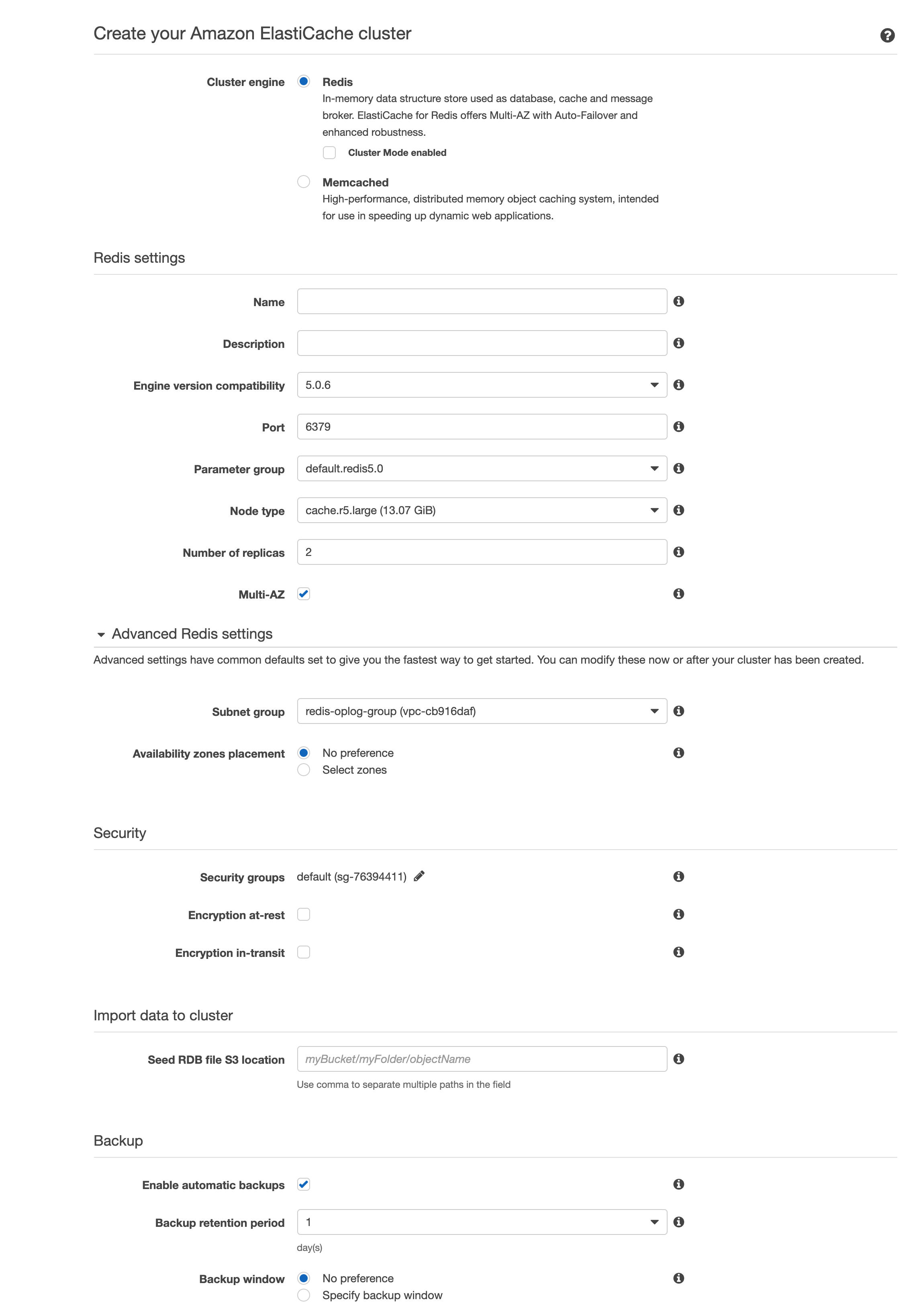
I’ve been a long time production user of redis-oplog and I have been using it with a cloud redis server from compose.io. Well yesterday they had a 12+ hour outage which hosed my app (along with many others) and I had to scramble to switch over to scalegrid.com. I wanted to set up an AWS ElastiCache cluster but the setup was too complicated to figure out on the fly. Now that the app is stable on ScaleGrid I was wondering if anyone has experience with setting up ElastiCache (@ramez@diaconutheodor). I have a few questions about the settings.
Does it work with the replicas setting? I’ve only ever used redis-oplog with a stand-alone instance (which is why I want to use a replica for failover). Does failover actually work? It seems like when you use replicas you have a write URL and a read URL. How does that jive with the single redis-oplogurl parameter?
What’s a good EC2 node type? Should work with a pretty small VM right?
Does multi-availability zone work?
Encryption at rest? Encryption in-transit? Anyone have these working with redis-oplog?
I’m assuming backups aren’t needed since it’s just a cache. Would love some feedback, best practice, and info on this.
I’ve set this up. It’s not too bad, but I never got the failiver working properly. Not sure if the problem is with redis oplog, my config in meteor or my aws config. On the bright side neither the production or staging cluster I set up has had an outage in > 18 months. I used a t2.medium and it was way too big, but it will depend on your usage. Id advise setting up an entire new cluster rather that trying to resize an existing one and switching over the new one. Given that the failiver doesn’t work nicely, neither does multi zone availability unfortunately. Happy to share my config privately if you like
Thanks for the VM recommendation. Yeah, I think we’ll be able to get away with something pretty small too. Even with a lot of users it doesn’t seem like Redis has much problem with throughput as a cache.
Did you get any of the encryption or SSL stuff working? So you’re only running a single stand-alone instance too? That scares me somewhat after what happened with compose.io. As our app relies on the reactivity with other users. It’s not just UI icing for a single user. So if that goes down, our app becomes non-functional.
And sure, you can DM your config. I may have more questions. Thanks!
We have a second instance, but the failover doesn’t seem to work, you’d have to trigger it manually do not much point. Encryption in transit yes, encryption at rest I didn’t bother with, no need. I’m away for the next week. Will get you the config when I get back.
Is it possible to access ElastiCache from Galaxy? A lot of the articles mention only being able to access it from within AWS on your VPC. It doesn’t seem to be accessible via a typical redis:// URL.
My Galaxy deployment is technically in the same region, but of course it’s owned by Galaxy and not me. Are you using ElastiCache with your own AWS hosting? Or have you managed to get it to work with Galaxy and/or hosting outside of your own AWS?
You can for sure access over a redis:// URL. I can’t imagine it wouldn’t be possible, if I had to guess you’d need to configure security groups to allow either all public IPs (little bit risky) or the specific IPs of your galaxy containers. If Galaxy uses Amazon VPCs too, in theory they could setup a VPC bridge to allow communication between their cluster and yours. I don’t know if they expose that to customers though.
We use Redis (Elasticache) on a single t3.micro instance (reserved to save money) and we barely use any capacity. Nothing fancy, same VPC as the Meteor instances (scalable on ElasticBeanstalk).
We didn’t need to use any encryption as all data transmission is within a private VPC.
We use the DNS name for the url parameter of redis-oplog < instancename >.*.cache.amazonaws.com and port 6379
We faced this issue as well. What we found is that Meteor (Node) times out on the redis connection as it is too busy handling other requests or processing too many redis messages.
We fixed some of the underlying issues in our fork of redis-oplog which may or may not fit your use-case
Our fork reduces the number and size of redis messages - this in turn reduces the load on the listening instance (we do this by Diff-ing against existing doc to make sure we only send real changes)
We made sure on our server we don’t have functions or methods that take up too much CPU time in one shot; we used Meteor.Defer and Meteor.setTimeout to break out computationally-intensive functions (Node is single-threaded as you likely know already)
We don’t use protestAgainstRaceConditions:false in cultofcoders:redis-oplog as it sends the whole document which might be too big and requires processing at the receiving end (solved in our fork by removing this option)
On AWS we stopped using burst instances (i.e. t3.large) in favor of compute instances (c5.large).
#2 and #4 may likely be the biggest contributors to solving the issue, but I have to admit we didn’t do much testing to know where the highest impact is, it works now and that’s all that mattered to is.
I dont think im doing anything CPU intensive on start, but it usually spikes cpu on deploy. I’ll investigate on that side, or maybe is just that im not setting up correctly the security group in AWS. Do you have any insights on that part?
I am asking as you have a prefix in your config. Where is that coming from?
Also, overridePublishFunction no longer does anything, if you are using the latest version of cultofcoders:redis-oplog
What I would do, is go into the virtual machine of your meteor instance, install redis-cli and then connect to your redis instance. Call the monitor command to see the messages.
Thanks Ramez, ill do that and let you know my findings.
The prefix was because I used the same redis for BETA and PROD environments. Ill remove those 2 settings also and see if it works. Also no oplogtoredis, just redis-oplog.
Thanks @ramez, just got it working. Was a missing config in the security group.
I got a question about your fork. When you talk about caching of collections is the caching of find and findOne, etc or only caching of specific functionality of reactivity?
I mean if I call Collection.findOne() it will hit the cache?
First of all a big thank you for the fork, ramez! You guys did an amazing work on improving the original package, fixing pressing issues and problems.
I have just one question (for now) regarding caching: as documented, TTL is apparently configured in the Meteor settings "cacheTimer" for all collections marked cacheable by invoking collection.startCaching(). Would it not make sense to allow for separate TTLs on a per collection basis? Meaning that documents in some collections could be seen as semi-permanent, and as such, be subject to TTLs of, say, several hours, while others are expected to be cached for short periods only.
Also, if I may suggest, providing some API for cache invalidation, ideally on collection level, or, even more luxuriously, on a document level (collection name + document id), would be a great feature
Yes findOne and find both hit the cache.
Which is really cool, this has been my dream from day one.
This way, I can write my finds in my code and not worry about db hits. I don’t have to optimize anything, just get the data when I need it.
I used drupal in the past and hated it. If you look at the number of queries to build each page, it was astronomical. So much db hits wasted on the internet. We don’t have to be part of this trend