It’s because if you use the oplog, you don’t need step 1. The update is only 1 step. Redis-oplog needs to split this up in 2 steps to find which id’s to publish to the redis channels.
Collection.update Modify one or more documents in the collection. Returns the number of matched documents.
We will do a check, if the number of modified docs, differs from the number of ids we have. But still we will have no way to identify that document that sneeked in.
Just a note, open source and paid are not competing goals, and you could combine the two. Recently, I began to sell SuperMongol as an open source package.
As for donations, I think basically, one should never count on that because I don’t think it really happens. I see Evan You is earning around 10k/mo but that’s across a community of tens of thousands of people. Also, most of the support comes from companies with big interests in Vue, like Laravel
This doesn’t always work, because the same number of docs doesn’t guarantee they’re the same documents. E.g. when for each matching document being removed, another matching one has been added.
However, findAndModify looks like it could indeed solve the problem. Good find.
After some analysis if we use findAndModify we will no longer have support for collection-hooks and collection2, because we are wrapping the collection “update”/“insert” AFTER it has been wrapped by collection-hooks and collection2, therefore no longer calling the wrapped .update() function that will take care of validation / handling hooks.
An alternative would be that Redis-Oplog should be the first to wrap these functions. This could be solved if redis-oplog is loaded FIRST and configuration should be done via environment variables: REDIS_OPLOG_URL, etc.
All database index at compose are at 0, is this correct? There are some small picks shown at metrics.
We have few connections, less than 30 concurrent users.
Yes, you are right. I just now realize this. I think I will leave it like this: we find the docIds, and when we perform the update we add an extra rule that the _id is inside those _ids found first time.
This way, we solve all of our problems. The only drawback is that if between 10ms a doc sneaks in it will not get updated. And in my opinion this is not such a bad issue.
I think that’s indeed the best solution. It might actually even be better than updating the new document.
Because if you look at the flow of things:
Update query is translated in:
fetch docs
execute the update
send docs.
If an insertion happens between 1 & 2, we probably don’t even want that one to be updated, since we intended to do the update at step 1, before that document was inserted
Okay, now that problem’s solved, here’s another one :).
The order of operations in Redis can be different from the order they were actually executed.
E.g. (basically a variation of another problem I mentioned above, but lots of variations possible):
(although way more likely with multiple Meteor servers).
Not necessarily a problem (and afaik, no solution possible here) but it might be important to know depending on how one reacts on data changes.
E.g. Let’s say Object B refers to Object A with a property called ‘parent’.
A current Meteor system could safely assume B.parent will exist if it receives object ‘B’. This assumption no longer holds, which could result in application errors. Again, most of the times this can be solved in the application, but you need to be aware of this.
This is a classic cache consistency problem. Any distributed system needs to solve this, and redis-oplog can be thought of as a distributed system even with 1 instance.
I think the standard solution to these issues is to use internal timestamps as well as synchronized time to maintain the correct order of events across servers. e.g. mongo internally uses timestamps to reconcile replicas based on their oplogs. But using these would require processing the oplog which defeats the entire point
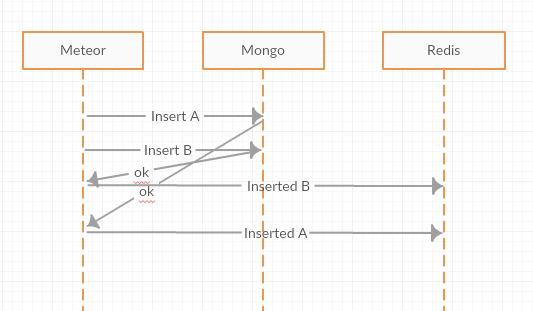
Here is where you lost me. Because if Object B has “parentId” referencing Object A, you first need the _id of Object A, which means you need to have it inserted, which means you get the “ok” for inserting Object A before Object B.
There is no need for timestamps. Mongo is the single-source of truth. We made this decision one release back, to always get the data from mongodb. And since most of the queries will be by _id, it will have minimal impact.
Is there a way that we can make this work with collection2 and collection-hooks? My set of Socialize packages would greatly benefit from redis oplog, but they make heavy use of both of these packages.
 will analyze implications, and we can do it.
will analyze implications, and we can do it.