So there I was, searching around for redux example projects when I came across the blog post “TodoMVC With React Native and Redux”. It’s a pretty good code walkthough touching heavily on redux.
I read through it and think I’m mostly at comphrende, so I check out the updates links I had seen mentioned at the top of the post. They added graphql and parser server to the todo example…no apollo though which I’ve also been trying to learn and find examples for… <–lamesauce
Finally I bounce over to the github codebase for the post and scroll down to the Readme . Read the first heading and wouldn’t you know :-0 ← astonished face… It was updated to use Apollo for a forthcoming blog post that never came out.
I fire it up and we have magic in the emulator:
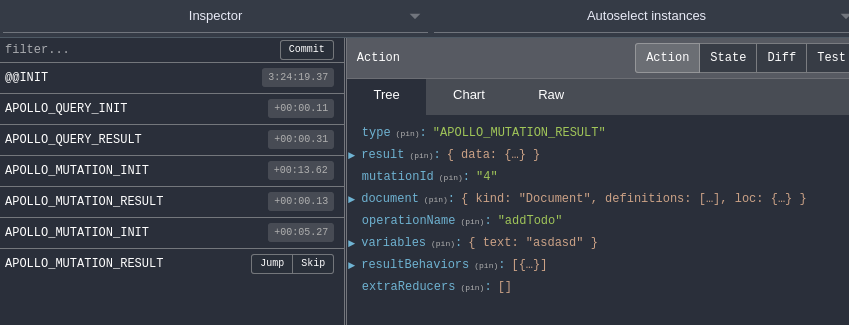
It’s not connecting to the redux-dev-tools in my react-native-debugger app. Turns out gotta change how dev tools is instrumented in the app. But a quick fix later we’re literally in action:
Now the thing I’m having a tough time squaring between the original post and the repo updated with apollo, is the complete change in redux actions. Without apollo the actions had much more explicit and narrower meanings. Things like TOGGLE_TASK_COMPLETION, DELETE_TASK, ADD_TASK.
With Apollo we have APOLLO_QUERY_INIT, APOLLO_QUERY_RESULT, APOLLO_MUTATION_INIT, APOLLO_MUTATION_RESULT as you can see above.
Can’t remember where but I’ve seen @sashko explain that Apollo’s redux state and data store is necessarily complex, which is why it’s usually best to use the apollo abstractions. As an amateur to redux I’d like help understanding the implications of this. At the surface it seems like I would lose the ability to write reducers that accept the more explicit actions emitted when not using Apollo.
Maybe this is a non-issue but to my novice understanding it gives me some hesitance. Can anyone clear my worries away?
The goal is that you still get to use Redux to keep track of state and keep all of your data in one place. You do lose the ability with Apollo to name the actions, since they all have more generic names. In this case I suggest using the query operation name to identify the queries and components involved!
Also it doesn’t work with React Native but in chrome we have an Apollo dev tools package that gives you Apollo specific insight into the store.
Yes, the operationName is quite useful in understanding what is happening. But I guess I’m not so much confused about how apollo works… it’s actually easier than I first expected. I’m more discombobulated about how this affects my limited understanding of how to design/architect a redux app. I was all ready to be dispatching actions and writing the purest reducers you ever saw.
[X] The whole state of your app is stored in an object tree inside a single store.
[?] The only way to change the state tree is to emit an action, an object describing what happened
Apollo emits the actions for you when you mutate or query?
[?] You write pure reducers to specify how the actions transform the state tree,
Apollo handles this for you based on the query or mutation?
Does that sound right?
Is it only important that these redux principles are happening in the app even if indirectly? What if anything is lost by not emitting actions and writing reducers directly?
What would be the closet thing to the redux gist for Apollo? Or maybe there is some resource that compares the impact on how you might structure your project differently?
I think using Apollo you buy into a somewhat modified version of the Redux architecture. I think it’s still great to use that approach for your client-side data, and put that in Redux. But with Apollo you let it manage the GraphQL-based data for you, and then you operate by reading and writing GraphQL queries into and out of the store.
So based on the above list:
Still have a single global state object, great
You change the state either by emitting an action, for your client-side data, or by telling Apollo to update the GraphQL store via the React HoC or other API. This uses an action under the hood.
The Apollo reducers are completely hidden from you, but follow a very predictable model based on the GraphQL results.
The biggest thing about Apollo is that your reducers, selectors, and actions are handled for you in a predictable way so you can think about GraphQL instead of those other things.
If you created a new Apollo based react-native project from scratch the Apollo data flow might look something like:
ApolloClient is created and points to /graphql on host unless pointed elsewhere
Passing in client.reducer() to createStore will make Apollo use your own redux store
In the future maybe the client side cache can easily be re-hydrated from local persistent storage but for now there is no good example of how to do this and is an ongoing discussion/issue
ApolloProvider makes apollo client store available to the react component tree it wraps
Components are wrapped with queries and mutations
Rendering the component triggers the query, which queries the apollo redux store. If the data is not there or we’re forcing a re-fetch the query gets data from the server. QUERY_INIT and QUERY_RESULT actions are emitted to do this.
Server responds and internal apollo reducers merge in the new data to the redux store
Maybe a user action causes a mutation to be called.
Apollo emits a mutation action, sending it to the server … it also may return an optimistic result
This optimistic result is merged with the store
The server responds and… this is a bit unclear… does it do nothing if it matches the optimistic respond and/or does it automatically invalidate and re-render if it doesn’t match
Rinse and Repeat
In terms of answering one of my own questions about impacts of changing to Apollo, Redux time travel may be less useful with Apollo.