I’ve been watching the discussions around GraphQL and Apollo and I’m wondering what people think of the implementation I’m considering.
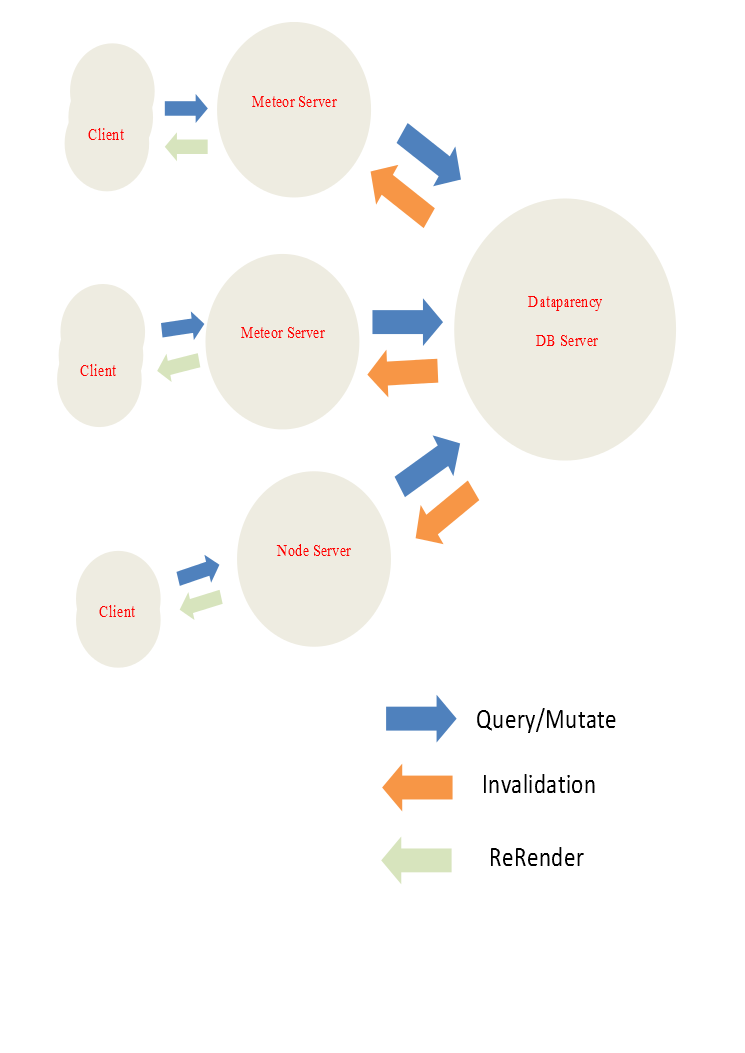
I have access to a unique patented NoSQL database that would back the infrastructure I’m proposing. Essentially, it would be a shared database that would support a extended version of GraphQL (I need privacy considerations included in the schema). As the single source for data,it would be possible to provide invalidation events to any meteor/node server attached. My implementation requires a data model conformant to an entity-centric model where ‘aspects’ or collection of like semantic values (demographic, shares/likes, etc.) are available for query. This entity-centric condition allows me to ‘shard’ storage among entity specific servers for scalability/performance.
I’m thinking that the db server would stream mutation events to the registered meteor/node servers and let them decide how to invalidate data to their clients.
I plan to offer a free single instance developer version, restricted only in capacities. A enterprise edition would be offered with full sharding/scalabilities as a hosted PaaS. Something that Galaxy could offer.
I have yet been unsuccessful in gaining funding, so this might not happen.
Any thoughts would be appreciated.
UPDATE
Though I’d add some of the offered features:
-
datastore engine indexes everything, elements/attributes/fields using a hash-like ‘icon’ so there is no indexing definition required. ‘Icon’ algebra allows pattern matching without going back to data.
-
datastore engine is schema-agnostic, GraphQL schema defines values within interface layer. Hierarchy nodes can be deleted/inserted/updated at will without re-indexing as in mongo.
-
datastore engine is fully ACID supporting transactions/rollback and live backup.
-
will accept XML/JSON and possibly YAML as input, output in any of them.
-
looking to build node.exe addon for native database within node runtime, i.e., no network latency. Useful for embedding in IoT gateways to manage device data.