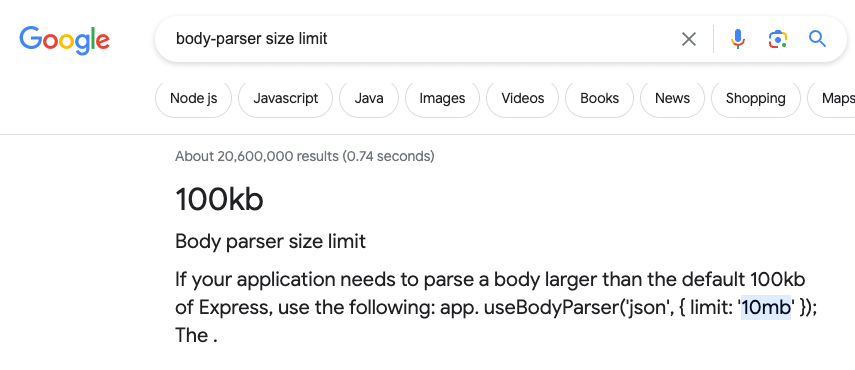
We’re trying to create a rest-api that can handle 10mb POST requests but we fail to make it work. Every time a client calls our rest api, node says the payload is too large.
Could anybody show us how they do it ?
Rergads,
Burni
var bodyParser = Npm.require('body-parser');
WebApp.connectHandlers
.use(bodyParser.json({ type: '*/*', limit: '50mb' }))
.use('/api/test_post', function (req, res, next) {
console.log('API CALL: /api/test_post');
We receive this error:
W20230711-12:47:43.378(-4)? (STDERR) PayloadTooLargeError: request entity too large
W20230711-12:47:43.378(-4)? (STDERR) at readStream (/Users/devel/Documents/code/node_modules/raw-body/index.js:155:17)
W20230711-12:47:43.378(-4)? (STDERR) at getRawBody (/Users/devel/Documents/code/node_modules/raw-body/index.js:108:12)
W20230711-12:47:43.378(-4)? (STDERR) at read (/Users/devel/Documents/code/node_modules/body-parser/lib/read.js:77:3)
W20230711-12:47:43.378(-4)? (STDERR) at jsonParser (/Users/devel/Documents/code/node_modules/body-parser/lib/types/json.js:134:5)
W20230711-12:47:43.378(-4)? (STDERR) at wrapper (packages/montiapm:agent/lib/hijack/wrap_webapp.js:179:36)
W20230711-12:47:43.378(-4)? (STDERR) at packages/montiapm:agent/lib/hijack/wrap_webapp.js:206:14
W20230711-12:47:43.378(-4)? (STDERR) at /Users/chandi/.meteor/packages/promise/.0.12.2.1s34aw5.rpyc++os+web.browser+web.browser.legacy+web.cordova/npm/node_modules/meteor-promise/fiber_pool.js:43:40
Exactly. But our way of specifying 50mb does not seem to work. Is the syntax OK ? I could not find any specific example of how to use it in the Meteor context without Apollo.
I believe your body is larger than 50mb or is not the right type. I would force the type to be json so you could remove type entirely or set to */json.
I’d also try with a smaller file and make sure the receiving occurs with no errors.
You can also set this to false
strict
When set to true, will only accept arrays and objects; when false will accept anything JSON.parse accepts. Defaults to true.
I also try to send streams if that is not the case now instead of strings.
It’s worth asking - what are you trying to receive as JSON that is 50Mb?
If it’s a file, and your server receives it and uploads it to AWS S3 or similar, then a better option can be to use a pre-signed URL so that the client can upload it directly to your S3 bucket. That will probably be faster for your users and significantly reduce load on your server…
If that’s the case, I have some code snippets for Meteor which can help, but it’s fairly easy.
We have found a solution but we don’t like it much.
Based on your suggestions, we understood that the files were in fact valid. A 99kb file was OK but if we added a couple of bytes to it, it failed with Payload too large. So we concluded the config was ignored.
So what we’ve found that works is to set the config at the top of the file and not in individual rest-calls functions :
WebApp.connectHandlers.use('/api/test_post', (req, res, next) => {
let body = ''
req.on('data', data => {
body += data
})
req.on('end', () => {
console.log(body) // do something with the body (your payload). I tested with a 24MB payload.(https://github.com/json-iterator/test-data/blob/master/large-file.json)
res.writeHead(200)
res.end('Message returned to the sender: ' + Meteor.release)
})
})
@wildhart you were curious about the content of those 50mb. They actually don’t exist. I was using 50mb as a very high value so it wouldn’t impose limits during testing. The real value will be 2-3mb.
The content is what would usually appear in console.log of the clients that those send to us when there’s a window.onerror detected. We just want it to be big enough to give us all the required information to debug when necessary.
We’ve noticed that some errors just pop in window.onerror but not in Monti APM which also detects errors not detected by window.onerror.
// this is isomorphic.
if (Meteor.isClient || Meteor.isCordova) {
const _WoE = window.onerror
window.onerror = function (msg, url, line, error) {
// logErrors.error('Logger error on client: ' + msg, { file: url, onLine: line })
// pipe the error through your server side logger and get it in Monti.
if (_WoE) {
_WoE.apply(this, arguments)
}
}
}
@burni13 thanks for the explanation, that makes sense.
You mention the client is using MontiAPM, so is the client your Meteor app? If so, why not use a Meteor method to send the log messages to the server, instead of using WebApp.connectHandlers?
@wildhart Yes the client is a Meteor app. I must admit I did not think of using the websocket as the client app just crashed (white screen). I did not expect the websocket to be in a stable condition.
Streaming large payloads of JSON data via a REST API can be achieved by utilizing a streaming approach on both the server-side and the client-side. This allows you to transmit and process data in smaller chunks, reducing memory usage and increasing efficiency. Below, I’ll outline the steps for implementing JSON data streaming on both ends.
Server-Side (API Provider):
Chunking Data: Break down the large JSON data into smaller, manageable chunks. This can be done either by reading data from a file in chunks or by dynamically generating smaller batches of JSON data.
Streaming Response: Use a streaming library or framework on the server-side to send the JSON data in chunks rather than sending the entire response at once. This way, the server won’t need to build the entire JSON response in memory before sending it.
Content-Type and Transfer-Encoding: Set the appropriate HTTP headers to indicate that you are streaming the data. For JSON data, set the Content-Type header to application/json and the Transfer-Encoding header to chunked.
Flush Data: After sending each chunk, make sure to flush the response buffer to ensure that the data is sent immediately without waiting for the entire response to be constructed.
Below is an example using Node.js and Express to stream JSON data:
const express = require('express');
const app = express();
app.get('/stream-data', (req, res) => {
// Simulate generating or reading large JSON data
const largeJsonData = /* your logic to generate or read JSON data */;
// Set appropriate headers for JSON streaming
res.setHeader('Content-Type', 'application/json');
res.setHeader('Transfer-Encoding', 'chunked');
// Simulate chunking and streaming the data
const chunkSize = 100; // Set an appropriate chunk size
const totalChunks = Math.ceil(largeJsonData.length / chunkSize);
for (let i = 0; i < totalChunks; i++) {
const start = i * chunkSize;
const end = Math.min(start + chunkSize, largeJsonData.length);
const chunk = largeJsonData.slice(start, end);
res.write(JSON.stringify(chunk));
// Optional: Add a small delay to simulate a slower stream
// await new Promise(resolve => setTimeout(resolve, 1000));
}
res.end();
});
// Start the server
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
Client-Side:
When consuming the streaming API on the client-side, you’ll need to handle the incoming chunks of data. Here’s an example using JavaScript’s Fetch API:
javascriptCopy code
const processChunk = (chunk) => {
// Process the JSON chunk received from the server
console.log(chunk);
// Your custom processing logic goes here
};
fetch('http://localhost:3000/stream-data')
.then(response => {
const reader = response.body.getReader();
return new ReadableStream({
async start(controller) {
while (true) {
const { done, value } = await reader.read();
if (done) {
controller.close();
break;
}
controller.enqueue(value);
}
}
});
})
.then(stream => new Response(stream))
.then(response => {
const reader = response.body.getReader();
const decoder = new TextDecoder();
return (function read() {
return reader.read().then(({ done, value }) => {
if (done) {
return;
}
const chunk = decoder.decode(value, { stream: true });
processChunk(JSON.parse(chunk));
return read();
});
})();
})
.catch(error => console.error('Error while streaming data:', error));
This client-side code sets up a streaming response using the Fetch API and processes each chunk of JSON data as it arrives. The processChunk() function represents your custom logic to handle the received data.
By following this approach, both the server and the client can efficiently handle large JSON payloads without running into memory-related issues.
Wow. thanks for taking the time to document this way of doing. I’m sure it’s going to help others.
There’s one thing I do not understand. On the receiving end, if the first JSON object is not “merged” back in one big chunk, how can it be processed while still being a valid JSON object ? what if the chunk did cut the object at a weird place.
Isn’t necessary to split it at smart places like an object of an array or some specific part of an object ?
You’re welcome buddy - I can’t take any credit though, it’s just chatgpt.
In answer to your question:
There’s one thing I do not understand. On the receiving end, if the first JSON object is not “merged” back in one big chunk, how can it be processed while still being a valid JSON object ? what if the chunk did cut the object at a weird place.
Isn’t necessary to split it at smart places like an object of an array or some specific part of an object ?
The data will stream in line by line, so you just have to make use of it - concatenate on the fly to an object with scope outside of the stream. So using push for instance you can push that to an array and then after the stream is completed you will have everything residing in that object.
If this is gigabytes of data you are better just performing a blind insert to mongo - do not use upsert it’s very resource intensive (requires an additional find, which can really slow shit down) just continaully insert it all but first sanitize the entry (trim, type check, various conditionals etc) so it’s not garbage going in and you’ll be having a great time.
Enjoy and keep on keeping on. Teach a friend for free. Don’t let GNUGPL die