We experience weird meteor method response behavior from time to time on only one of our environments (fortunately it is on staging, not production). When we deploy the web app everything runs fine. After a couple of days or weeks (sometimes even months) some method calls do not respond with an update and result response anymore. Methods that only fetch data still work correctly. Only methods that will make changes to the database (insert, update or delete) stop giving responses on the websocket. The server processes those calls correctly as far as I can tell. The database is updated and there are no error logs to be found. Just the response from the message is missing. Subscriptions still provide the initially fetched data to the client but will not rerun if subscribed data was changed. If we restart the service, everything behaves as expected again, at least for some time.
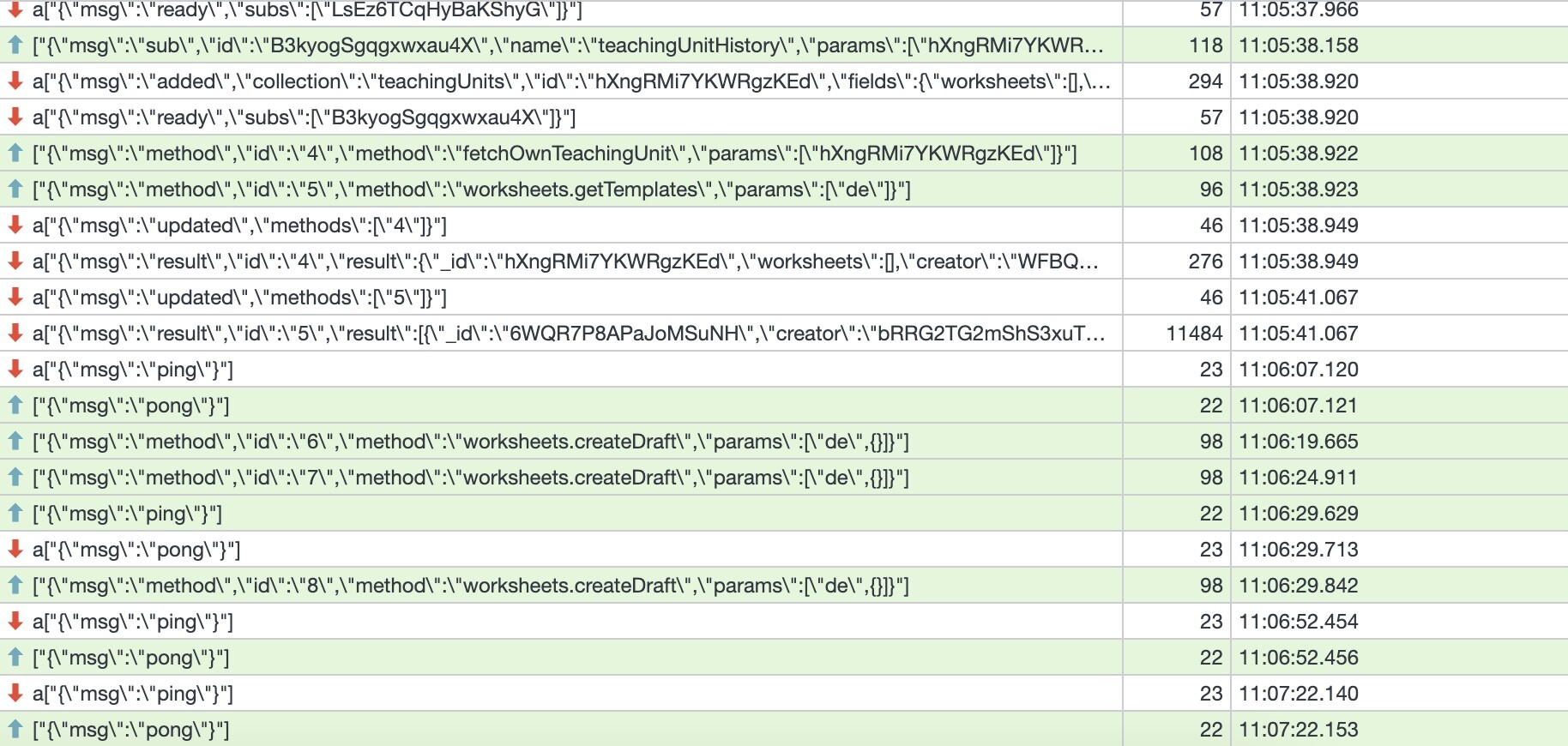
I made a screenshot of some websocket messages to illustrate the problem. The subscription at the top adds data and becomes ready. The fetch and get method successfully return the requested data. Only the create method does not return anything, despite the connection being alive the whole time.
We currently run Meteor 2.10 on all environments and each environment has its own database hosted on MongoDB Atlas. We try to keep staging and production as identical as possible but there are a few differences.
Staging runs on an M2 cluster so it got automatically updated to version 6.0.10 at some point. Production is still on 4.4.24. I do not think this problem is related to mongodb versions though. We have a version difference for more than a year now and the first of those incidents appeared only a couple of month ago. Other less used environments with an M2 cluster on 6.0.10 are working fine as well. I did not find the courage to update production yet, because I am too afraid of this bug
There is a big end-to-end browser test suite run on staging quite frequently (webdriver.io). Those tests are not run on production, but they are run on other environments from time to time. Those tests were introduced at a similar time where those problems first started to appear, but I doubt it is related.
Staging receives production data every night. The staging database is wiped and a production backup is restored. We started this restoration process around the same time those problems started appearing as well. We have data related to another service which employed this process, so we had to do the same to keep the data synced. This seems to me like the most probable candidate to create these problems.
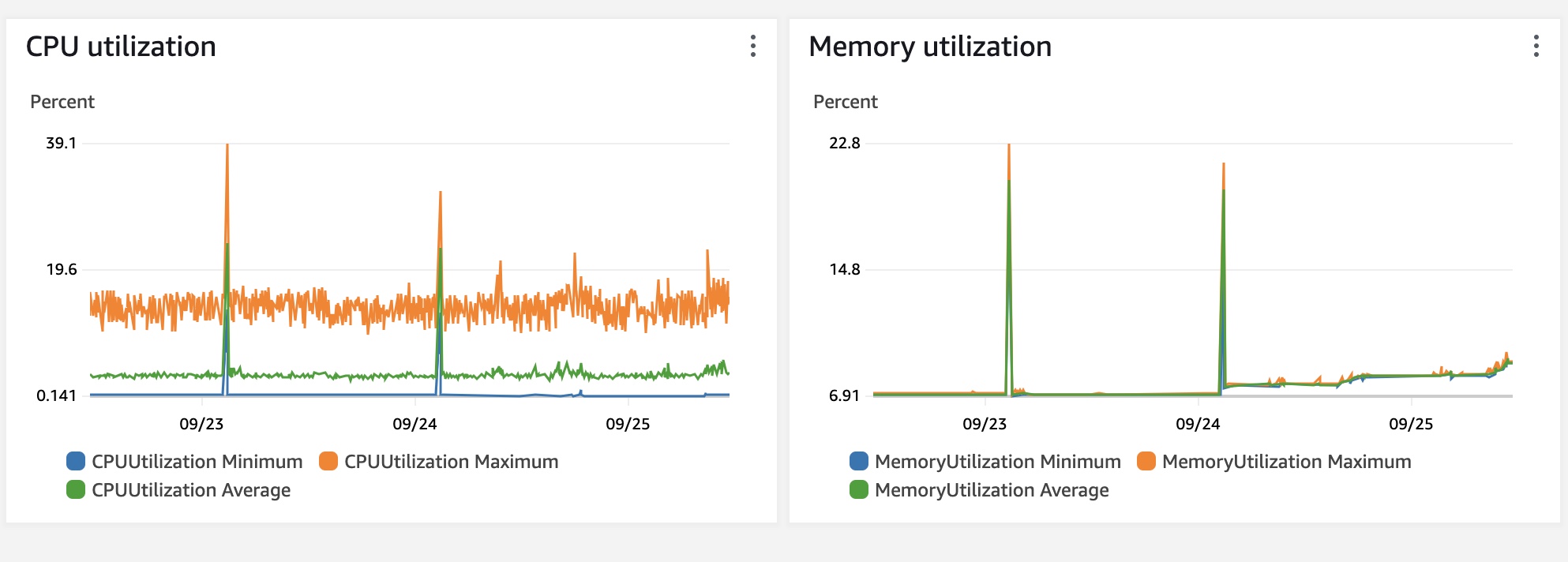
We should probably stop the meteor app service before we do the restoration shenanigans, because of its connection to the database. If the problem is related to this, this should probably fix it. But I would still really like to know why this would create problems for meteor. It does seem like those restoration events can have some lasting impact on memory consumption.
X axis dates are at the end of the day for some reason
Those memory spikes are caused by the data restoration. There were a couple more since the last service restart. It was a quite week. We usually release a couple of changes a week, which is probably the reason why we do not have this problem more often. We became aware on the 25th in the afternoon, but since this was on Monday, it might have been there for longer. Memory seemed to be steadily increasing since then. Maybe the message queue is blocked somehow and is building up. Could also just have been tests though. I have no clue, I’m grasping for straws. That is why I’m here. I thought that there might be a kind, experienced Meteor expert here in the community, who knows the details of the message system and can shed some light on this
Any help or hints would be greatly appreciated.
Cheers
Also, catching these events in the server and then logging them helped us find a lot of these minor quirks that are otherwise bugs that will not be known to us:
Also, try in your connection options: readPreference=primaryPreferred and w=majority (write concern) if set to something else.
Chances are that on a connections spike on your DB (counters seen in Atlas console) your replication to secondaries is delayed and there is nothing to read back in the time set for waiting.
Read and write concerns and preference help you to wait for things to complete and ensure a result is returned, though they can make transactions slower at times.
There are also some option that, if set, may influence the return of a result, such as socketTimeoutMS
Thanks for the quick replies. I will try to improve our monitoring then. Any specific meteor internals, stats or metrics I should be monitoring. Message queue length sounds interesting for example. Proper method tracing is difficult right now. We use datadog for monitoring and it does not like fibers anymore. With Meteor 3 on the horizon, we probably do not have to wait much longer though.
@rjdavid What do you mean by catching these events. How would you catch this. We currently wrap Meteor._debug to get some insights into exceptions, we do not specifically catch right now. Are there errors not going through debug. Wrapping whole methods with try catch is possible but will not catch anything meteor internal.
@paulishca Thanks for pointing out the connection options. I was not aware we can adjust those. Profiling is only possible on M10+ . I might try out upgrading if nothing else helps, but I doubt this would help. I think the problem is more meteor related than on the mongo side.
It is likely that the problem is related or even caused by mongodb but it manifests in meteor and meteor ends up in an invalid state, and I would like to know what that invalid state is. Why else would everything be fine again after a fresh start.
According to the docs
Meteor tracks the database writes performed by methods, both on the client and the server, and does not invoke asyncCallback until all of the server’s writes replace the stub’s writes in the local cache.
Something has to go wrong here. That would explain why get methods still work completely fine, but all the ones with writes fail to respond. I’m not so familiar with the meteor codebase. Can someone point me to the implementation of this. Is this depending on the oplog tailing?
Tailable cursors may become dead, or invalid, if either:
- the query returns no match.
- he cursor returns the document at the “end” of the collection and then the application deletes that document.A dead cursor has an ID of 0.
Maybe the oplog tailing cursor dies because the database is wiped?
Not all errors are being caught therefore Meteor._debug will be useless on such case. I am in my mobile phone but you can search nodejs documentation on how to catch those. These are just normal events being thrown by node for cases that rejections and exceptions are not caught by existing code
If you are using datadog, that might already be in place but I’m not sure
Thanks a lot. I will add this asap. Seems like I should get a little bit more familiar with node. I will post again if there are further insights. Might take a while though.