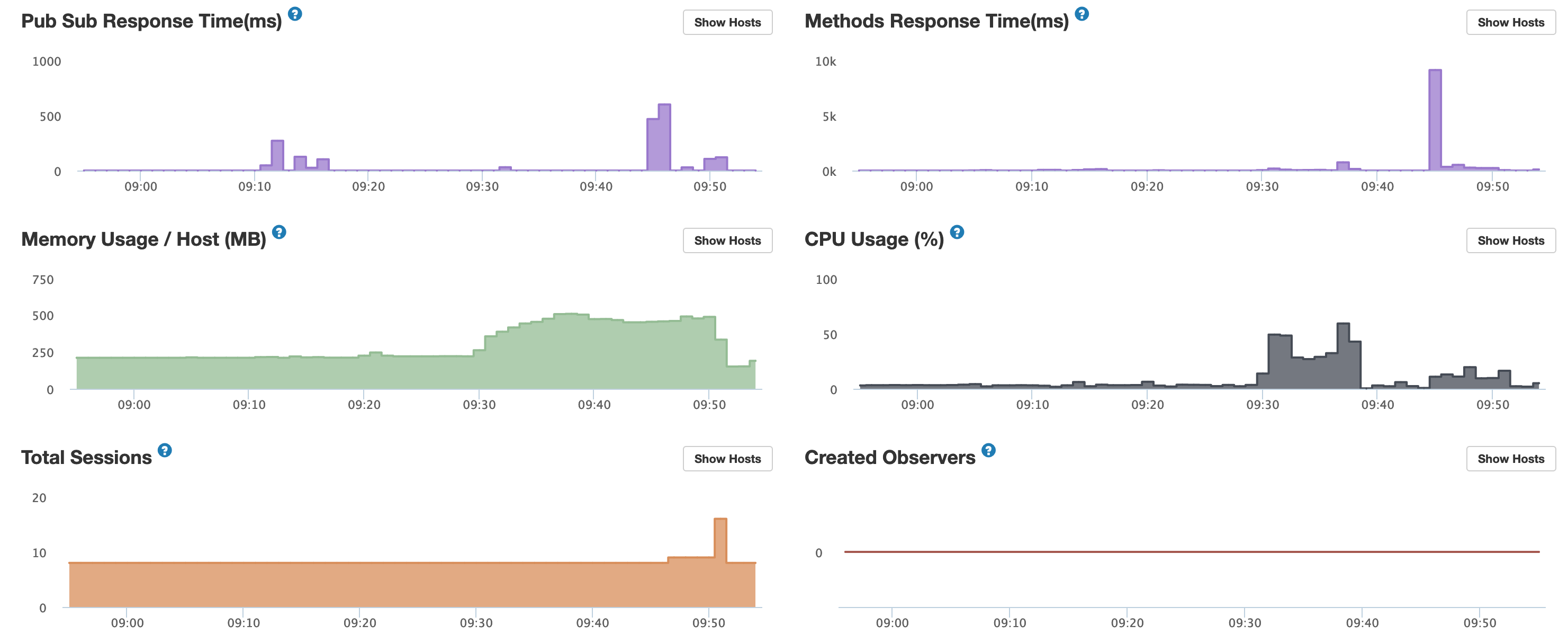
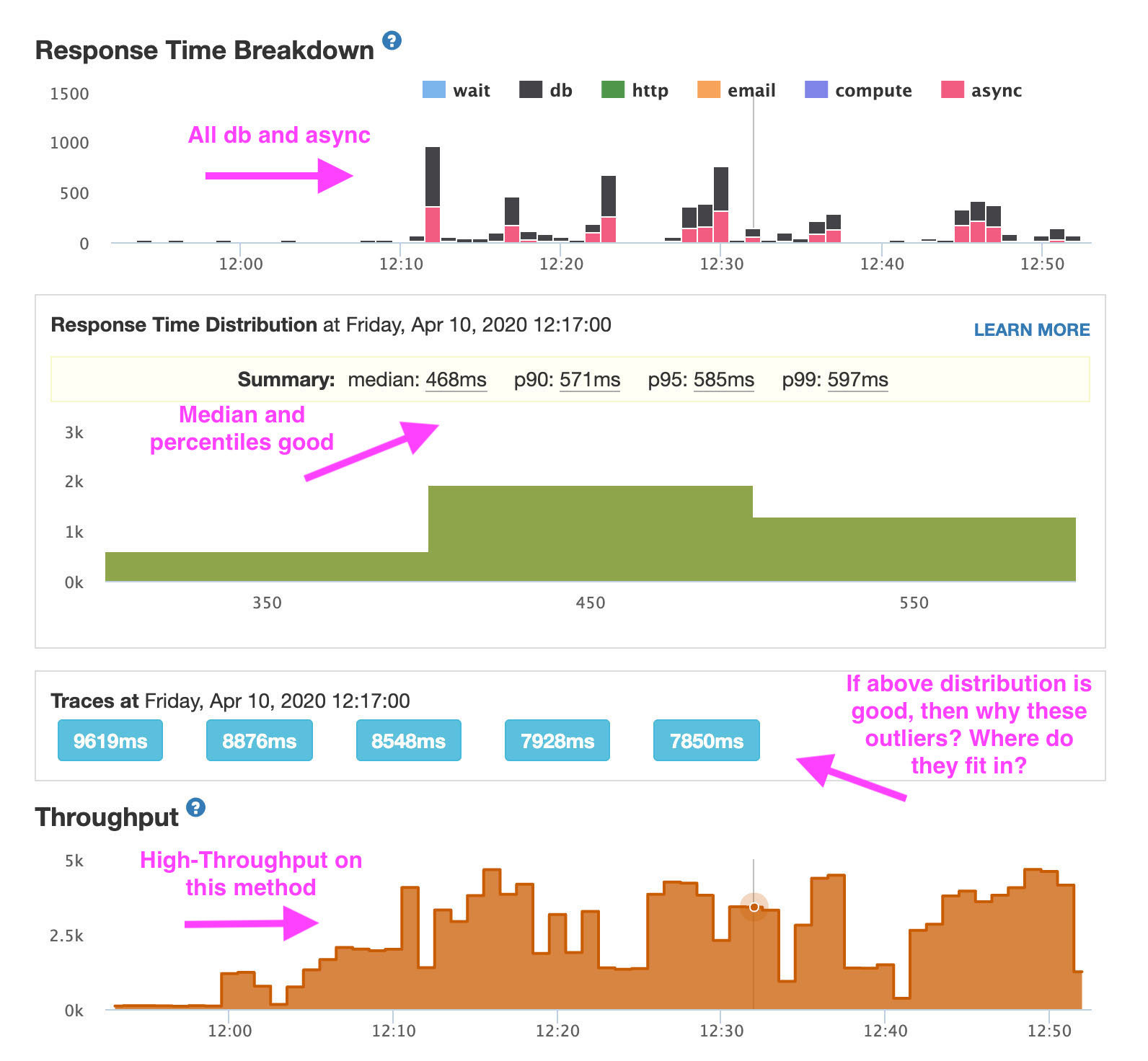
I have this same exact issue and am unable to figure it out. Was about to create a new post about it until I saw this thread. It’s not partial to Meteor.users, I get it on all my collections.
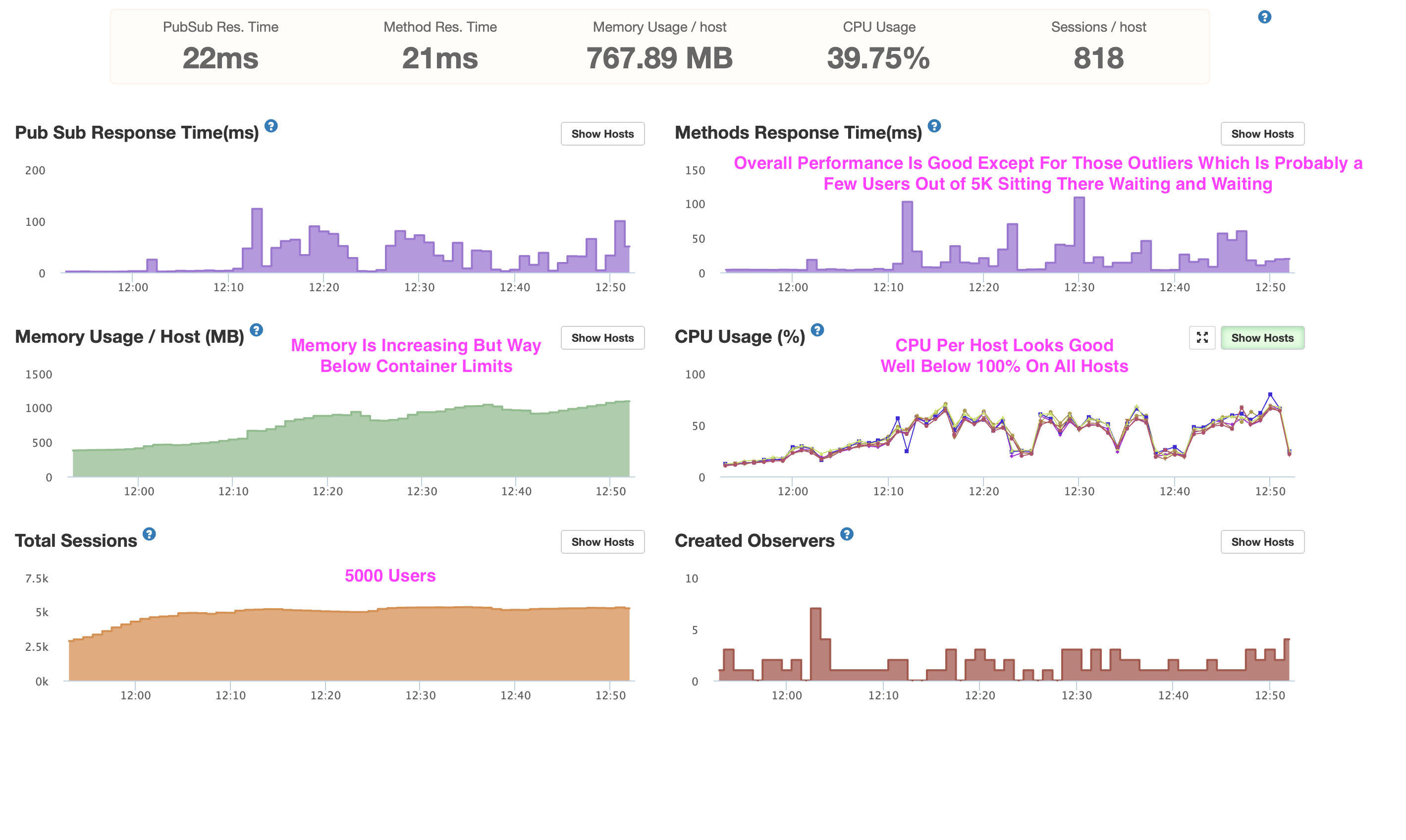
I have a production app that gets bursts of thousands of users at a time. They use the app for a little bit and then leave. I’m running six Galaxy Quad containers. I’m not seeing CPU spiking (at 100% at least) on Galaxy or in Meteor APM. Nor high memory usage. I use Mongo Atlas at the M40 level… so I’m throwing some firepower on this from both the Galaxy Container and Mongo Atlas fronts. My Mongo Atlas reports zero slow queries, zero missing indexes. I have all my indexes set.
My issues are all in the stack traces of Meteor Method calls, not pub/sub (my app uses a bare-minium pub-sub). I use redis-oplog.
When I click on a spike in the Response Time Breakdown my bars are mostly async (pink) and db (black).
In my Response Time Distribution I’ll see my median, p90, p95, and p99 all be fairly good (less than 500ms) but when I click on a spike, there will be a few stack traces that are crazy high (e.g. 9619ms, 8876ms, often worse, etc.) Not sure why these aren’t shown in the distribution above. I guess this means only very few users are getting these kinds of delays? This would agree with what I’m hearing from our users. If that’s the case, then why are the traces shown only the long ones? Shouldn’t there be some fast ones, even after clicking on a spike?
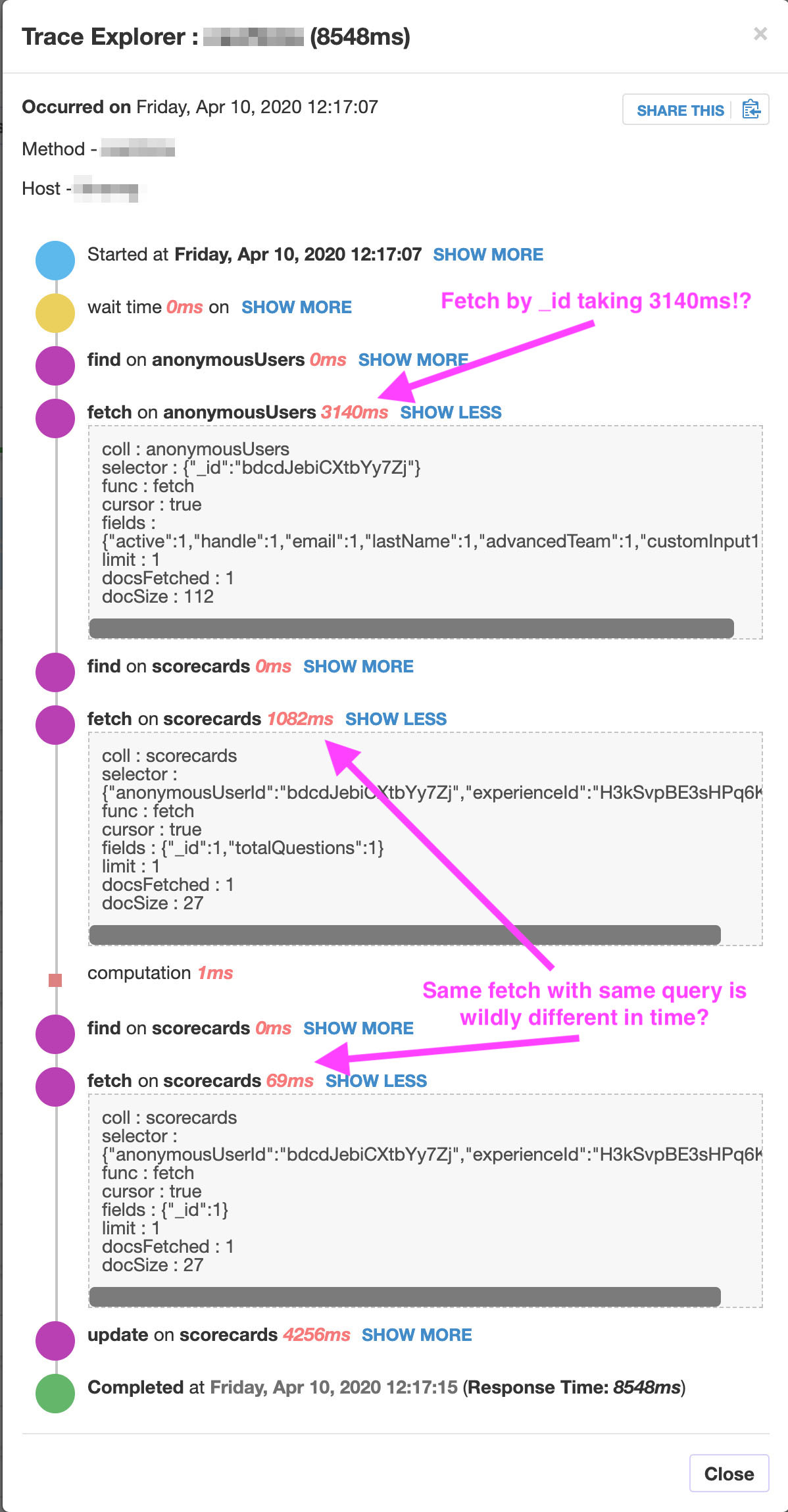
When I click on the long stack trace I’ll see:
-
fetch on a small document (anonymousUsers) by _id taking 3140ms+
- The same exact query (
fetch on scorecards) take 1082ms then later take 69ms in the same method stack trace (similar as OP above). Yes, I know this is weird/bad to query twice but upsert has been broken in simple-schema and collection2 when using autovalue for a while (need to see if this is still the case) this is why I do the same queries twice sometimes. Ignoring that, this illustrates the weirdness of the same exact query taking wildly different times to execute.
My database doesn’t report anything slow, my CPUs don’t seem close to spiking (at least to 100%), same with memory (plenty of both on Galaxy Quads). So I’m not sure what’s going on.
It could be my database hitting IOPS ceilings. It’s limited to 120 IOPS in Mongo Atlas. So maybe queries aren’t slow per se but the database is just being rate-limited basically. Though in Atlas I see the IOPS spiking to the limit but it doesn’t hold there very long. Anyone know about this? Could be the burst of users overloads the IOPS limit of the database? The amount of connections stays constant I assume because it’s still the same amount of containers. Can IOPS limits be busted by the same connections simply requesting more reads and writes?
Or perhaps my containers are truly CPU spiking and it’s just hard to see. I’ll have to watch my containers in Galaxy in the 5m setting (as OP describes) to see if I can see it actually spiking as all other time windows are interpolated. I didn’t get a chance to see that during today’s screenshots.
Whatever the reason, it definitely has to due with high traffic. Just trying to figure out where the bottleneck is. My app is highly optimized but with that kind of traffic, even a small bottleneck could cause issues. Going go back and try to get upsert working again (we recently updated all of our packages so it may be working now).
I’ve been plagued by this issue for years. Finally circling back to try to solve it again.
EDIT In trying to solve this, in all of our methods I have commented out our previous use of unblock everywhere. I was afraid perhaps there was “method thrashing” going one where on method couldn’t complete because others were knocking it out of the way, and so on, or something. This doesn’t seem to have had any affect. Galaxy performance is the same before and after.
BTW, I do see MUCH, MUCH better performance when using vertical scaling (fewer, higher powered Galaxy containers) versus using horizontal scaling (more, lower powered Galaxy containers). My database response times hit the roof with horizontal scaling (tried using 24 Standard containers vs. 6 Quad containers as a test). Not sure why… maybe it had something to do with the amount of connections or something.