I’ve found it already - logging in. If I remove publications entirely, it works like a charm, even with hundreds of users logging in at once.
3 Likes
How is it the other way around? Did you try to remove the logins, and keep just the publications?
What do you mean by “remove logins”? If no users are logging in, the system is stable and performs well.
1 Like
I’ve often seen ‘login’ as the biggest spike when viewing our methods in Monti but never investigated too much. Could it be that login is just blocking everything else while it’s running? I’m not familiar with how how it’s implemented but in Monti it shows as a method so seems likely that by default it would block. Might there be a way to make this method unblock and allow the rest of the system to keep functioning while processing a login?
Failing that could login be handled in two stages. So in the first stage you load only the absolutely necessary stuff like permissions/roles which loads a ‘logging in’ page and once those subscriptions have completed it moves you to the main view which then triggers the rest of the subs ?
1 Like
Do you have a lot more than 300k lines of code? Because that’s how much we had when we went through it. That was just two people BTW, not a large team!
1 Like
You could build a test version of your app that requires no login at all. Then you could use selenium or a similar product to simulate load created by simultaneous users, that subscribe data just like real users would.
2 Likes
Yes, it could be. Login with username+password leverages bcrypt, which is by design heavy on the CPU. Given that Node.js is single threaded, such a long operation leads to blocking the main thread. Theoretically this operation could take place in worker threads, or even in a remote service that leverages multiple CPUs, but no such thing is built into Meteor.
1 Like
From this discussion and those APM screenshots it sounds like you need to reduce the amount of documents being subscribed to, and ideally the overall number of subscriptions. This really seems like a data model and/or over-subscribing problem that there isn’t some magical fix for.
It’s hard to give a real solution because we can’t see your full data model and we can’t know your business requirements for why you may need to load 1000+ documents on pageload, but I will say that there is probably a better way to handle this. I would step back and try to re-asses what data you really need to load, and how the UX would be impacted if some things were not loaded immediately. There are very few legitimate reasons to need that many documents subscribed to when a user logs in.
I would try to think about what data loading can be delayed until after the user does some interaction, what data can be paginated or loaded in segments, what can be lazy loaded on demand and not upfront, what can be moved to polling instead of live subscriptions, etc. You may even need to change your UX a little bit to accomodate what you’re trying to do, but I just don’t see any way you’re going to magically get thousands of documents subcribed by each user without a serious change in your data model.
The only thing that is easy to try and may have a big impact is the cultofcoders:redis-oplog package. If you haven’t yet I would definitely get a preprod environment up, populate your preprod db w/a prod db dump so that you can recreate the exact same issue your users are seeing, and then try enabling redis-oplog instead of Mongo oplog. It’s simple to try and may yield good results, if not only a few hours wasted.
4 Likes
There’s in the meantime a new fork of the original cultofcoders:redis-oplog: it’s the ramezrafla/ redis-oplog that introduces new major performance optimizations.
Results
- We reduced the number of meteor instances by 3x
- No more out of memory and CPU spikes in Meteor – more stable loads which slowly goes up with number of users
- Faster updates (including to client) given fewer DB hits and less data sent to redis (and hence, the other meteor instances’ load is reduced)
- We substantially reduced the load on our DB instances – from 80% to 7% on primary (secondaries went up a bit, which is fine as they were idle anyway)
I would definitely give this a shot if I had a major scalability / performance problem with Meteor pub/sub.
7 Likes
Do you store any custom data on the user objects? If you store lots of data on the user object then meteor core pulls it all from the db when a user logs in: Meteor Guide - Preventing unnecessary data retrieval.
I provided a work-around for this in Meteor 1.10: https://github.com/meteor/meteor/pull/10818.
3 Likes
Thanks @peterfkruger
@radekmie our version of redis-oplog was specifically designed to handle large loads. Give it a shot (Note: the only thing missing is geospacial updates, which we will look into shortly).
Most production apps put a db cache layer between their application and db, our redis-oplog does that natively, caching data subscribed to. It should be an easy swap with the existing redis-oplog.
@wildhart,
You are right, so many data pulls occur. Our redis-oplog caches user data, so no necessary data pulls.
4 Likes
does it work with redis cluster? I’m using cult-of-coders/redis-oplog, it comes with redis 2.8 and it doesn’t support redis cluster.
I’ll do another round and some summary.
@marklynch
I’ve often seen ‘login’ as the biggest spike when viewing our methods in Monti but never investigated too much. […]
So in the first stage you load only the absolutely necessary stuff like permissions/roles which loads a ‘logging in’ page and once those subscriptions have completed it moves you to the main view which then triggers the rest of the subs ?
- We can see that as well, in many of our apps. But I think it’s not really true - it’s just how the APM works and it kind of “merges” the following subscriptions and method calls into the login. Or at least it looks like it in our case.
- That’s something we went with and it really helped. I’ll write a little bit more at the end of my post.
@a4xrbj1
Do you have a lot more than 300k lines of code? […]
I was curious myself. And we are almost there: 335k lines in total, 295k without blank lines and comments.
@peterfkruger
You could build a test version of your app that requires no login at all. […]
Login with username+password leverages bcrypt, which is by design heavy on the CPU. […]
- It won’t work as it’d either require rewriting a big chunk of the app or calling the login method automatically, that doesn’t really make sense, as that’s exactly what Meteor does with login tokens.
- I’ve been working with Meteor for almost 6 years now and I’ve never seen Bcrypt taking significant amount of CPU, even in lightweight apps with thousands of users logging in at once. But maybe it’s just me.
@efrancis
From this discussion and those APM screenshots it sounds like you need to reduce the amount of documents being subscribed to, and ideally the overall number of subscriptions. This really seems like a data model and/or over-subscribing problem that there isn’t some magical fix for.
We know that, but as I said, we’d rather look for anything that could help us in the meantime. And no, we weren’t looking for a “magical fix”, but rather a temporary workaround. In the end, loading times are not a problem – unresponsive servers are.
@wildhart
Do you store any custom data on the user objects? […]
No, not much. Only the “usual Meteor stuff” and some information about the tenancy.
@ramez
@radekmie our version of redis-oplog was specifically designed to handle large loads. […]
As I said, we’re already planning to use such a package and yes, we’ll try yours as well. Thanks for sharing!
I think we’re fine, at least for the time being. What helped was some kind of scheduling and throttling of the publications. To be exact, we have quite a few places where we do a couple of Meteor.subscribe calls at once (up to 15!). Before we’ve waited for all of them to be .ready(). Now, we do not call the next subscribe as long as all the previous subscriptions are not ready. It made loading times longer, but spreading it like that made our servers responsive at all times.
Thank you all for your time! I hope the entire community will benefit from the ideas (and packages) shared in this thread!
3 Likes
So it wasn’t the logins after all – that’s comforting to know.
1 Like
I don’t like the Meteor docs/tutorials. It only tells developers to fetch data by using pub/sub model. It’s real-time, it’s easy but it comes with a cost. It’s not a silver bullet.
People use pub/sub every where, it’s never been a problem in dev environment. But when it comes to real life, when the app has hundreds of concurrent users online, the server goes crazy. Then people go to blame Meteor, get angry and try to move to other frameworks.
6 Likes
I second to that. However, in this very instance it wasn’t the documentation to be blamed. If I understand correctly what happened, all was fine, there was just a bug (or there were many) in the client that had lead to a denial of services of its own app:
1 Like
I second that. Surely you need some core data about payment status (if it’s a paid app), session vars (to load user specific UI-features) etc. and whatever data is needed to show the first route without any problem (aka your main landing page after login).
From there onwards you load what you need which goes back to my earlier point of using mostly methods to pull the required data when needed.
Only what needs to be observed to trigger automatic events should be held in pub/sub (in our case for example the status of our backend features, to handle maintenance phase or disabling features when errors happen without taking the app completely down).
Just my two cents worth 
1 Like
Looks like you could make use of that new native this.unblock() for publications. Didn’t I read about that being a new feature of the latest Meteor?
Goodness… how many containers is that? Galaxy has size 12x “Dozen” containers now. As everyone has stated, vertical is better than horizontal. Especially when using native oplog-tailing. I might reduce containers and increase their size. Or are you already doing that and you’re trying to extinguish the problem with brute force server power?
Also it looks like in an eight hour time frame you have containers dropping in and out (in the Memory Usage box). Are they crashing because of this issue?
1 Like
Yes and no. It wasn’t a bug, it was a deliberately written code, that worked for us for years. But as the app grew, it had to be throttled to make the server handle it without hanging for too long.
The app these problems occurred has basically one view. All of the others are used rarely (some once per day, others once per week, or even month). It is very complex for business reasons (sigh).
We also thought about this. But as the problem was causing the CPU to spike to 100% for a couple of minutes, the server wasn’t able to notify anyone about it. The only way to know that anything happened (other than looking at the APM charts) was the Galaxy notifications.
Well, not really - we do want to wait until these all publications are ready.
I think we had ~18 at this moment. And these were the biggest ones we could get at that moment: 8x (12x were introduced later).
Exactly that; I wrote it already in one of my previous posts.
Nope, these are just gaps in the chart data, caused by long-enough CPU blockage.
2 Likes
We’r using Vent(part of redi-oplog) for real-time updates when a message should be dispatched to multiple users directly without storing in DB. Before that we had pub/sub and amount of “update” events killing our CPU.
We have the similar picture:
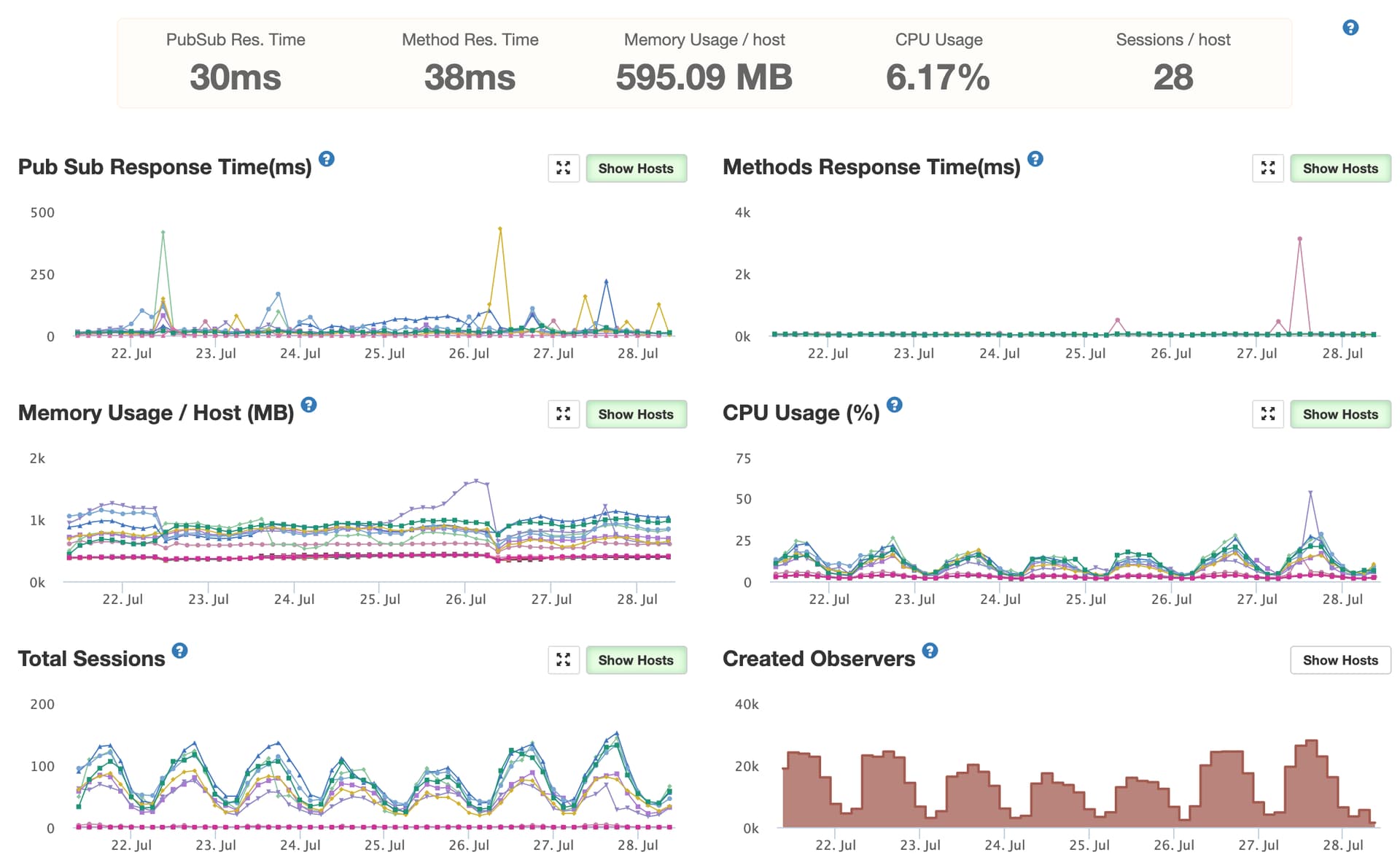
1 container for admins workload (reports and others “heavy” tasks)
7 for other clients
and another 8 for high availability in different region.
PS Not in galaxy
2 Likes