Intro
We have a problem. For a couple of weeks now, one of our app that heavily relies on real-time features has stability problems. Let me walk you through all of our findings, ideas, experiments, and questions.
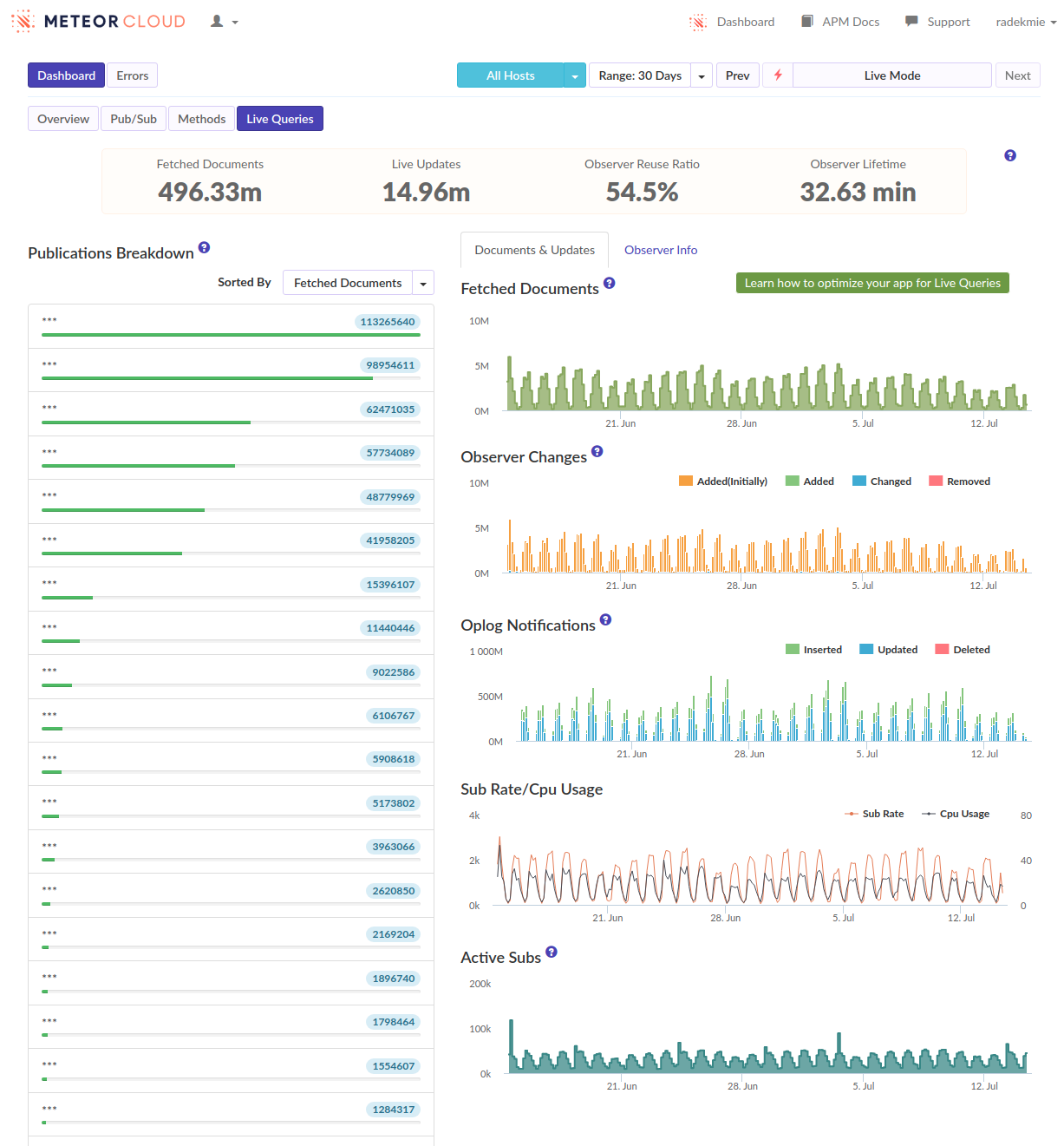
Background
The app has to be real-time and any latencies may cause actual business problems. (Nobody will suffer from it, but hey, you get the idea.) The amount of data is let’s say moderate in terms of size (less than 1MB per user) but highly scattered (hundreds of documents; most users will have between 200 and 1000 documents loaded). The data itself changes rather rarely during the day but often occurs in batches.
The usual way of working with the system is to start it in the morning, leave it open through the day and close in the evening. About three weeks ago we significantly expanded our userbase. Most importantly, many of the new users were starting using the system during the day, not in the morning.
The problem
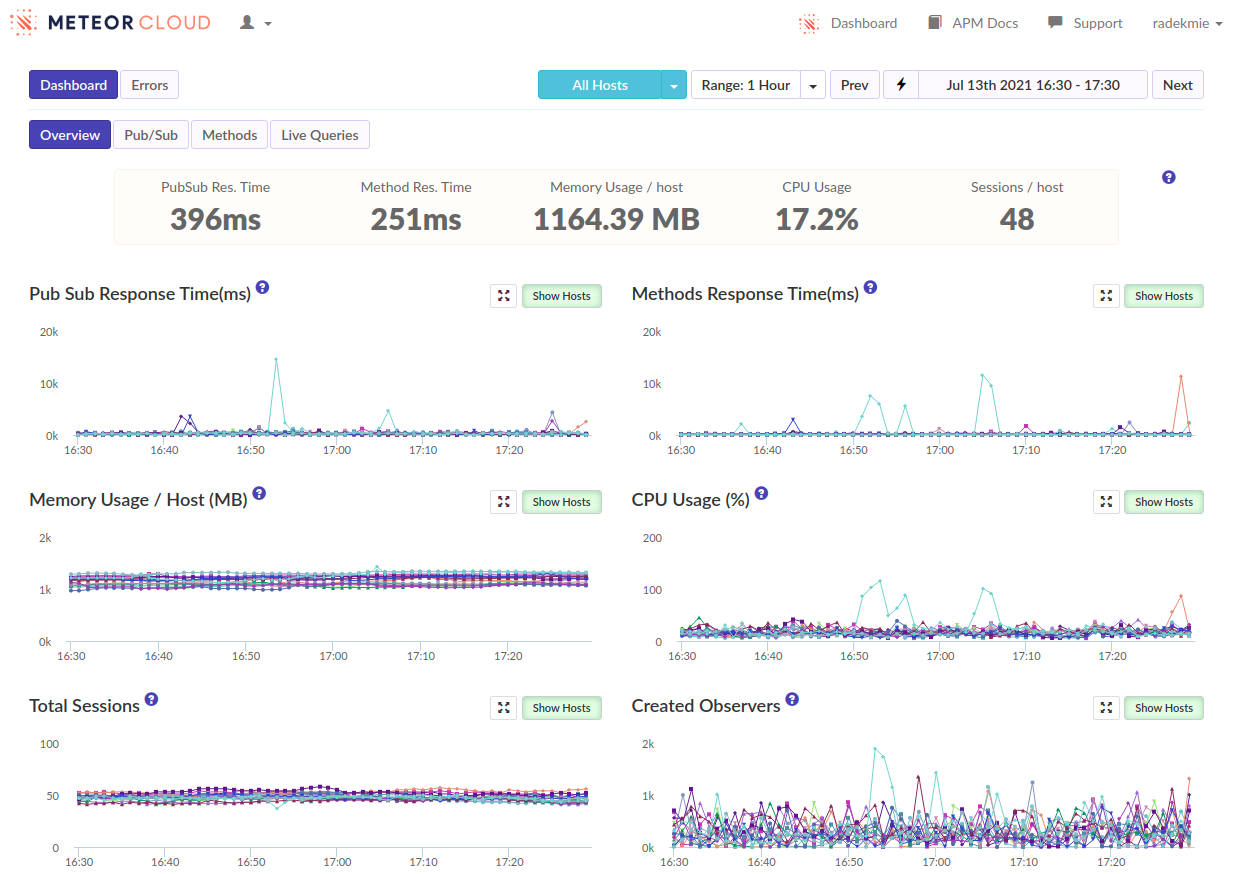
What happens is that any user loading the app load clogs the server for a couple of seconds. It’s not a problem on its own. (The CPU is there to compute things, right?) Well, in this case, the server is barely responsive if a few users load the app at once. Then, after a minute or two everything is fine again.
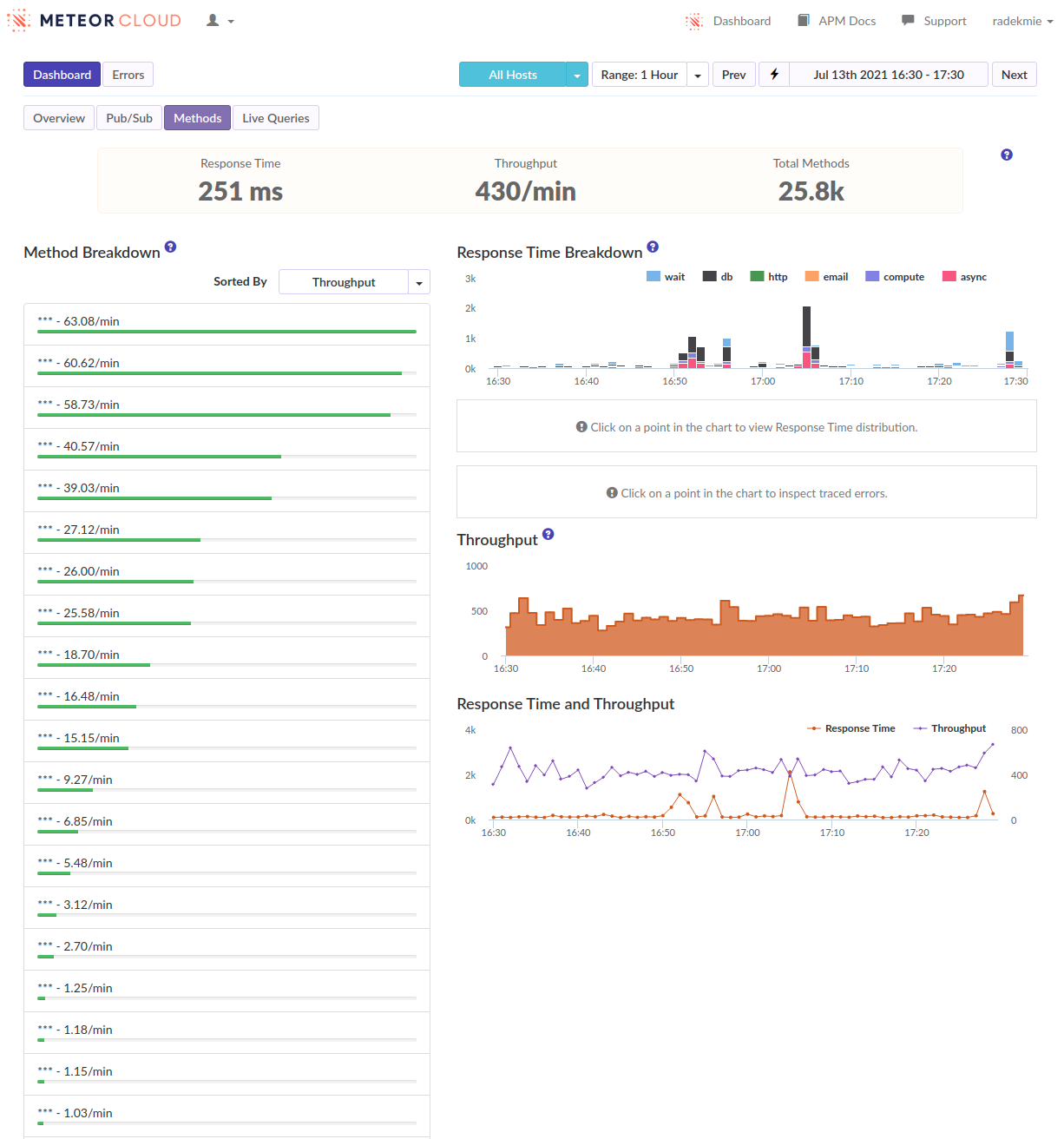
Phase I
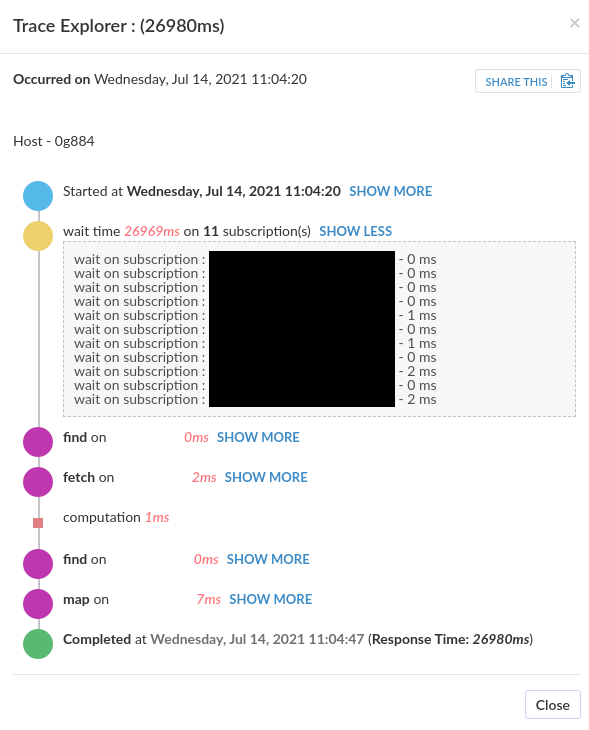
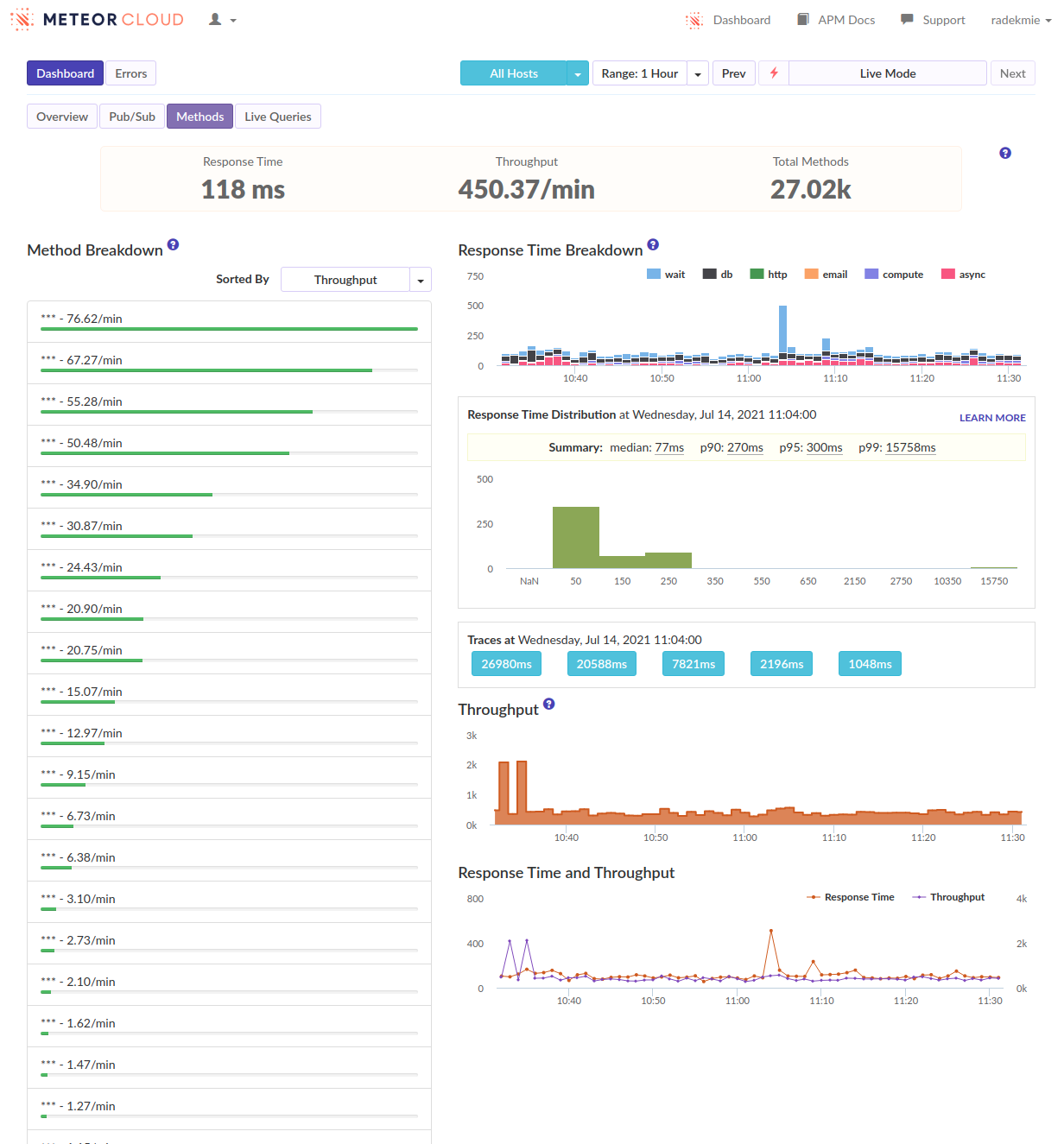
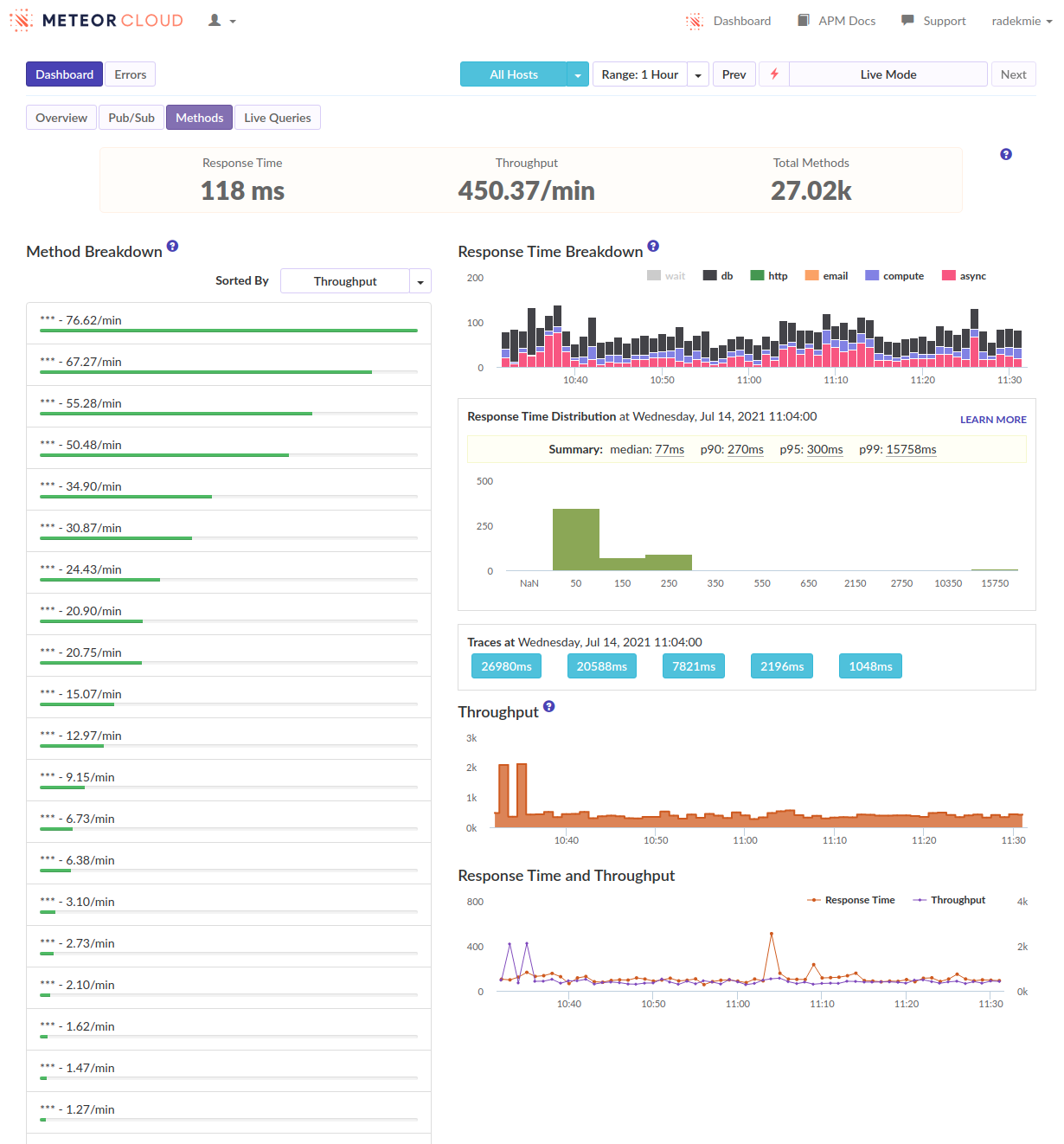
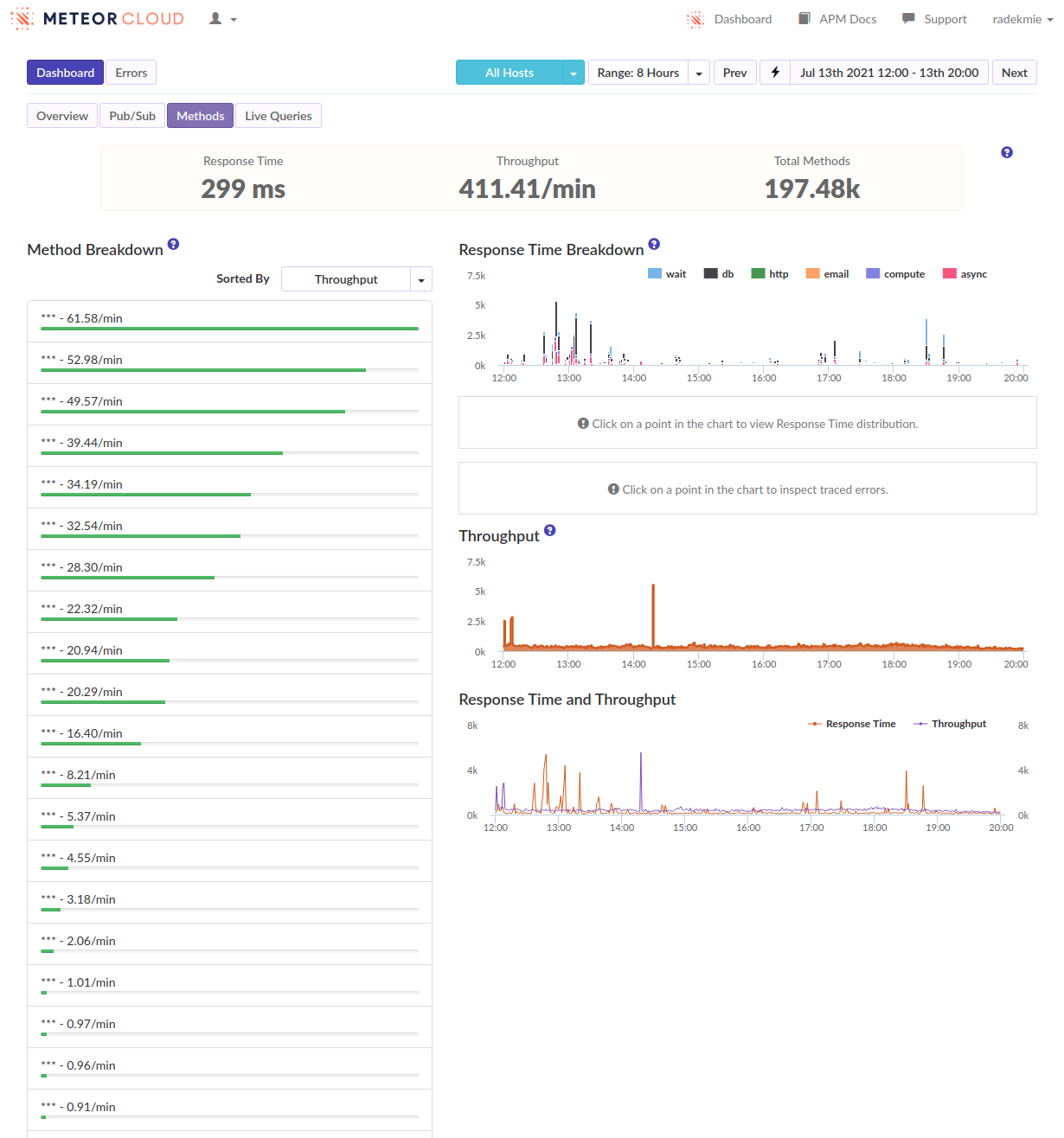
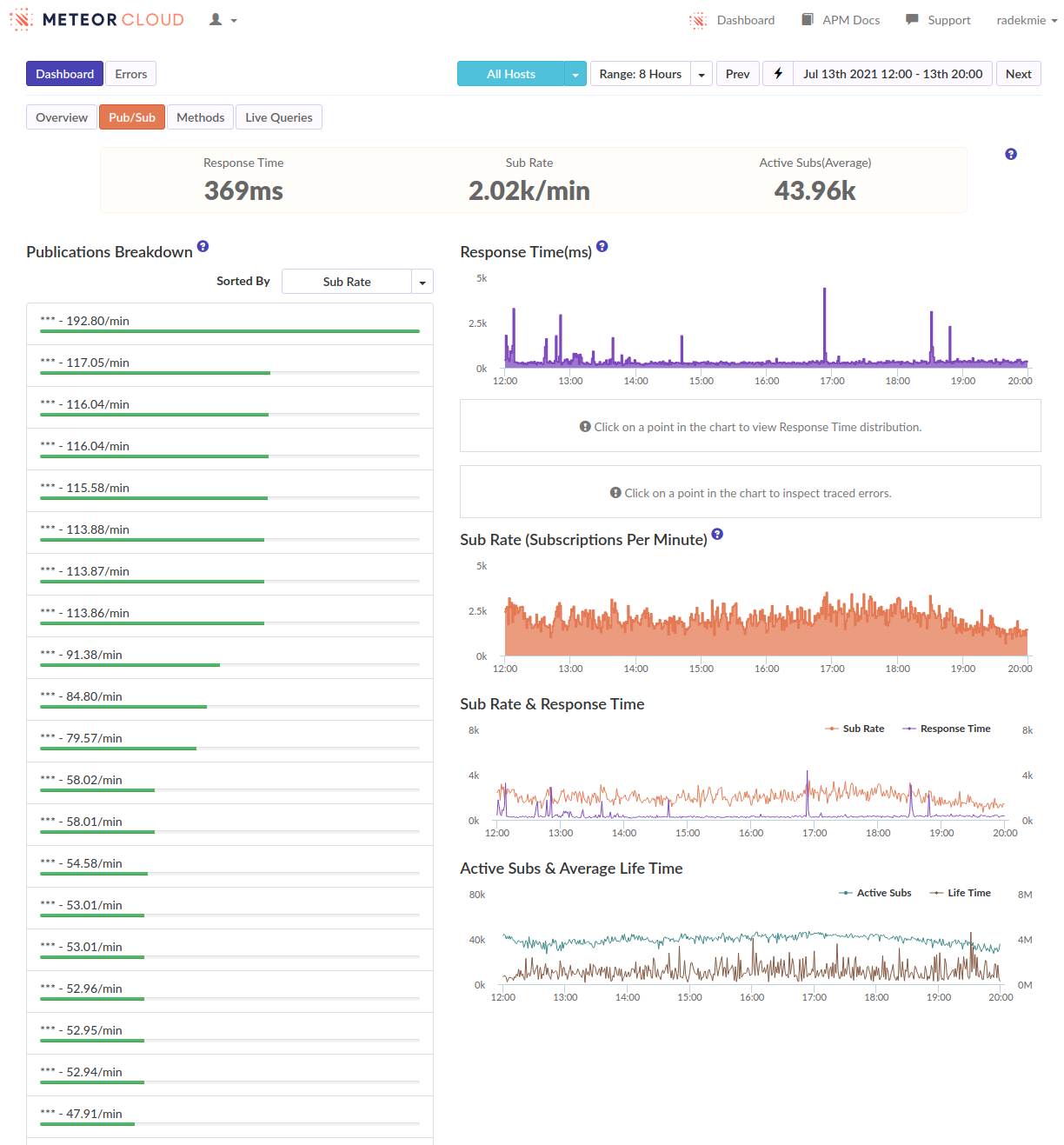
At first, we started profiling the production environment to see what’s happening. Unluckily, there was… Nothing. Nothing stood out. There was just a ton of dense series of short function calls. We quickly correlated these with users logging in. It looks like this:
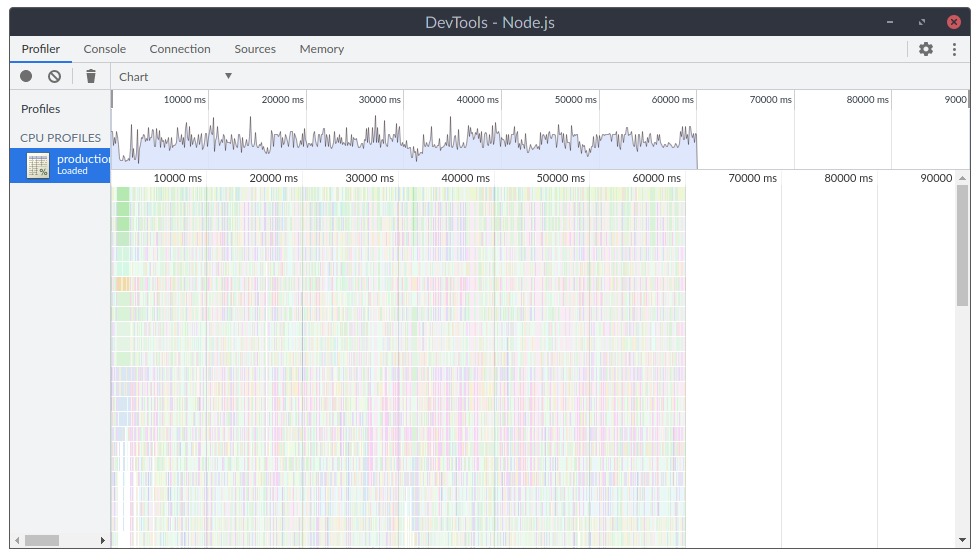
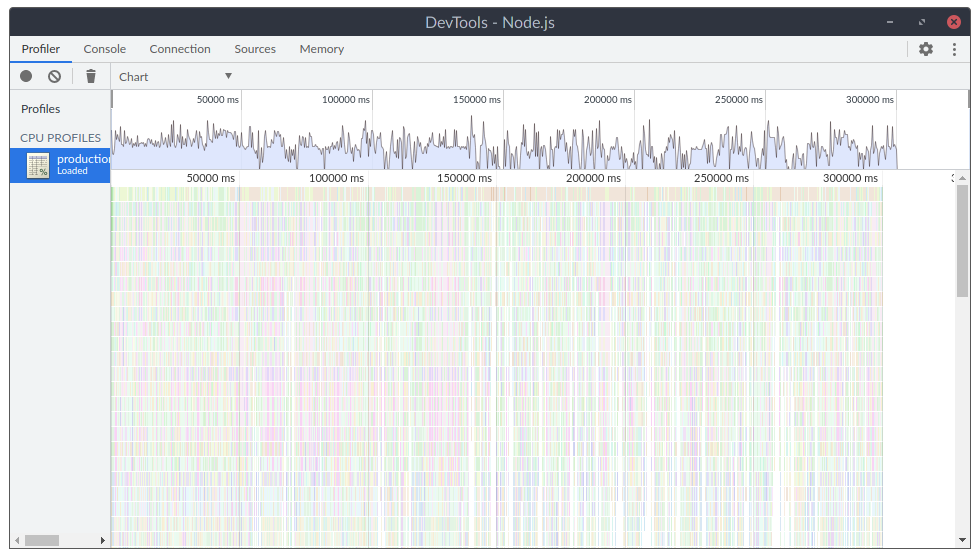
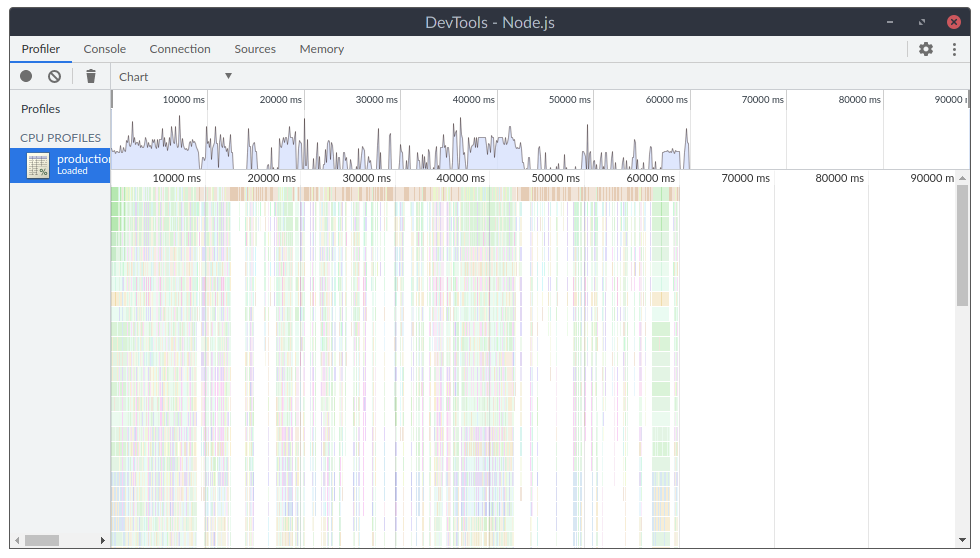
During this phase, we’ve focused on reducing the overall number of documents a user needs at all times to make these logins less disruptive. We’ve reduced it slightly, but without any significant results.
Phase II
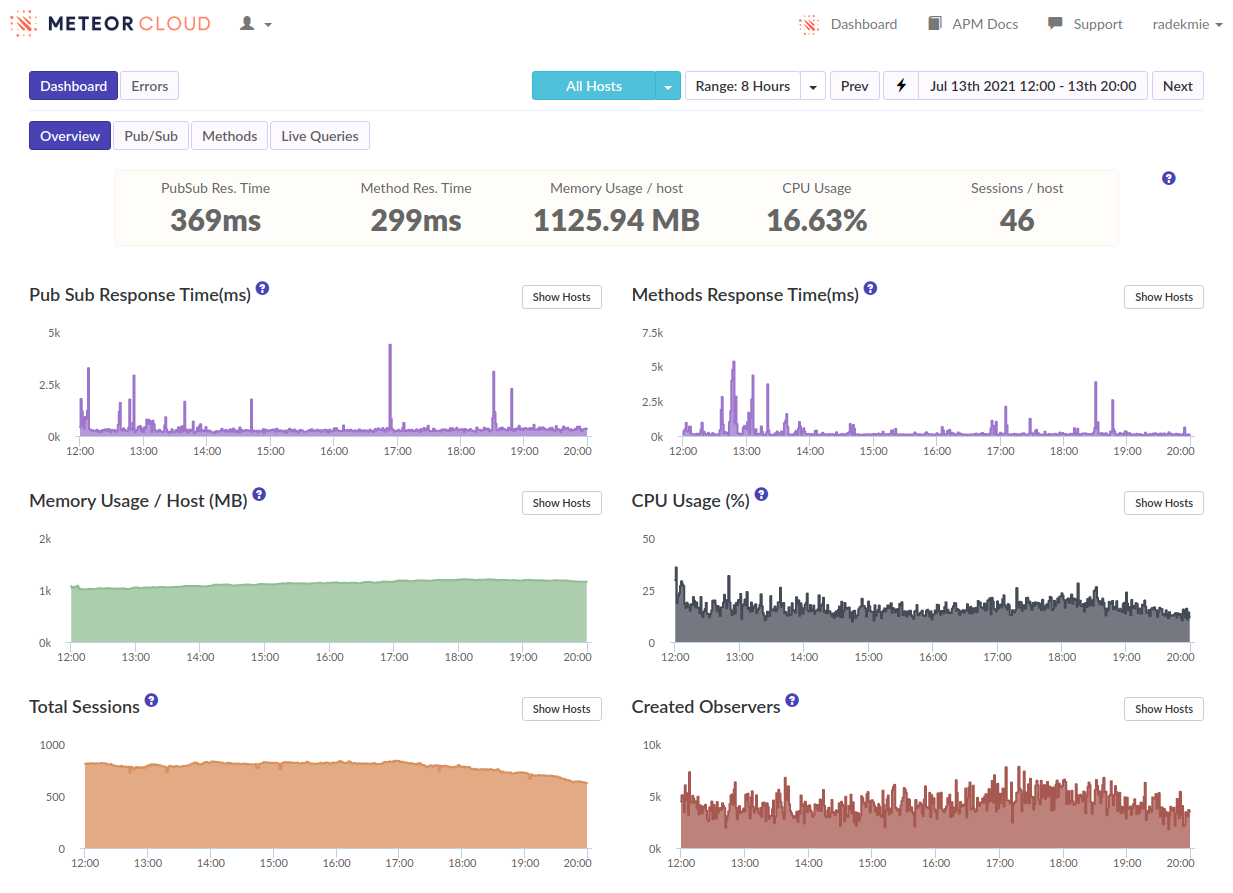
We thought that maybe we could optimize the server “in general” to have better performance. We knew it won’t help but it bought us some time. We’ve managed to improve the overall app performance significantly, but the logins were still a problem.
Phase III
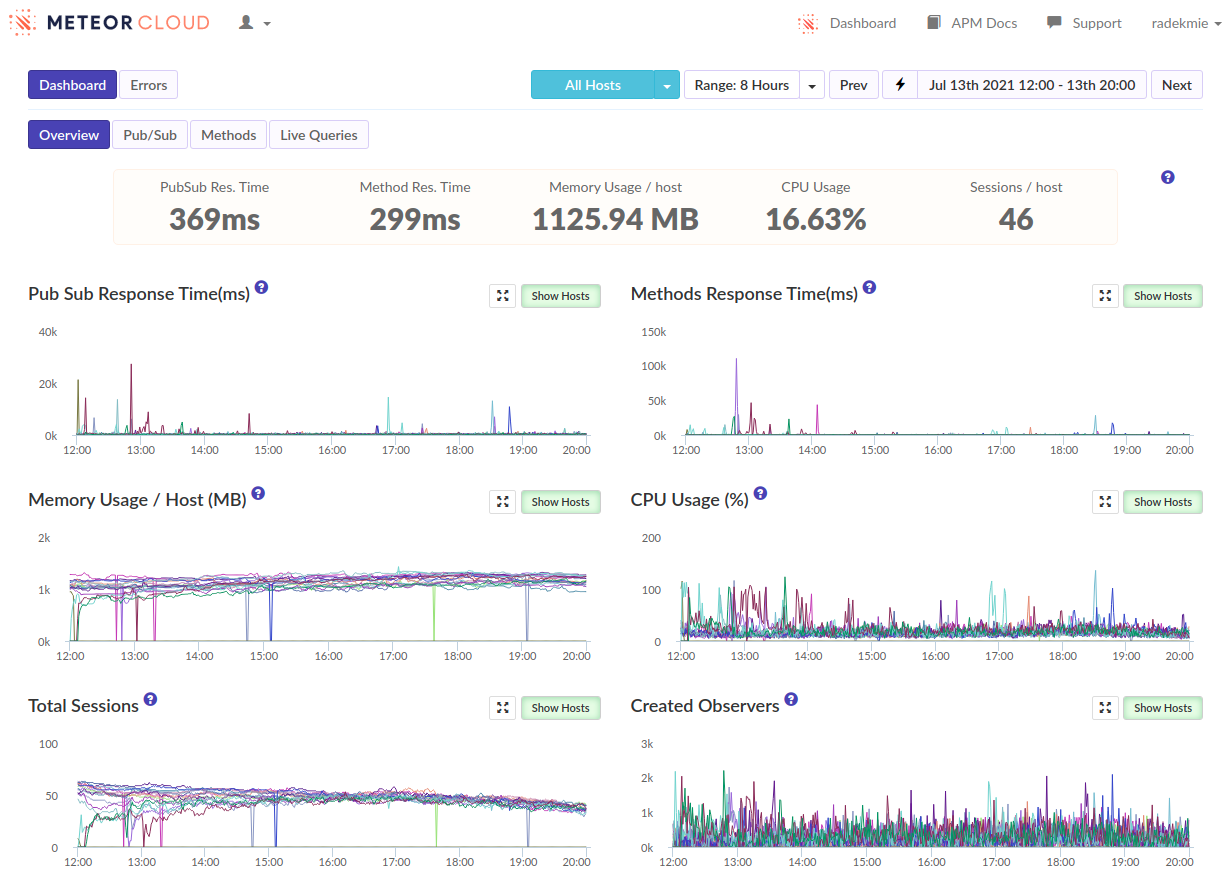
We cannot mitigate the problems, so let’s think about how we can make them less harmful. To try that, we scaled down our containers but increased their amount (we’re hosted on Galaxy). The idea was that a clogged server will impact fewer users, as they are more scattered across the machines.
In the end, it didn’t help. Smaller containers were more fragile and as a result, the number of affected users was more or less the same. (We had far more “Unhealthy containers” alerts though.)
Separately, we’ve experimented with “scattering” the publications by adding random sleep to each of them. A 0-250ms sleep to each of them helped a little but didn’t fix the problem. Additionally, it increased loading times significantly.
Phase IV
Until now, we focused solely on changes that required no business changes and were fast to try out (let’s say less than two days of work). As the problem persisted, now we wanted to think about anything that could help. What we’ve come up with:
-
Use
redis-oplog. We had a problem with setting it up as it conflicted with some of our packages. We skipped that, as it’s probably not going to help us at all – there are no problems with updates, but with the initial sync. If you are curious, the errors were dominated by this one:Exception in addedobserveChanges callback: Error: Can’t call yield in a noYieldsAllowed block!
-
Normalize long arrays. As every multi-tenant system, we do store our
tenantIdon the documents. But we also have a feature letting different tenants sharing some of their data. In such cases, we storetenantIdsinstead. It all worked great for years but with the new wave of clients, we’ve noticed a couple of large tenant groups (with more than 50 tenants; one with more than 100). It’s not a problem on its own – transferring 400 * 100 IDs (Meteor IDs) every time you log in, is. Especially when the actual data makes less than 30% of the transfer. ReplacingtenantIdswithtenantGroupIdnot only got rid of a couple of GBs of data and made the app load faster, but it also made adding new tenants almost instant. -
Reduce the number of documents by merging them into larger ones. This one was suggested by @jkuester (thank you again!), as it helped in one of his apps. We are still investigating whether we actually can apply this to our case, but hopefully it’ll reduce the number of published documents even further.
-
Experiment with DDP batching. I’ve been observing meteor/meteor#10478 for years now. Actually, it all started with meteor/meteor#9862 and meteor/meteor#9885. Since the beginning, I was sure that it’s an important change, even if problems with Fibers will get resolved - either by fixing “Fiber bombs” or getting rid of Fibers completely. I do because it helps in cases where there are a lot messages, but all of them are relatively small… Hey, that’s exactly the problem we have now!
To see whether this PR helps, I applied changes directly into the project and profiled the app in different settings. Overall, it helps. We still have a problem, but it’s better. I profiled the app with three parameters:
- Batching interval (
_bufferedMessagesIntervalin the code;0means no batching). - Number of users logging at once (1 or 4).
- Whether our implementation of
reywood:publish-compositeis enabled (we’re migrating back to this package soon). The number of documents published with and without it is similar:- With: 1 + 1 + 2 + 2 + 3 + 4 + 4 + 4 + 5 + 6 + 7 + 7 + 18 + 19 + 28 + 42 + 62 + 217 + 222 (654 documents in total).
- Without: 1 + 1 + 2 + 2 + 2 + 4 + 4 + 4 + 5 + 6 + 7 + 7 + 18 + 19 + 28 + 55 + 61 + 62 + 217 + 222 (727 documents in total).
## Batch Users Blocking PublishComposite? 01 0ms 1x 1200ms No 02 10ms 1x 990ms No 03 20ms 1x 940ms No 04 50ms 1x 930ms No 05 100ms 1x 970ms No 06 0ms 4x 3050ms No 07 10ms 4x 1740ms No 08 20ms 4x 1950ms No 09 50ms 4x 2030ms No 10 100ms 4x 2310ms No 11 0ms 1x 1820ms Yes 12 10ms 1x 1850ms Yes 13 20ms 1x 1830ms Yes 14 50ms 1x 1850ms Yes 15 100ms 1x 1720ms Yes 16 0ms 4x 4000ms Yes 17 10ms 4x 2880ms Yes 18 20ms 4x 3500ms Yes 19 50ms 4x 3050ms Yes 20 100ms 4x 2890ms YesAs you can see, changing the buffering interval makes little difference, but the batching itself significantly helps. It helps much more with
publish-compositedisabled – that’s expected, as our implementation is synchronously waiting for related documents, effectively getting rid of batching entirely.I’ll comment on the PR with a link to this thread. Hopefully, we can get it merged in the nearest future. If needed, we can help with testing and making the code merge-ready. Additionally, I think a similar tactic can be applied on the client side. Batching the incoming messages would increase the chance of batching responses, especially while sending a series of
unsubmessages. - Batching interval (
Phase V
We are here now. Our final idea is to write down everything and ask you for ideas. In the meantime, the problem still occurs, we are optimizing other, relatively unrelated code, just to buy more time. Most importantly, we are fine with worse performance, as long as the system remains stable.
If you’d like to look at the CPU profiles, let me know – I’d like not to share them publicly.