TL;DR: OPLOG and/or Meteor poll and diff is the issue. Will integrate redis-oplog in three weeks.
After a lot of thread-reading and Kadira metrics analysis, I think I figured out what the issue is… it’s the classic circa-2015 “OPLOG clogging everything up after about thirty users issue”. And if by any chance it’s not the OPLOG, then it’s the Meteor poll and diff that’s getting me. Sadly, it’s taken me forever to realize I’m having a problem with something that was really well known for the last two years.
I finally found some really helpful threads and realized my app was doing “high velocity” writes. All my users send an update at almost the exact same time, what’s more, they’re all updating the same document. I found a post by MDG about how Meteor 1.3 has some new tools for disabling the OPLOG and how a large number of writes on the same object can create a hotspot without maxing out the CPU which was a phenomenon I was seeing. The following pages were really helpful:
OPLOG: A TAIL OF WONDER AND WOE (Very similar to my use-case)
Meteor OPLOG flooding (Great forum thread)
Tuning Meteor Mongo Livedata for Scalability
My experience hitting limits on Meteor performance (Also similar to my use-case)
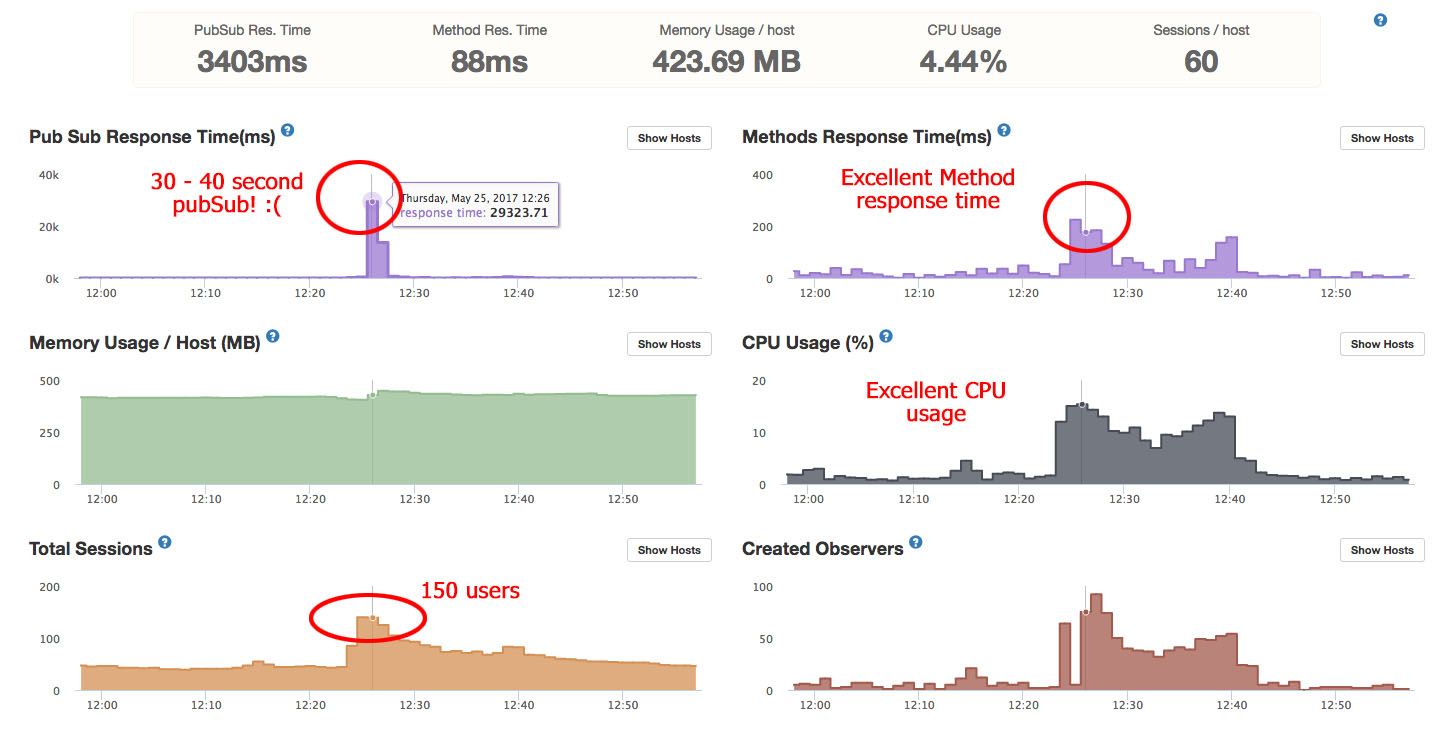
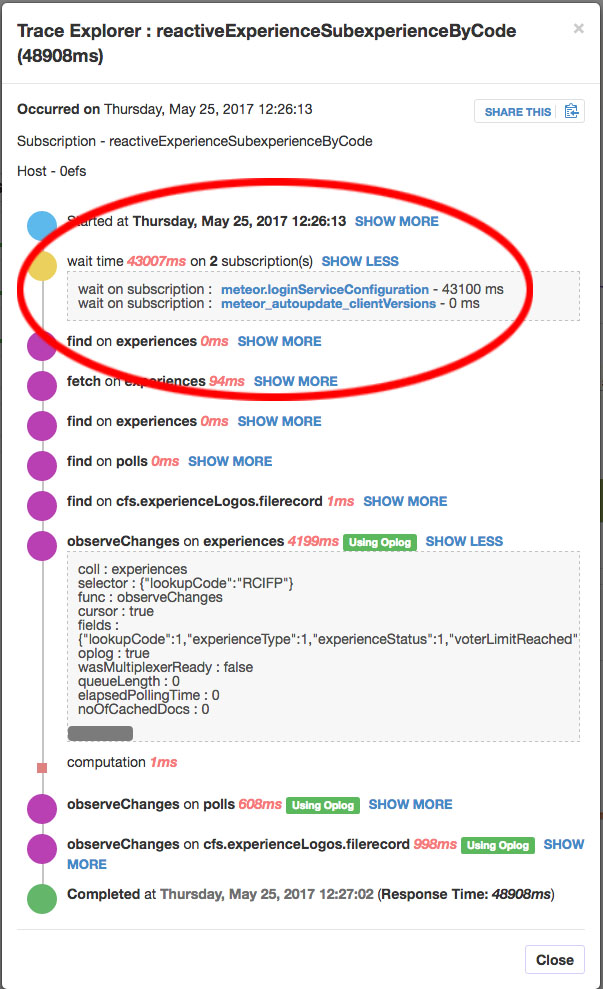
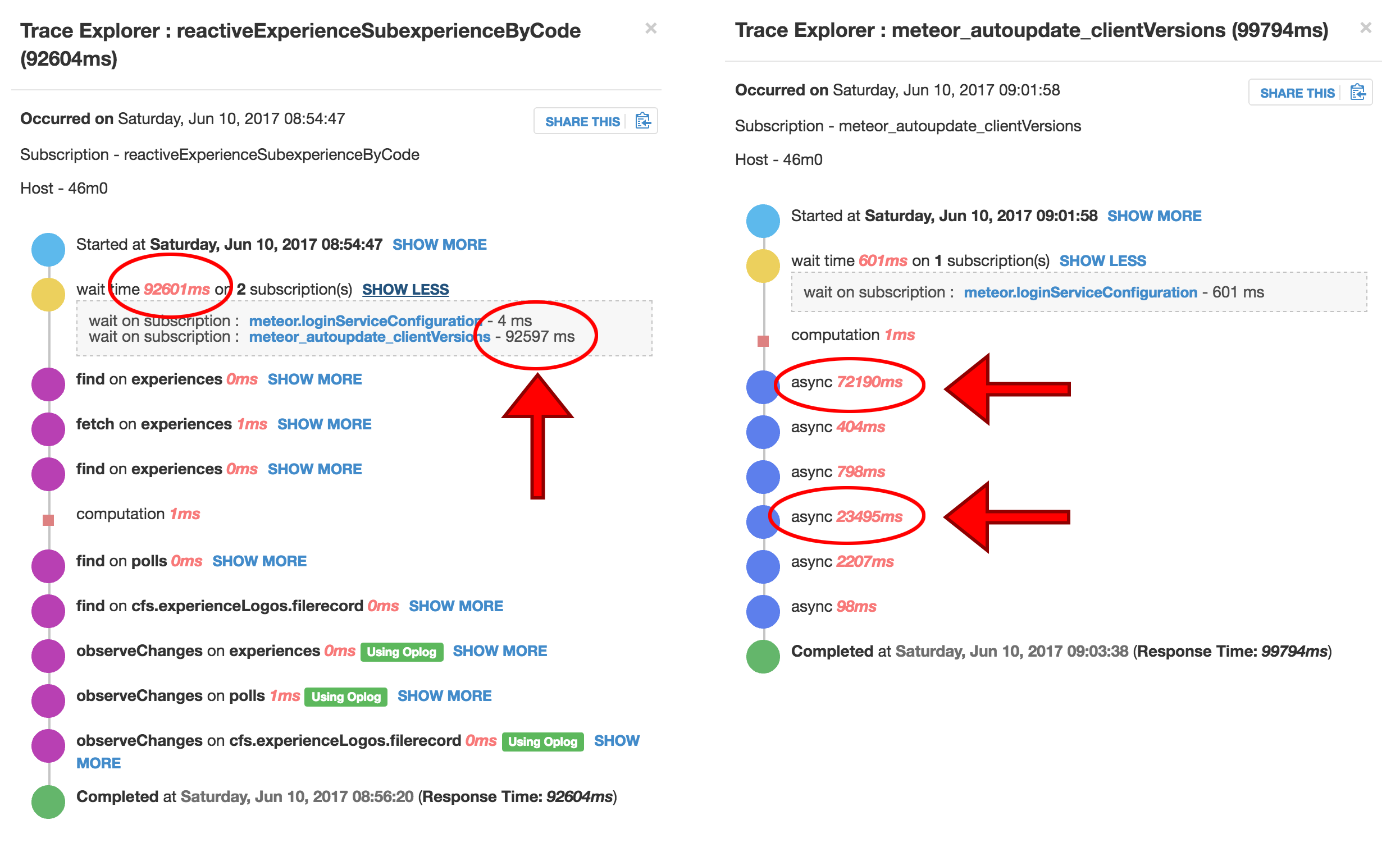
I did a “deep dive” into my Meteor APM (Kadira) data for this latest server slowness and I started noticing a lot of funny things. I found stack traces where meteor_autoupdate_clientVersions was doing a bunch of observeChanges that were really slow. A lot of observeChanges in my app were fine with only a few users but once more than twenty or thirty logged in, the same observeChanges slow to a crawl.
The issue with meteor_autoupdate_clientVersions and meteor.loginServiceConfiguration having long wait times is indeed as I suspected merely a side-effect. If I understand correctly, both of those calls are synchronous on each client… they don’t use this.unblock(). So if my app is loaded up with 150 users and the OPLOG is clogged to all hell and back, those new users who log in get stuck waiting on meteor_autoupdate_clientVersions and meteor.loginServiceConfiguration which is in alignment with what my users were seeing in the app. And there’s always new users logging into my app because my app is very bursty - i.e. it goes from 5 users to 150 or more in about a minute.
Another huge gotcha I discovered is my admin app was actually creating/getting a ton of OPLOG traffic from my non-reactive mobile-client app. My app is actually two apps. An admin app and an end-user mobile-client app, both connecting to the same database. In the mobile-client app, I flame-thrower’d all the reactivity out of it (per my input above) and didn’t understand why the OPLOG was still killing me… well, I didn’t remove any reactivity out of the admin app because there’s only ever maybe five users at any time using the admin app. However, if my assumptions are correct, those five users on the admin app are all processing the reactivity of my 150 mobile-client users. So all those interactions all happening at the exact same time on the exact same object are being multiplied by however many admin users I have. And also still a little bit on my mobile-client app because I had to leave a little bit of reactivity in it. So this was something I didn’t consider… that Meteor was still having to process the OPLOG for my admin app users.
Another weird little gotcha is MongoDB shows no slow queries. Which can’t be true because Meteor APM (Kadira) is showing me all kinds of find() and fetch() calls (i.e. a Meteor findOne()) that are taking 3000+ ms. I checked my slow queries on my PRIMARY mongo node and it showed only about 19 slow queries, each no more than 200 ms, all from several months ago… weird. I checked my SECONDARY mongo node which is what enables OPLOG and the slow queries was empty. BUT, the compose.io help team told me this table can occasionally reset itself when a resync is performed. So there’s a very good chance I’m likely not seeing my OPLOG slow queries being reported. Not sure how often a resync happens between the nodes… seems fairly often as I checked the SECONDARY for slow queries a few days after this latest case.
So now, I’m going to build some diagnostic testing tools to simulate all those users so I can create this storm of activity at any time on my own. Then I’m going to disable the OPLOG and see if I still have this issues without it. If so, then I’ll have to figure out what to do about that. If not, I’ll very likely try to start integrating redis-oplog which makes me very happy because I removed a lot of cool interactivity trying to solve these issues. It would be great to get it back. My only other option is to try some of the Meteor 1.3 disableOplog options on publications (I’m still on Meteor 1.2.1). I’m sure those would do the trick, but then again, I’m losing some responsiveness. In about three weeks I’m going to jump on this full-time and will report back my findings and results.
So this still could very well be a “Mongo Scaling Issue”… more to do with the OPLOG, but still Mongo involved also.
@elie I haven’t upgraded yet because this is for a production app. In the past, whenever I upgrade I always have a package or two that breaks. That was when I was upgrading right away, so now I’ll probably be okay. But again, with a production app, you have to have the time to test and work out any issues, which at the moment I’m short on. I’ll upgrade to 1.5 hopefully in about three weeks.