Years into Meteor development and I’m still not totally clear on what all Meteor.defer() does and offers when used on the server.
If I understand correctly, it can be used to defer a block of code to run later, asynchronously, for performance optimization. And whatever is in that block of code can’t return a value without using a Promise async/wait which would defeat the purpose of deferring it to begin with as it would then be synchronous.
So… here’s an example of an issue I have and trying to understand if/how Meteor.defer() will help:
- I have an app that has lots and lots of user critical methods firing constantly. They need to return as quickly as possible to the client. The “pressure” or frequency of these calls varies, but they are continuous user interactions always firing.
- There’s another method called
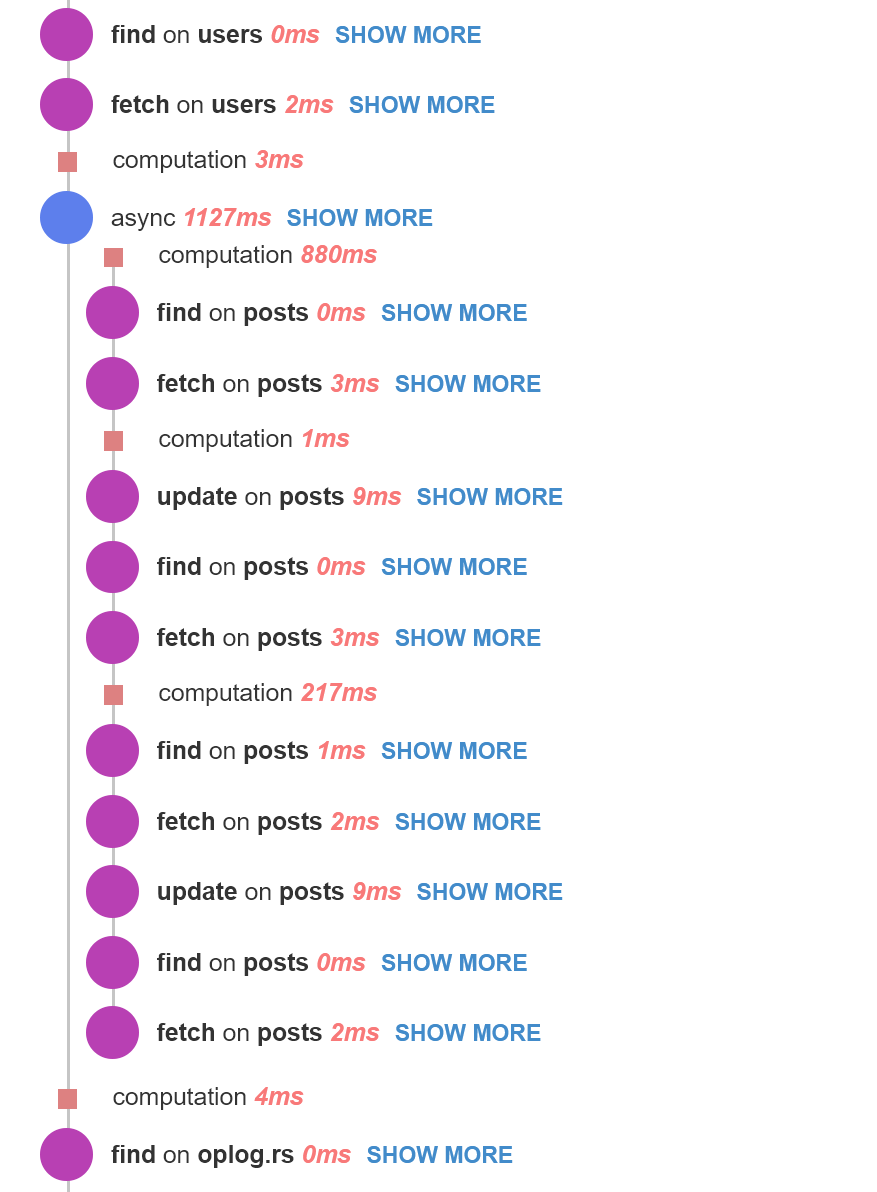
cacheHugeDataSetthat any client can call that causes a lot of Mongo hits and processing loops on the server. This does not need to complete quickly or return a value directly to the client. It can be delayed. - The problem is if
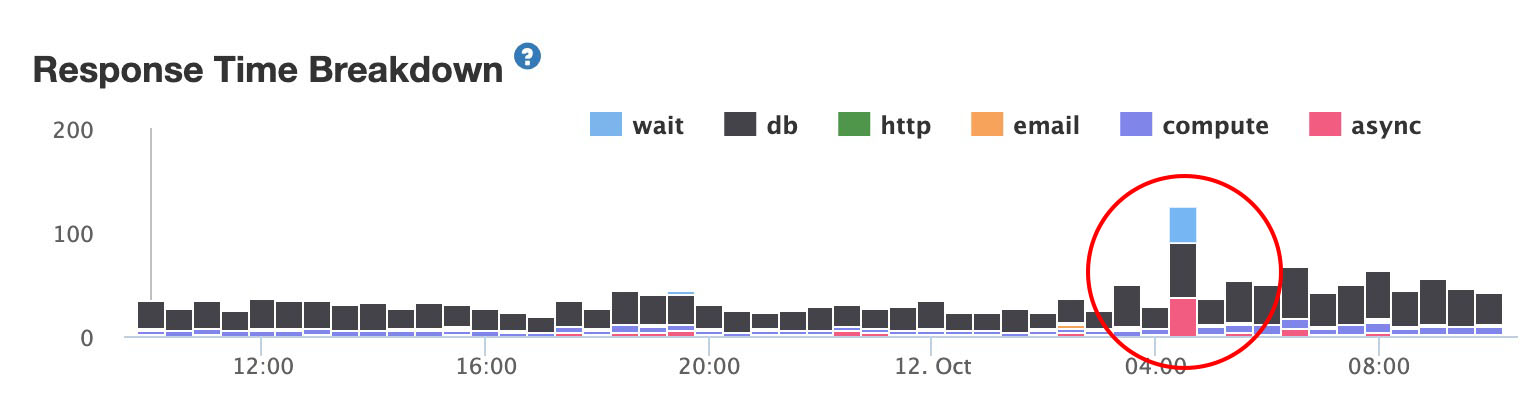
cacheHugeDataSetgets called in the middle of #1, all the calls happening in #1 get delayed significantly. I can see it happening on Meteor APM.
So my questions are the following:
- Will using
Meteor.defer()in the method code forcacheHugeDataSetmake it magically run once most/all of the calls in #1 finish? Or the pressure/frequency of the calls lowers? What’s the threshold for when the server allows deferred code to actually run? I don’t understand the Node.js event loop logic that powers whatMeteor.defer()actually does. - When the
cacheHugeDataSetheavy code inside theMeteor.defer()actually runs, does it then block everything until it’s done? Like once it’s actually allowed to run does it then take over? Or does it kindly step back into the background if “higher priority” non-deferred methods get called? - If not, does it make sense/is it possible to break large chunks of heavy code into multiple
Meteor.defer()blocks so they don’t block as much once they finally run?
I’m basically trying to handle some heavier duty code that does not need to return to the client directly (there’s other ways to do that with ready events fired back to the client that then call cache fetcher methods) with as minimal impact as possible without breaking it out into a micro-service running on its own server. That’s kind of overkill for a one or two heavy functions.
Without deferring it, I’m finding it has a huge impact on all the other high frequency, quick returning method calls that all the other clients are calling. Like everything runs fast, then a cacheHugeDataSet fires, and everything chokes for a few seconds, then returns to normal.