@babnik63 yes, I solved the problem eventually it’ll take me around 20 hours for alpha, and 60 for stable and 200 for prod-ready. I had to re-think the approach from “How to re-use query watchers between meteor instances” into “how do I scale reactivity separately”, and what I realized is that we need to isolate the query watcher like @ramez actually suggested in the beginning on this thread but I thought it’s too hard. Now I have context, it’s not hard. The last problem I had is how can I have a “fleet” of query watchers work together to enable unlimited horizontal scaling. And hopefully this will work. I’m as unsure as I was about redis-oplog, in theory it looks fine, but in reality things may be different.
@msavin how would it help really? I’m curious and I’m interested in making this better known.
No, unless you can use redis monitor to see all incomming subscriptions, but we will need to add something like Issue #94 in the future.
Yes. But you need to have an up and running redis server. You should also add the package “meteor add disable-oplog” because as @ramez also noticed, it consumes CPU.
Sorry I haven’t been responsive lately, been caught up in client projects. I need to make you understand that after we actually solve the infinite horizontal scaling of reactivity, we will do a very big favor to Meteor as a framework. Many people quit Meteor because of the scaling problems mongodb-oplog faced, we did not only solve the problem, we will be the first system that will offer this out-of-the-box. It’ll be just a “package” in Meteor.
One thought was to open it to any db. In theory it is possible. However, we aren’t doing big-service to Meteor if we do that. Just like Grapher. I prefered to keep it as an atmosphere package, coupled to Meteor and MongoDB, and use 1 stack. Using 1 stack makes everything work together much smoother, because you won’t end-up with an abstraction layer at every step. So for now, we keep it laser-focused: Meteor & MongoDB
I think it will get a lot of interest, especially in the mobile development area, now we have ability to use React Native with Meteor. We can advertise Meteor to them, and show them how we solved the MongoDB problems with Grapher. And they can have a rock-solid backend, with live-reactive apps. And reactivity that is scalable, infinitely.
They will be sold in investing in Meteor => Meteor will gain the attention it deserves.
@diaconutheodor your technical skills along with the mindset and positive attitude you bring to this community are highly needed and appreciated. Cheers mate.
I wanted to add this for the benefit of the community:
When you publish a query that is id-based (including multiple ids such as with $in operator) redis-oplog switches to a more efficient approach (‘Direct Processors’) automatically, which is to setup a channel for each id, so it’s easier to watch. In other words it splits up the publication. This means you have opportunities to share publications as likely more than one client will be watching one or more of those ‘split’ publications.
You can see this in the readme of the repo under Direct Processors.
For our app we expect quite a bit of efficiencies when scaling up with ‘query watchers’ so that would be another major leap forward (on top of the current leap).
Now that this is almost production ready and some ppl seem to be trying it out in prod environments, it would be great for marketing this package if a couple ppl using it could create some load tests and publish the cpu/memory profiles and active connection counts for them. Showing test results while deployed in Galaxy would be a big plus. If it can be reproducibly proven to always be equivalent or better than Mongo op log tailing, perhaps we could even get it mentioned in the Meteor Guide
Hey I think the benefit of a brand and website would be marketing. Right now, it looks like a nice package but I do not think anyone would feel comfortable building a new business on it.
However, if you market it with detailed docs, more information about the team, etc, its going to look a lot better. Plus - I’m pretty sure you could build a business around this with a paid/enterprise version.
I would rather see this as a paid, supported package that I could build a business with than an open source project that may or may not be supported in 6 months.
Key example here is the Meteor-iOS project. It started out exciting, but now there have been no updates for nearly a year and the backlog of issues does not inspire one to use it.
I could see the open source version being a nice, quick fix for people who have the oplog problem. Once people start using your solution, they will want to “invest” into it as its in their interest to ensure its a sustainable project. And there’s like a dozen things you could build on top of this.
There have been some drastic changes under the hood. We are now by default race-condition proof, and we fixed a lot of bugs with this approach. The disadvantage is that we will need MongoDB a little bit more to offer rock-solid reactivity. The extra-queries we do should be very fast since they are only on “_id”, it’s too much to explain for this post, but it’s a trade-off we had to do to assure consistency.
Marketing Redis-Oplog
As @msavin mentioned, he is right, detailed docs, info about the team, etc and since this package targets apps with a lot of traffic, not 50 online users, but over 300-400, it’s clear that people who would use this, would have enough money to support it.
The problem is I believe in open-source. And I don’t want to make an enterprise only version of it, on the other hand, I see the point, as long as it does not provide business value to my company, I won’t invest too much in it, and this can collide with other people’s interests.
I will have to give this more thought.
@efrancis next step: make some official benchmarks.
From what I understand of the readme, this will fetch the N documents that match the query, execute the update and publish N messages.
The problem is that an atomic action is now not atomic anymore (even for a non-multi update?).
If in between the query and the update one document gets changed from foo=false to foo=true, it will not be updated by the query, but a message will be send saying it has been updated.
So you now have a wrong message and if your system depends on the invariant that assumes that if foo is true, bar can never be true, this might be problematic. I could be wrong, because I haven’t looked at the code, just how I understand the readme.
The anti-race approach if I understand it correctly means that mongo cluster becomes the master. So the setup you mention Will either already have a race condition in it with mongo or not. If it has you’ll have to design it differently.
@diaconutheodor, I agree with your change. Make it fool-proof out of the box. Does this mean we no longer need a redis cluster, so redis processes can be independent as they all depend on the mongo cluster?
My remark has nothing to do with the changes or mongo. It’s a different race condition, for which the only solution I can think of is if mongo would return the ids of documents it has updated.
I think I understand you better now, you are worried as what was originally a single update is now divided up into multiple updates, which conceivably can collide with another update somewhere.
It’s still different. There’s only one update query. But before that you have a select query to find out which rows are affected. However, in between there might be data changes, making your first select query have a different result set with what’s actually being updated in the db. (and therefore you get faulty redis change messages)
It’s so simple what I did, it’s almost stupid, instead of sending to redis the changed data, we send the _id and the affected fields. No actual data will be sent to redis, same thing applies to .insert.
The reasoning behind this is simple. We assume that fetching something by _id, is super fast, + you will not send through redis data/fields you don’t need. And you won’t have to make a requery after every update to send the propper data through redis.
With hindsight, I have no idea why I didn’t do it like this since the beginning.
Thanks. But from what I understand of your explanation, you’d still miss new messages that have been added and match the update query in between the select query and the actual update?
Missing messages are arguably not so bad like wrong messages though.
Yes, but not the update on that document.
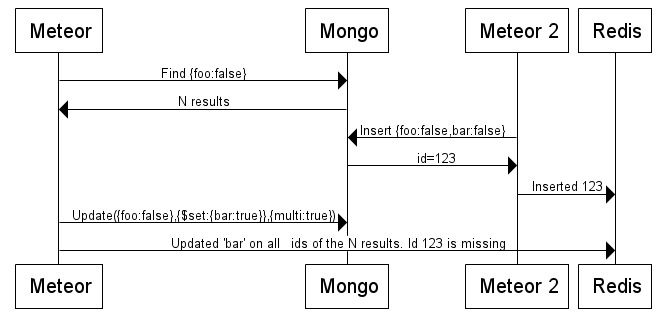
I’m talking about this situation (included 2 servers to make it more clear, but it can happen with only 1 server):
A listener on the Redis bus that fetches the document with id 123 between the insert and the update, would get: {foo:false,bar:false}, but won’t get a notification that bar has been changed.


 but I thought it’s too hard. Now I have context, it’s not hard. The last problem I had is how can I have a “fleet” of query watchers work together to enable unlimited horizontal scaling. And hopefully this will work. I’m as unsure as I was about redis-oplog, in theory it looks fine, but in reality things may be different.
but I thought it’s too hard. Now I have context, it’s not hard. The last problem I had is how can I have a “fleet” of query watchers work together to enable unlimited horizontal scaling. And hopefully this will work. I’m as unsure as I was about redis-oplog, in theory it looks fine, but in reality things may be different.