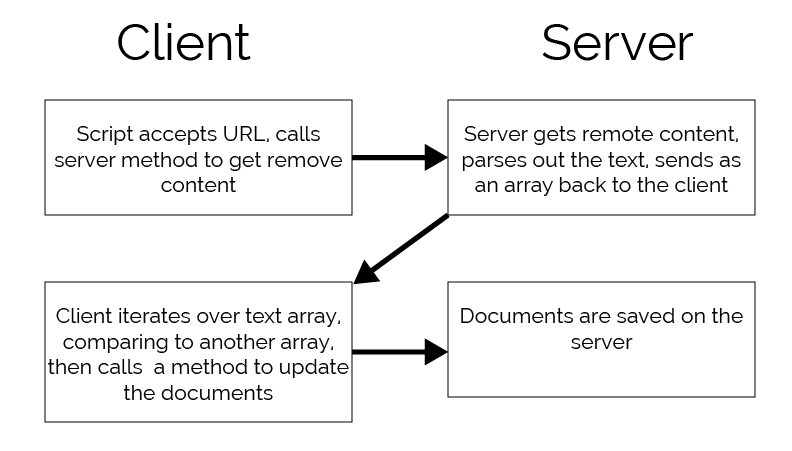
Hey Meteorites, I have a question for you. I have some scripts that do the following:
Fetch remove content on a webpage (via cheerio library)
Copy and parse all the text into fragments
Compare the text fragments against other text fragments
Link the resulting fragments if they match
The text comparison can be quite heavy on the server, taking some 6 seconds to compare 4,000 fragments against another 2,000 fragments. I’m thinking that one possible solution to this is to offload that comparing to the client, so the flow would look something like this:
Is this a good idea, am I doing something wrong/stupid, and if it’s a good idea, how do I go about it. Can I create and call client-only methods, same way I can call server-only methods?
e.g.
While I’m still interested in an answer, I cut down the processing time to less than .5s by changing the code structure, so it’s not really necessary anymore.
Glad you got your processing time down. As you scale, you will probably want to revisit this.
Some considerations:
Cost
User experience
Off-line support
Protection of code
Making it async and off-loading the work from your meteor servers to a separate work queue or micro-service will help you scale. It will cost more but it is better from a user-experience standpoint.
Client-side may make sense if the data that you are comparing against are already on the client. Compare performance/cost difference.
If you want people to be able to use the feature off-line then having the data on the client is required. But any code on the client will also be readable and able to be copied so that is a consideration if you use any sensitive algorithms.
That’s interesting, what would a micro-service look like, and is that something you would write with Meteor, or is the point that it’s a separate thing entirely?
I think of micro-services as “Unix-style” apps with simple interfaces which do one thing very well. The service’s API is your “pipe”. Basically just an internal API that your other services use, typically via REST.
You can use any language behind the interface; if you are doing something computationally expensive, you will want to optimize for multiple cores. This could be a single concurrent app or a load-balanced cluster of single-threaded processes, like node. Work-queues help isolate this decision; each worker can do its thing independently and you can add/remove workers as needed.
To try it out you could use something like Amazon API Gateway with AWS Lambda to do the work and deposit the results back in your MongoDB (or have your Meteor app poll a S3 bucket for a result).
Maybe I’m missing something but if you pass the data to the client, process it there, then send that process data back to the server it seems like you’re setting up a risk someone won’t muck with the data. If it doesn’t matter what the results are from the client then it’s fine but if it does matter then of course you can’t trust the client.
Still it feels like you are trying to re-invent something.
You mentioned comparing fragments and cheerio.
So is this some text comparison and scoring various matches etc based on html tags?
Cause we have fulltext mongodb search indexes for some basic level.
Or more advanced technologies like ElasticSearch when talking about fulltext search.
And if we are talking about relations of various tags and fulltext search based on these relations, than there is Neo4j.
Than u realize that question is not server or client, but identifying the smart way of crunching data.
As you did not described what exactly you are doing with data it is quite hard to help.
Thanks for the replies, I feel like I know a little bit more of what I don’t know
@alanning, what would be a good starting resource to start learning how to build micro-services? I feel like this may be the way to go, but don’t know where to start!
@shock, you bring up a good point… What I’m trying to do is check documents for plagiarism. To do so, I run a comparison of one document (could be a book, or in the cheerio case, a scraped online article) against a library of reference documents. In itself, this is already somewhat expensive as I mentioned, but I’m looking at getting more granular (ie look at partial matches, not just full-length sentences). So it’s not a matter of searching for one thing, but searching many things for many things. Do any of the technologies you mentioned handle that well?
That should help give you some context for this type of thing.
A micro-service is really just a secondary, internal app that your main app can communicate with. Kind of buzzwordy these days. Think, “separation of concerns”. So at some basic level the answer to where to begin is asking, “How do I let two apps communicate?”, or “How do I make a REST API?”.
As @shock eluded, there may already be third-party services that can help you do your text comparisons. If not, there are certainly technologies that can help you build your own (such as Elastic Search).
If you do just end up needing Elastic Search then you may be able to avoid setting up another API and just use their query interface. I personally found BulletProofMeteor’s intro to Elastic Search very helpful when learning about ES.
Expanding on the API topic a bit, to design an API you need:
A defined set of messages that your app can send to trigger an action
Something that processes those messages and does the action
A way to get the results back to your app
Simplest way is to use pretty much any web tech to create a REST interface for your processing service. They will probably already have standard ways to scale their offerings (ex. load balancing in front of node.js processes).
Once scaling becomes important, look into:
using Amazon API Gateway and Lambda
setting up a message queue (RabbitMQ, AWS SQS) with workers that do the processing
Lastly a note on practicality. If you are doing this for your employer or to learn the tech for fun, have at it. But if this is a start up or side-project for you, try to do the absolute least you need to do to prove or disprove what you are testing (usually, “will someone pay me for this service”). If MongoDB’s text search can do most of what you want, use it until you run into performance / cost issues. (Lean Startup is a wonderful book.)