Hello everybody,
I’ve just searched about MongoDB sharding in combination with Meteor, but didn’t find an actual statement, if it is possible or not.
At the moment, we have a Meteor app connected with a MongoDB replica set (3 servers). When the day comes, we need to scale our database and add some new servers to it. That’s the point where we want to use MongoDB Sharding. In some topics from 2013/2014 I found comments, that it isn’t possible with Meteor to use a MongoDB Sharding cluster. The main problem was the “Oplog”. Then I’ve found an article from this year, telling how to tail the MongoDB oplog:
My question is now: Is it possible at this time, to connect my Meteor app with a Sharded Cluster and does it automatically “hide” the fromMigrate documents?
Currently there is no way to process handle Meteor oplog with sharding. For now, you may need to shard you data in the app layer and use two different replicas.
It may involves connecting to a custom mongo connection for each shard with the oplog connection.
@arunoda Thank you for the answer. I’ve found that in the Meteor docs:
If you do shard your database, be sure to shard the application server processes along with the database masters. Each application server should be dedicated to a particular shard and connect only to the database master for that shard. That way, each application server only has to process the update messages from their particular database shard, not from every database shard.
Is that what you mean? Would it mean, that I’ve to install an instance of my Meteor app on a master and then connect this instance to “mongodb://localhost”?
yes. It’s the same.
That means shard in the app level.
Then means you are three different replica sets and use three different apps.
Anyway, this is an area for research.
There is an existing discussion on the forum. Search for Sharding.
@arunoda Yeah I know the discussion here in forum, and unfortunately it ended without any productive results. So if I understand you right, in that case I can create a single deploy environment for each “replica set” (I’m using your package meteor-up, means that I’ve to create a single mup.json for each replica set)?
I’m just asking, because I’m very new on Meteor and didn’t worked before with clusters and sharding.
Thanks for sharing that link. Have you tried it yet? What I read is that with redis-oplog you no longer have any issues as the main issue (mongo oplog when you have different shards) is no longer there.
This would be huge step forward in Meteor scaling!
I actually did try it (and meant to update this thread). I used MongoDB Atlas and sharded a database (which BTW is not reversible - so make sure it’s a test database). You get a similar Mongo URL as an unsharded database except you have like seven shard URLS in a row versus the three that a standard unsharded MongoDB Atlas database has.
I have a bottleneck at the Mongo level with my app and how many simultaneous users I needed to work with, so I sharded my test database and did a 5000 user simultaneous load test in the cloud to see if performance improved.
redis-oplog indeed worked and everything stayed reactive, but I didn’t see any performance improvement when going up to seven shards. I got the exact same performance as an unsharded database.
I’m no Mongo expert, but it seems to behave and perform exactly as if I had not sharded into seven shards (which is a lot and should improve Mongo performance with simultaneous operations). So I’m thinkink Meteor probably doesn’t know how to connect/work with the shards and it default to connecting the way it normally does to an unsharded database, hence the equal performance.
I ended up getting good performance by highly optimizing the bottleneck Meteor Method that all the users hit at the same time (and how many related Mongo queries/updates occur from validation checks, collection hooks, and resultant checks - I had a ton). And I also cranked my MongoDB atlas database way up to their M200 level. Which uses like 64 vCPUs, 256GB RAM, and has ultra-high IOPS. I only need this for a certain period of time so I’ve dropped back down to the M30 level. I also found some alleged bugs in redis-oplog that caused a lot of extra Mongo calls (that I’m working with them on figuring out and fixing).
So continuing to work on optimizing and doing cloud load tests to verify results and performance.
I haven’t used Atlas (and likely won’t, we’ll set up our own shards) so hope I can just point to mongos and we’re done. Can’t you do the same with Atlas?
I probably didn’t connect correctly. Your comments are echoing some recent comments on the above Stack Overflow thread too, which were:
@evolross I don’t think you have to add 7 MongoDB shards’ URLs to you Meteor app. Have you tried adding mongos URL to env instead of shards’ one? MongoDB official site said that we should connect to mongos in order to interact with the sharded database, and avoid interacting with the shards directly. Regarding to the bottleneck at MongoDB level, I don’t think it’s a problem with Meteor. It’s most likely that you forgot adding necessary indexes or forgot passing shard key in queries which cause MongoDB to query every single document on all shards…and here comes performance issue. – Pakpoom Tiwakornkit Jan 27 at 12:04
Is there anything in the Meteor docs about shard key or mongos? Have you personally got it to work and can prove the shards were working? And I have all my indexes and have written many topics in the Meteor forums about optimization. It’s the way my app works and the amount of users I have simultaneously. – evolross yesterday
@evolross Meteor doesn’t have docs about shard key and mongos as it hasn’t yet officially supported sharded database. In fact, Meteor doesn’t have to know if the database was sharded or not because we will have Meteor connect to mongos and then mongos will take care of the clustered database. Indeed, you don’t need to read shard key and mongos on Meteor docs because it’s already there on MongoDB official site. I haven’t yet personally got it to work as I’m now developing this kind of application like you. if I finish developing my app, I will let you know. – Pakpoom Tiwakornkit 15 hours ago
After you shard, it gives you the exact same format URL but with twenty-one (not seven as I mentioned above) shard URLs (three for each shard - an XX-00, XX-01, and XX-02 - three replicaSets per shard?) versus the three above. So I just plugged it in because that’s what Atlas gave me after sharding on their app and it performed the same. Definitely didn’t do the mongos thing. Will have to try when I get time. This could help my use-case a lot.
Thanks @evolross, and I am not the one from SO [I did see that SO thread, though] - I would love to hear how it works out if you get the chance to solve the mongos issue. Maybe Atlas support can help you (or their docs – I’ll give it a try if that speeds up your tests).
Having real scalability with Meteor is new, and thanks to great work from the likes of @diaconutheodor we can cross that final frontier! (As you can tell, I am a Star Trek fan)
I’ve tested, Meteor works well with mongodb server which has sharding configuration. But I lost the meteor service configure file then I don’t remember the configure URL, but it worked.
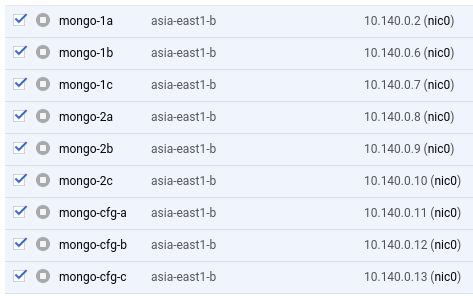
Here is the list of server I created on google CE to test.
I never got it working. It turned out that my bottleneck was in my application and not at the database level.
However, I do have a use-case now where I have European users complaining about latency. In my app every second counts - it’s for gaming. And I think it’s due to the fact that ALL of my app’s servers are on AWS in us-east-1. That goes for Meteor (on Galaxy) and AtlasDB and Redis.
So it seems simple enough to deploy some Galaxy containers to Europe in eu-west-1 and then have AWS Route 53 route based on latency or geolocation, but the database part is still a bit of question. It looks like AtlasDB now supports cross-region replication (though I thought this was always possible if you sharded into different regions). But I’m wondering if anyone has ever done this successfully?
As for me, I think I’ll need my app, database, and my Redis server (for redis-oplog) all in the same datacenter in eu-west-1 in order to get better European latency.
I just got a setup working where I can use a sharded MongoDB and still have an oplog, but it took a decent amount of custom work. My code base is mostly C++ so things might be different for you, but here is what I did:
1.) Built a custom version of mongo-c-driver and mongo-cxx-drivers that remove the checks for dots (.) and money signs ($) from collection fields
2.) Clone the mongo package from meteor and modified it to remove the local and master checks from the oplog_tailing.js file
3.) Built a custom C++ server I called “oplog consolidator” that uses the custom mongo drivers to run tailable cursors on the oplogs of all the shards and sorts the docs/entries coming in from all the shards before dumping them into a consolidated oplog in the form of a regular capped collection
4.) Configure the meteor oplog URL to use the consolidated oplog collection based on your desired setup
In my setup I have a non-replicated in memory mongo instance setup to handle the consolidated oplog, but you could vary up the setup details a little bit depending on your needs (e.g. keep the consolidated oplog inside a local collection to prevent writing an oplog on the consolidated oplog collection if you’re outputting it to a replica set). You just have to be careful not to output the consolidated oplog to a server your consuming an oplog from or you will end up with a recursive oplog entries that eventually hits the max document nesting depth.
The performance of the oplog responsiveness is comparable to a classic setup so no issues there. I assume you could create an oplog consolidator in another language too, but you may need to make similar changes if the driver is as pedantic as the C/C++ drivers (technically the C driver, but the C++ driver builds with it and thus gets affected by it’s picky nature).
Let me know if you need more details or the source for the C++ application and I’ll see if my firm if I can get cleared with releasing code. I’d also have to clean up the application so it doesn’t depend on our internal infrastructure and libraries.
The extension oplog-redis disables meteors internal tailing cursor and replaces it by a module which listens on channels in redis for changes on the database (one channel per collection, so you’ll only have to process changes of collections a client has a subscription on).
The downside for us was just that it now is Meteor informing Redis about the changes it does. So every change in the database requires an additional message to Redis. This is already done for changes from within your application, but you have to add it for other services. If you do not need to care about non-Meteor changes on your database, you should stop here.
Introducing oplogtoredis: This application, written in GO, has a tailing cursor on the oplog collection which transforms every entry of the oplog into a Redis message. This way your Meteor instance doesn’t need to report the changes twice, and you’re robust for outside changes. Sharding is not officially supported yet. It seems like just a small code change but would benefit from some testing (https://github.com/tulip/oplogtoredis/issues/1). Once solved, run one instance of oplogtoredis per mongodb shard.
Was this option known to you before writing your C/C++ application? If yes, what benefit did you see to write your application?
To me your solution sounds quite similar to what I provided but has the disadvantage, that every Meteor application still has to process every message in the oplog, even though no web-client has a publication open on the collection the change origins from.
I saw that there was a solution that used redis, but I wanted to avoid introducing another technology to our infrastructure if possible as we have a small team that manages a lot of infrastructure. In our setup we have two Mongo clusters and they’re organized in a way so the Mongo cluster that has all the data requiring reactivity has the oplog configured and the other Mongo cluster that doesn’t require reactivity has the oplog disabled. In most scenarios the Meteor application would typically be subscribed to all the reactive collections regardless, so I’m not entirely concerned about isolating collections into channels. If anything I would want some intelligent way to detect and manage bursts in our reactive data set. This is something we could potentially augment into our oplog_consolidator in the future. Since we’re all C++ developers it would be easier for us to do it this way rather than learning GO.
Thanks for the heads up though. I also think your solution would be great for a lot of other people in the community… especially for people using managed solutions for Mongo.