We just tried migrating a Mongo database into MongoDB atlas and ran into all of these same issues.
Our database is literally 2 MB at the moment. Yet, we got charged for 1.139GB of data transfer two days ago and 2.425GB of data transfer yesterday despite barely anyone using the app.
When we opened a support ticket this is what we were told:
As is described in the Data Transfer section of the Billing documentation, we charge for each hour of Atlas server usage only when servers are active (and at a reduced rate when they are subsequently paused). A group with no deployment (zero servers running) will not incur any charges. The hourly cost per server varies based on instance size, disk speed, region in which the instance resides, and the cloud service provider the cluster is deployed to. There is also a baseline level of communication between the nodes in your deployment that is used to maintain high availability, which will also factor into your Data Transfer costs even if you have no active operations being performed.
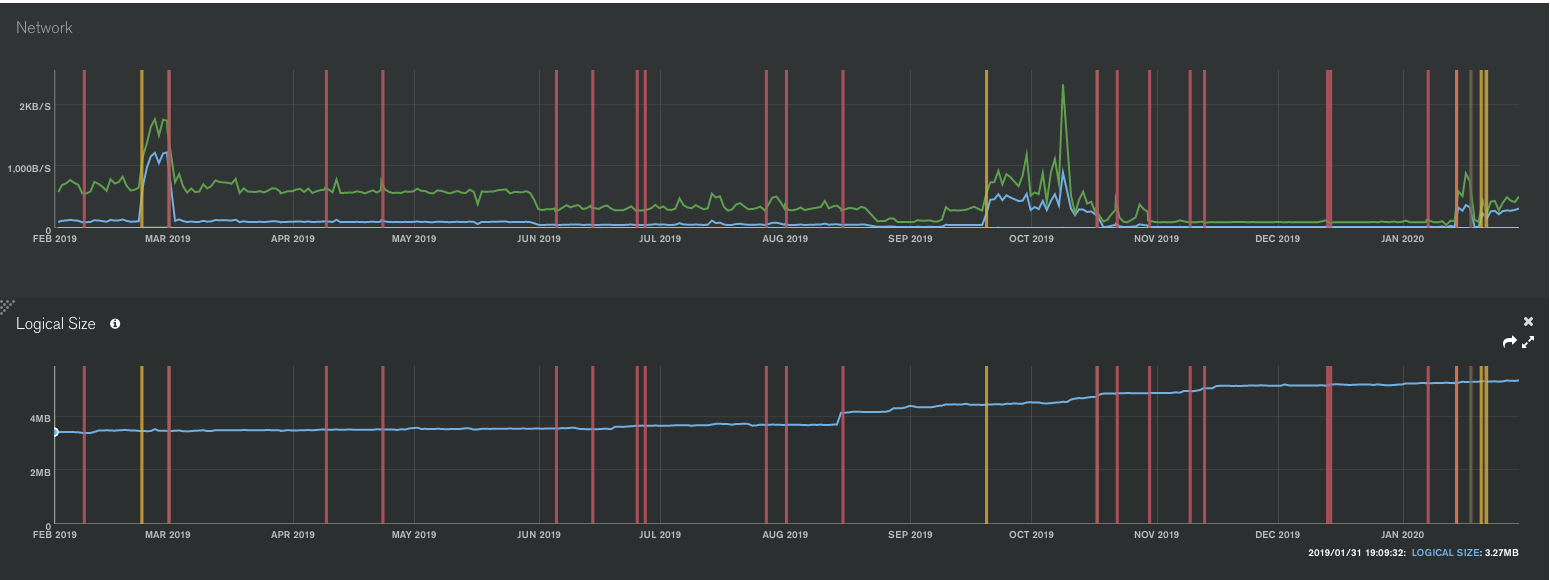
Within MongoDB Atlas, we have various tools that are monitoring each cluster and are communicating with our Atlas application instances that are hosted in AWS in the us-east-1 region, which accounts for the ~13KBps rate of network activity that you can see in the YOUR_DATABASE Network metrics for yesterday when the cluster was active. Accumulated over the course of 24 hours, this adds up to about ~1.139GB of data transfer (which matches the usage shown in the project’s Usage Details).
As far as I can tell, we seem to be getting charged for both the servers in the replica set communicating with each other, plus the monitoring tools that make the Atlas dashboard possible. No wonder y’all have seen such extreme amounts of data usage.
Excuse me, I don’t know any experience with Mongo Atlas.
The price for create new one Cluster is for one database name.
Or we could create more database on One cluster???
Yeah, that is about what I experienced. I’ve tried out all the major MongoDB hosts and all have their flaws/extra costs. As I said in my OP, I’ve found the best solution so far is to roll your own replica set on DO, at least depending on your project, DB size and client. Some clients are willing to eat the added expense, which is fine, but the project I was working on above had some pretty large data sets (financial data) that would cost several hundred (or more) a month on most of these services. It didn’t really take that much effort to get it running and you get so much storage and bandwidth for cheap. You don’t even have to forego a good management UI as Mongo’s Compass App works with all Mongo deployments. I liked Atlas’ features, but their customers must only be large companies with all that added expense vis-a-vis the data transfer fees.
FWIW, my production app switched to Atlas in January. We have a specific use-case where we need to crank up to their higher performance servers at times (something we couldn’t do on Compose).
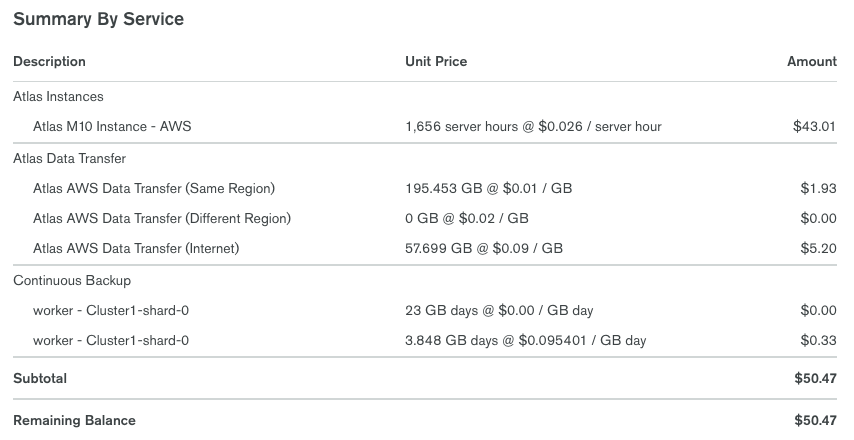
I do see the AWS Data Transfer (Same Region) and (Internet). The “Same Region” last month was 193.71GB @ $0.0100 / GB = $1.94 for the month (pennies a day). The “Internet” was 0.06GB @ $0.0900 / GB = $0.01 for the month. It’s always around this same cost each month. My app doesn’t have a ton of data transfer, so this seems reasonable.
My production databases is 429MB. Total disk usage of the cluster is 5.8GB. Running on the M30 size.
Just checked my Atlas and found the same issue for last month as well. An app, that is used only by me sparingly, averages 3.5GB transfer per day.
I’m thinking if this isn’t related to oplog by a chance.
Yes I tried scalegrid, I do have services/support with AWS etc. i am always happy with all the support i get from various vendos
Scalegrid is the worst of all, I do not think they support from U.S, based on the response, attitude i get from Scalegrid.
I was charged more than $330.00 , i was cheated by Scalegrid at the time of database creation i was informed it is $120, i created shard cluster, nowhere it was mentioned they will be charging $190 per
totally misleading and fradulent also i asked then more than 1 week ago, still there is no response, Also i asked another question response. It seems reviews about scaledgrid are misleading, I might initiate fraudulent action against scalegrid with my credit card company .
Scalegrid proudly says they provide 24 hour support, i think they are trying to say that there is 24 hours in a day.
First provide atleast 8 hours say, they should be ashamed to say they provide 24 hour service
Atlas charges you for all your traffic, so if you have a replica set you get dinged for all the traffic between all those servers. If you have a large DB (mine was 4GB at the time) it can cost you a bundle. $200-$300 monthly bills on small projects just didn’t make sense, not even for clients. I ended up rolling my own Mongo servers on DO, which was much less expensive, but a management nightmare. That is what finally soured me on Meteor and Mongo.
I ported all my projects over to Firebase/App Engine now. Pure Node on the backend, or serverless. React on the front end. While it’s more expensive than DO for running App Engine servers, it’s so much easier and cheaper on the DB and authentication side of things. Plus their serverless solution has improved a lot and free ingress and egress in the same region. My DB is now a combination of a server(s) running LokiJS backed by Cloud Firestore. Super fast queries.
I like Mongo a lot, but could never find a hosting solution that could deal with a DB of any size. It’s great for small project with < 500MB DB, but anything larger and you get killed on network traffic. Any they def don’t care about the little guys, mainly going after large corporate clients.
A quick note for any future people who end up here – it does seem to be the specific Atlas/Digital Ocean/Meteor cocktail that screws things up, and Atlas’s support is clueless regarding what’s happening (and doesn’t seem to realize that something strange is happening).
My experience was a series of 5 meteor apps (hosted on Digital Ocean), running off of a single mLab database (hosted on Azure). The standard data output was 50 KB/s.
I transferred to an Atlas database (hosted on AWS), and with no other changes to my apps, the data output jumped to 1.3 MB/s, and stayed there. No changes to my application usage, just 26x the reported traffic.
My solution was to migrate my apps from Digital Ocean, over to AWS EC2 instances. As it turns out, this solved the data-output issue – I’m running the same 5 apps, with the same load, and the database is back to reporting roughly 60 KB/s of outbound data.
@csiszi
It really depends on the scale of your project and the type of queries. If, for instance, you have a lot of reporting, data drilling, big data, global reach etc you don’t want to run all those queries on your primary DB.
If your project is small, let’s say up to 5000 users you can just hook up Atlas in the same region (literally meters away) with your Galaxy deployment. For large projects you would be looking to data center architecture solutions like AWS EBS in front of Node servers and EBS in front of your Atlas VPC (you can read here about it: https://docs.atlas.mongodb.com/security-private-endpoint/ and you can also check on the network peering).
It is less important who is your Mongo provider as long as your MongoDB can sit in the same “LAN” with your Meteor deployment and have the features you need (like Oplog). Sometimes people complain about one provider or another without considering that their Meteor Node is running in Australia while the MongoDB was “transparently” deployed in Ireland with some … feasible and fairly-priced provider.
If you use BI or IoT, Atlas would also be your best option with their Atlas Stitch.
I think the old Meteor 1.0 question “Where should I DB” is today something more like “What exactly do I want to achieve”.
Large tech companies have a full department to deal with the architectures (infrastructure and DB). With Meteor and small teams we have to think that through ourselves.
Now … to answer your question … it is safe, it is recommended and it is advisable to anticipate your exact demand for computing now and in the future. If you do Galaxy in AWS, of course you will put your Atlas in AWS too, that is the only thing that really matters.
Thanks for the long answer. I expect maximum 3-4000 users so it’s definitely not large. My concern was that some folks reported a bug which caused extreme traffics for the mongo db even if the project was really tiny.
For another project I used compose, but they’ll end supporting “mongo classic” deployments in June.
I am attaching for you about a year of data from my Atlas on the project I work on. I only have test users, data is growing every months (this is a social network with posts and chats, contacts etc). But I want you to see that traffic volumes are very very small no bug, no leaks, I get exactly what I consume.
Something also to keep in mind is queries. Some people pull a lot of data (by mistake) map through it to get thousands of ids to use them to query the DB again - instead of aggregations and projections. All complex queries need to be aggregated on DB and only the results returned ( and convert into traffic).
Other people use some FileFS of GridFS etc like in-Mongo File storage and store images, video and large files. So, if you have a hero image on your home page and everyone gets it from your MongoDB, imagine the traffic.
Again :))… I was long but I am trying to say that it was probably not a bug … Just trying to raise your confidence … I don’t work for Atlas
Atlas + Galaxy works but you have to be a bit careful with traffic because of the extreme expensive traffic pricing. Extreme accidental traffic bit me once. Check every .observe() call to be sure you don’t accidentally observe something big. Or don’t observe at all - instead, do whatever your observe() would do next to write calls instead. With observe, every write will be mirrored as traffic to observing app containers. Be sure to have monitoring and alerts for daily traffic switched on. And double-check you’re deploying to the same region!
Disclaimer: We’re part of the MongoDb Startup Accelerator Program though they manage to f$ck that part up (we never got any credits or where on any official comms until I complained to them last week - they claim they had experienced a problem “with our automated notifications system” and thus they didn’t know we never received any notification). That’s just as a side story.