The Mongo explain function is your friend here. Test out your queries by using explain("executionStats") to see the difference between the number of matching docs versus the number of scanned docs. A big (or at least significant) difference between these numbers means you’ll likely want to add an index.
2 Likes
I thought this number was supposed to be lowered. Not raised
1 Like
SUCCESS!
Thanks for the help guys! Pretty sure I just solved the Mongo problems that I was facing.
Here’s a mini blog post on the process I went through:
Quick background: I’m using Compose.io for MongoDB hosting (their MongoDB Classic package as of now). The app was being really slow at responding and I didn’t understand why. Compose.io support were suggesting I add more RAM, which I did, but that really didn’t help anything and was just costing me more money. Kadira was showing me something like this:
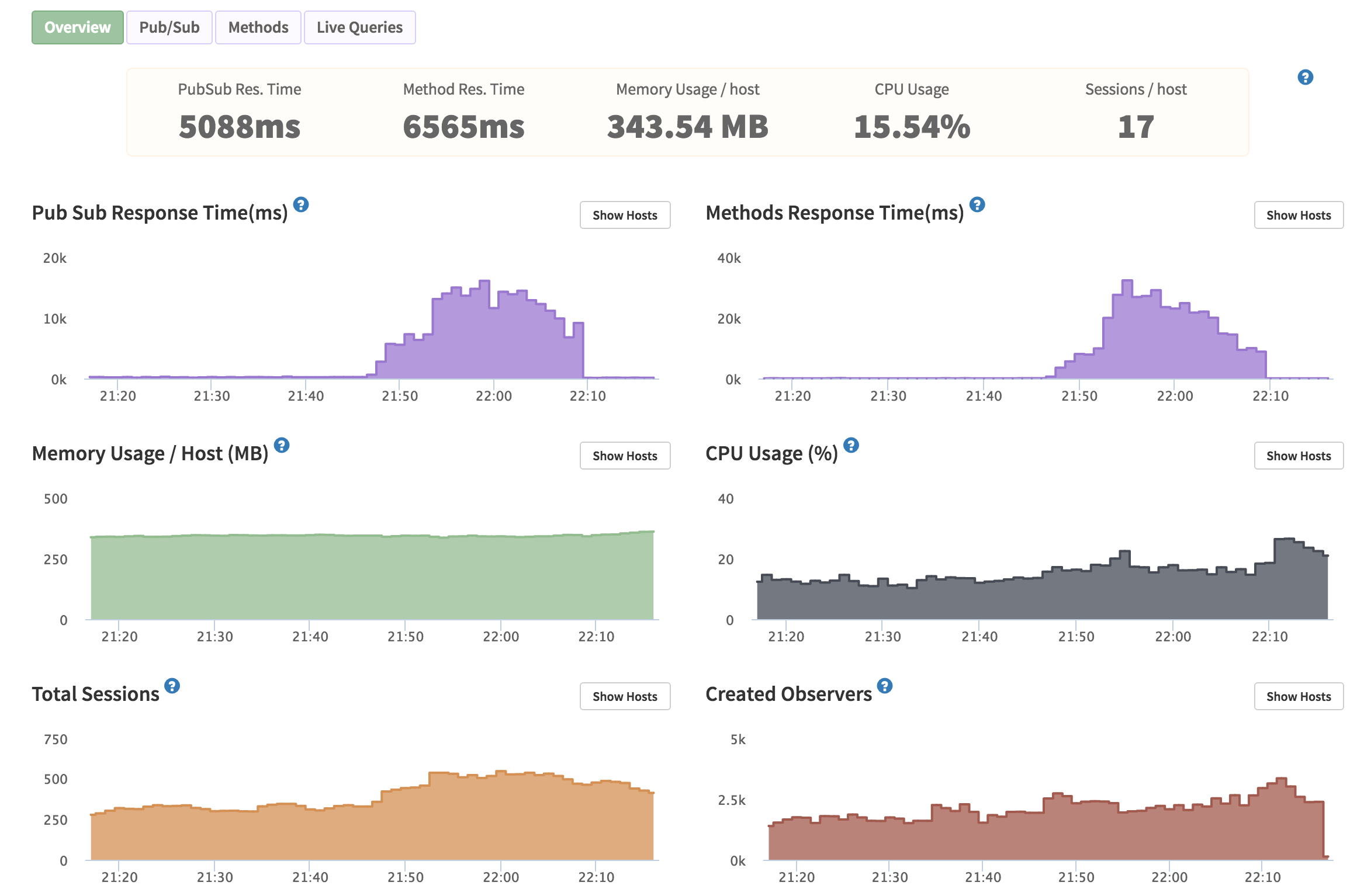
(Response time goes back to normal at around 22:08 which is when I solved the problem).
The database was taking ~30s to respond to queries during peak traffic, but I couldn’t understand why. Adding more servers didn’t help anything and actually made things worse because the DB couldn’t handle all the connections as @int64 mentioned above. (I was running 50+ Meteor instances at some points. Now it’s about 20).
Kadira helped by showing me that the method response time was slow due to Mongo taking ~30secs to respond!
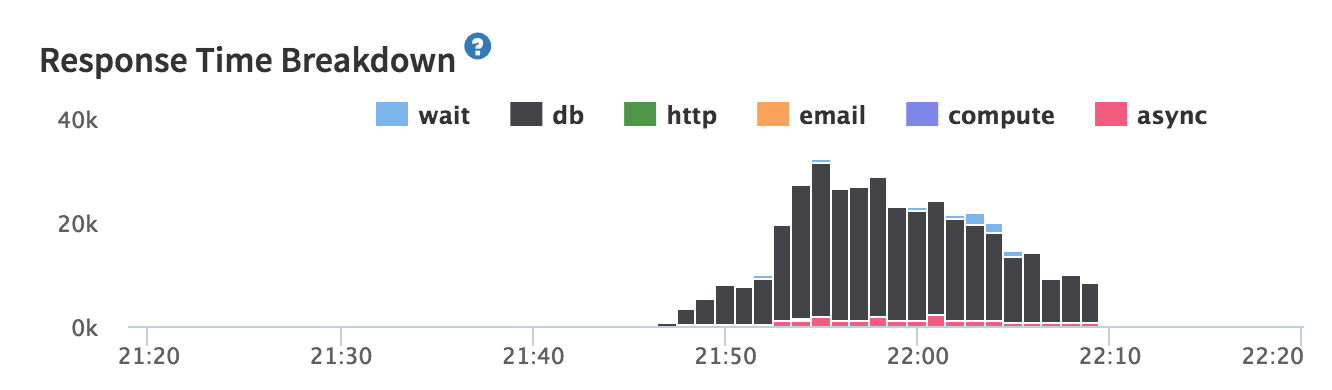
But this only helped me part of the way because all DB operations were slow. So how do I find the problem?
Ask on the forums, SO, and Compose.io support ![]() which led me to:
which led me to:
During peak times I logged in to Compose.io and had a look at the current ops that were running and saw something like this (but far worse):
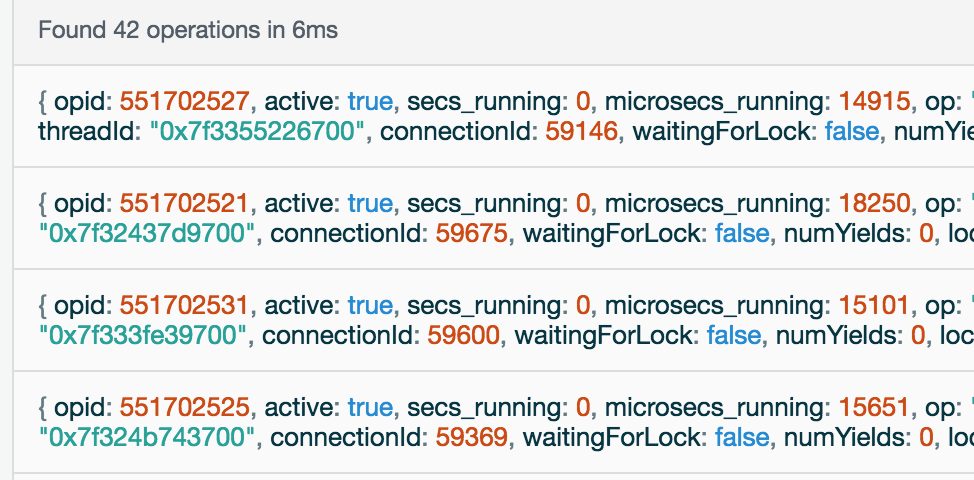
Had no idea what all this mumbo jumbo was, but you’ll see that each op has a secs_running field. In the image above it says 0 seconds for everything, which is great! But what I was seeing during peak time was 14 seconds, 9 seconds, 10 seconds… for the different operations that were going on! And it was all coming from the same query being made by my app.
I ran this query myself and it really did take something like 16 seconds to get a response! Not good! And running it with explain (as @hwillson suggested) showed that 180,000+ documents were being scanned! Here’s an example of a problematic query:
Anyway… lo and behold, there’s no index set up for such a query, so I added teamId1: 1, gameweek: 1 and teamId2: 1, gameweek: 1 as indexes and ran the query again and I get the response in milliseconds.
After this the whole database starts acting quickly again. This one problematic query was slowing down the entire database!
I use indexes for almost every publication, but this is one that I forgot to add and it wasn’t easy to find initially!
Hope this helps someone in the future. Might make it to Medium at some point. Or not ![]()
Thanks a lot for the help again!
26 Likes
How did you discover this particular query was the problem? You just found it eventually or was there something to actually lead you to it with Kadira or Compose etc.?
I have about 150 concurrent users on only one Galaxy instance and my Compose.io database is bottlenecking and the app is hanging. I’ve added indexes already but one question I have is if you have a collection that needs multiple indexes like so because of the way they’re subscribed to:
Products._ensureIndex({systemId: 1});
Products._ensureIndex({categoryId: 1});
Products._ensureIndex({userId: 1});
Is it better to compound them:
Products._ensureIndex({systemId: 1, categoryId: 1, userId: 1});
Especially if some of the subscriptions actually use two of the fields for querying also? Note my products collection has 17000 documents
I wrote an article on it over here:
But I thought I posted the details in this thread too. Basically in compose
I found queries that were running for a long time. Also send an email to
compose support and ask if you’re doing any collscans. There may be a way
to check yourself if you’re already on mongo 3.2 with compose.
2 Likes
Read the article, super helpful.  But it’s the quoted line where I’m not connecting the dots. In Compose I can see my long queries in the “Current Ops” window (like your article demonstrates)… but those queries don’t seem to have any data connecting them to what the actual query is in my app. The
But it’s the quoted line where I’m not connecting the dots. In Compose I can see my long queries in the “Current Ops” window (like your article demonstrates)… but those queries don’t seem to have any data connecting them to what the actual query is in my app. The opid and threadid fields don’t offer much help.
It should say what the op is and what the query is too. Although they’re not in the actual screenshot.
A couple updates:
-
After a lot of head-scratching, I realized I was missing a critical index on a query in my
ensureIndexcalls for my 17000 document collection. So I think that is going to fix the bottleneck. Testing currently, will update.
So I think that is going to fix the bottleneck. Testing currently, will update. -
I get the below fields in compose.io under the “Current Operations” tab. Still not sure how to relate these to which queries are running in my app:

-
One thing that has helped is adding
db.setProfilingLevel(1)from the mongo shell on both members of my database. In the shell, callingdb.system.profile.find()is showing me actual queries (with query and collection fields) that are taking longer than 100ms. Super helpful. Anyone know any 3rd party profilers that might help with this graphically? Still working on getting Compass to work (see below). -
I was looking through
db.system.indexes.find()and looking at all my indexes. Why doesn’t Meteor set all the default_idindexes for each collection withunique: true? Isn’t_idalways going to be unique? Was just curious. -
I’m having trouble getting MongoDB Compass working. It’s throwing errors about “not authorized on admin to execute command…” I think it has something to do with adding an
adminuser with authorization on Compose.io? Upon Googling it looks like an involved thing to get setup including restarting your database, etc.
This is the most common scaling issue by far. Make sure you have indexes set up before going to prod!
2 Likes
Yeah, so these are all “getmore” operations. You’ll see something else for op if the query is taking a while. This doesn’t look to be the issue from what I can tell.
I would send Compose an email asking to view the logs of all collscans. Any collscan you find means you’re missing an index.
Taking full control of the database yourself may be an issue while using Compose.
And the indexes for _id should all be set up for you automatically by Meteor.
So what’s the strategy when it is finally time to scale Mongo? I think I read something about “shards”? If you have 10,000 users or more you’re going to eventually have to have more than your single Mongo Compose instance right?
You can go well above 10k users before sharding. It all depends on what
you’re doing with your db. But you could easily have 100k and only 100mb
user collection. That’s nowhere near needing sharding. But it depends what
your app is doing.
Sure the database storage is small, but what about handling the simultaneous traffic load? Won’t there eventually be a bottleneck with (for example) Compose’s actual servers hosting Mongo and/or Mongo itself?
I guess if you have 10k simultaneous users which do heavy database writes, you may have to switch over to redis-oplog to handle Meteors reactivity. But it all depends on your application, if you don’t need live updates (reactivity) I guess that Mongo will work well if you’ve set all indexes right.
We’re running our adservers database on a $40 VPS system which handles about 5 million ad requests a day (each request generates a new MongoDB document). We don’t need sharding, just a single VPS and Mongo is doing very well 
3 Likes
Eventually. It won’t be at 10k registered users though.
It depends how heavily you’re accessing the database. Unless you’re doing a
tonne of writes per second or something. Mongo won’t be a bottleneck any
time soon. Will be hard to make your database a bottleneck unless indexes
are setup wrong.
And Redis oplog is to do with scaling meteor, not mongo itself from what I
understand of it.
Correct, just wanted to note it since it’s also relevant if you scale your Meteor application and you depend on Mongos Oplog.
Thanks for sharing! The importance of Mongo indexes cannot be overstated.
It looks like I may have more issues than just indexes… I had a small surge of users this morning and things ground to a nasty halt. I had Kadira going thankfully.
It looks like my CPU, memory, and methods are all fine… it’s pub-sub that’s killing me. See Kadira summary - yes 144 second response time:
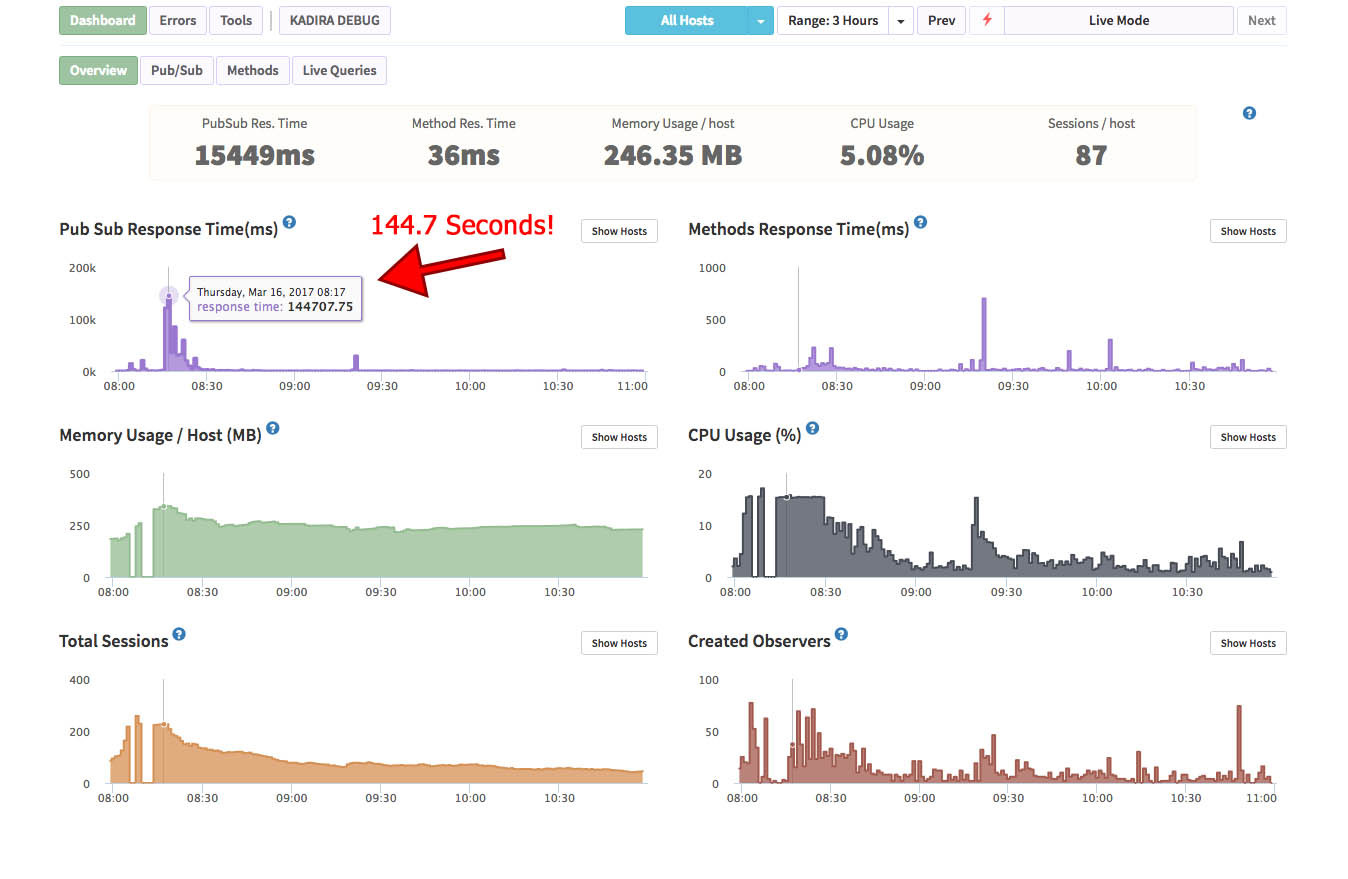
I started diving into my pub-subs stack-traces and I found something odd. ALL of my subscriptions spent a ton of time waiting on meteor.loginServiceConfiguration. I’ve attached a stack trace of one subscription showing how it waits on meteor.loginServiceConfiguration, then one showing how long meteor.loginServicConfiguration is taking. I googled around to see if anyone ran into this. I found an old github issue, but no resolution. I’m not sure if it’s a problem with meteor.loginServiceConfiguration, a design issue, or if I need to add an index somewhere for that, or if this is just a side-effect of something else blocking other things, etc.
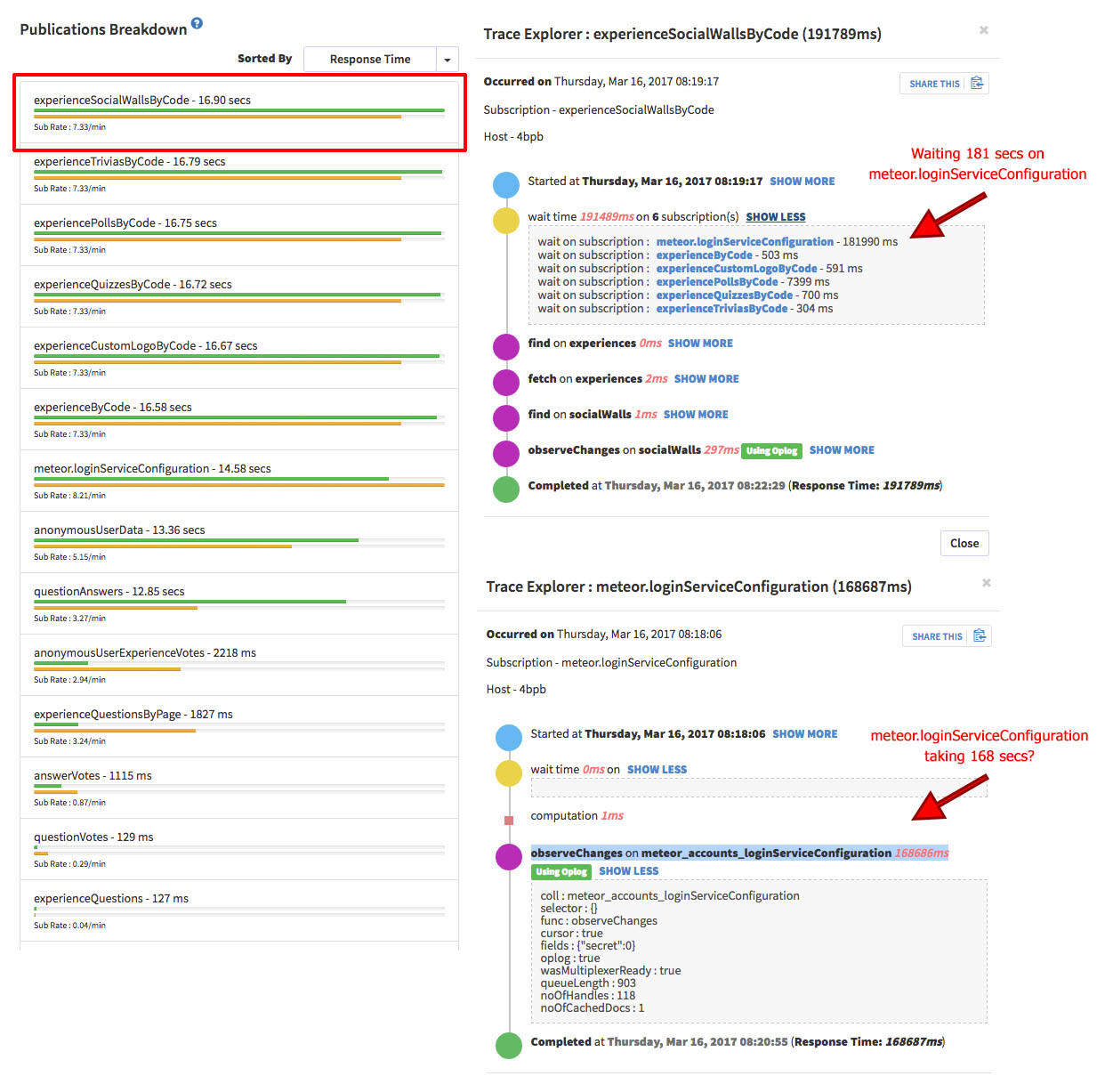
All my other subscriptions are fairly quick. There’s probably some tune-up that should happen, but they’re all just waiting and waiting on the above subscription.