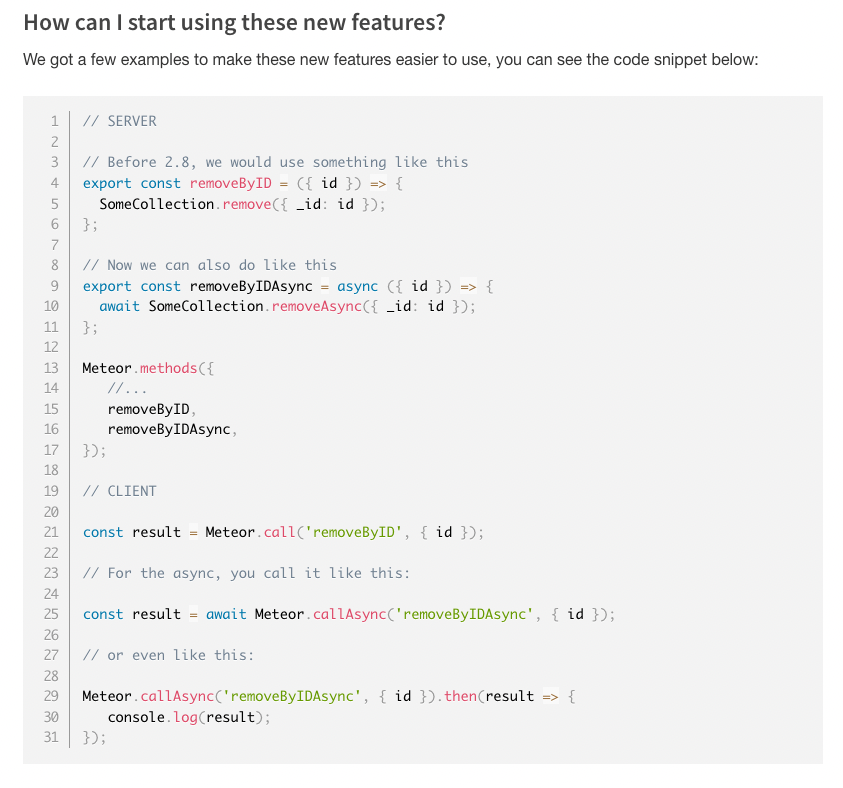
We are in the process of upgrading to meteor 2.8 and then on towards 2.11, and are struggling a bit regarding some of the gotchas in the migration docs:
It details some of the gotchas regarding the new async features. The docs make frequent mention of how the async calls have limitations in some cases where stubs exist.
I understand the concept for stubs to accommodate for latency, but I am still confused about a few statements in the docs about exactly when stubs are created.
It says:
Calling
methodson the client defines stub functions associated with server methods of the same name. You don’t have to define a stub for your method if you don’t want to. In that case, method calls are just like remote procedure calls in other systems, and you’ll have to wait for the results from the server.If you do define a stub, when a client invokes a server method it will also run its stub in parallel. On the client, the return value of a stub is ignored. Stubs are run for their side-effects: they are intended to simulate the result of what the server’s method will do, but without waiting for the round trip delay. If a stub throws an exception it will be logged to the console.
When they say “Calling methods on the client defines stub functions” Do they mean Defining a Meteor.method in a file that is bundled on the client? So if a file is in a client directory and I define a meteor method in it, does that create the stub? What about if the file is in a directory like /lib?
If we already have Meteor Methods defined that are designated as async, let’s say they are only on the server right now, at what point in the migration do we need to modify this code and in under what scenarios? Do we need to ensure that all calls to that function now use callAsync? If those methods are still called with Meteor.call() what symptoms would we likely see?