Hello,
I have a very long time waiting time for login.
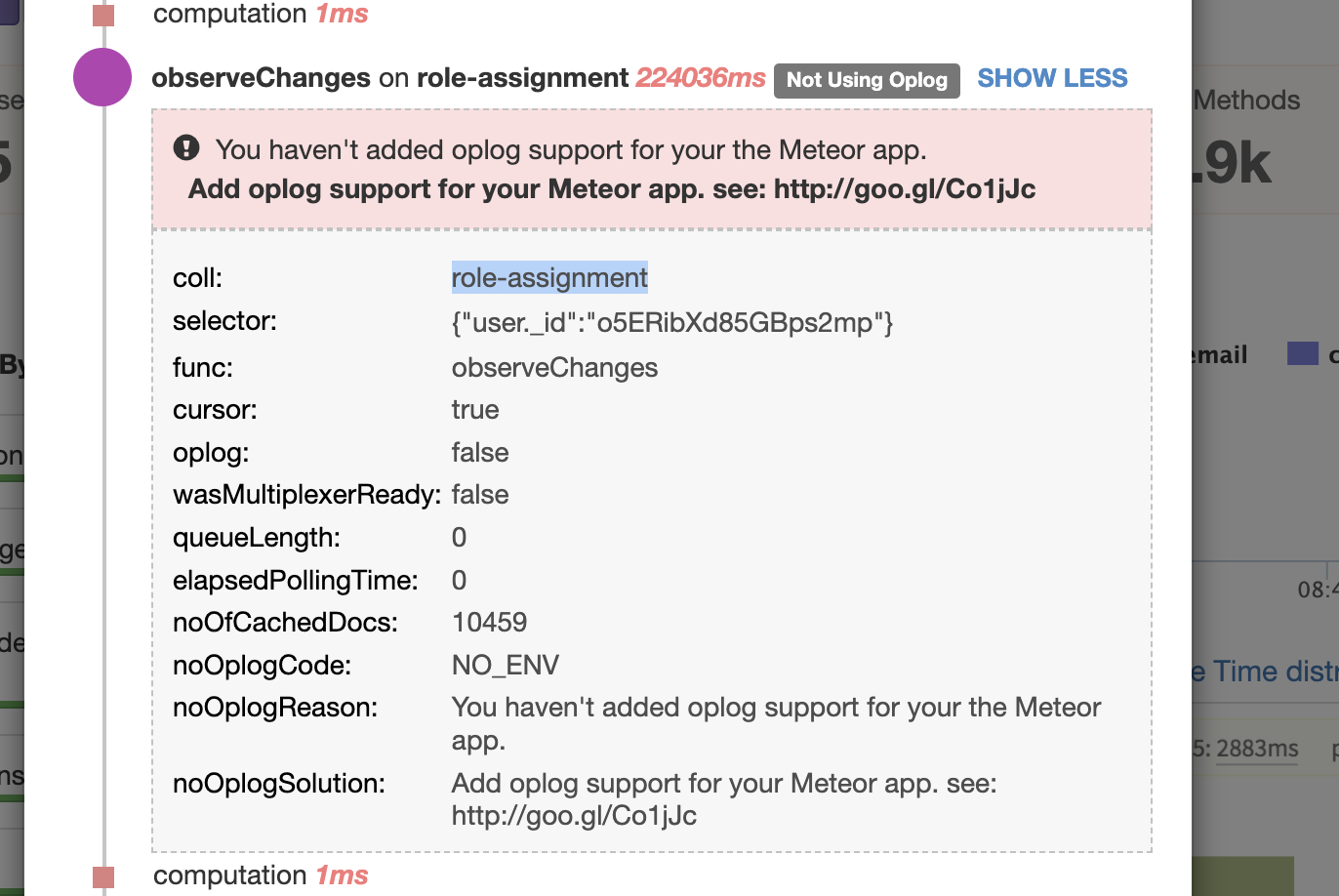
It seems related to observer.
https://app.montiapm.com/mt/13eba39a-b8a5-42a9-afa0-b8eb84c36da9/MW22EHSLSrZNW6cCT
Do you know how to improve this ?
I don’t understand why in a method we are observing changes
We have 250 000 documents in the role-assignment collection
Ok, read this, point 8: Publications and Data Loading | Meteor Guide
Then check point 3 here: meteor-roles/README.md at 611618c5781617dfef59d64fa3227c4e985f9cd5 · Meteor-Community-Packages/meteor-roles · GitHub
You have a reactive publication to which you need to subscribe. You don’t have an oplog attached to your Meteor server.
What you need is to have these two (as a general example):
MONGO_URL: ‘mongodb+srv://usr:pass@your-cluster.xxxx.mongodb.net/meteor?retryWrites=true&w=majority&connectTimeoutMS=60000&socketTimeoutMS=60000’,
MONGO_OPLOG_URL:‘mongodb+srv://oplog_user:pass@your-cluster.xxxx.mongodb.net/local’
These urls are the format used with MongoDB Atlas. Atlas allows you to use different users for DB and oplog but they can be the same user with rights over both resources.
2 Likes
Thanks for your answer.
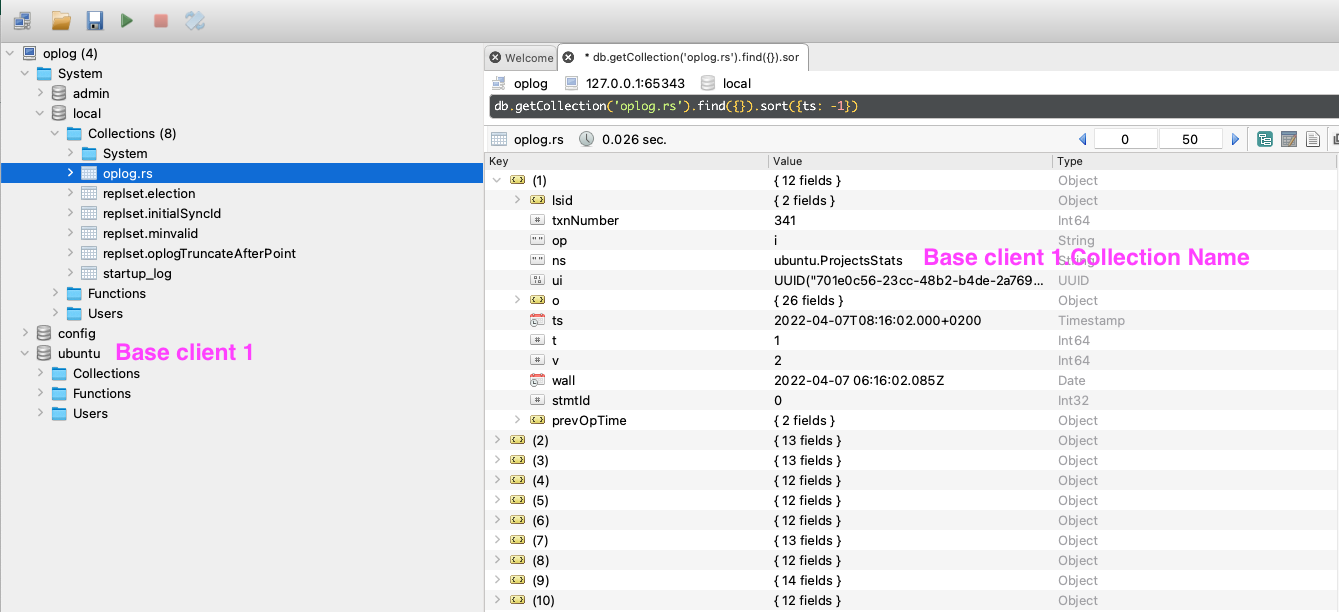
I am testing to convert my standalone mongo into replicaSet.
I am following this guide : https://www.mongodb.com/docs/v4.4/tutorial/convert-standalone-to-replica-set/
Everything went fine.
I still have some doubts.
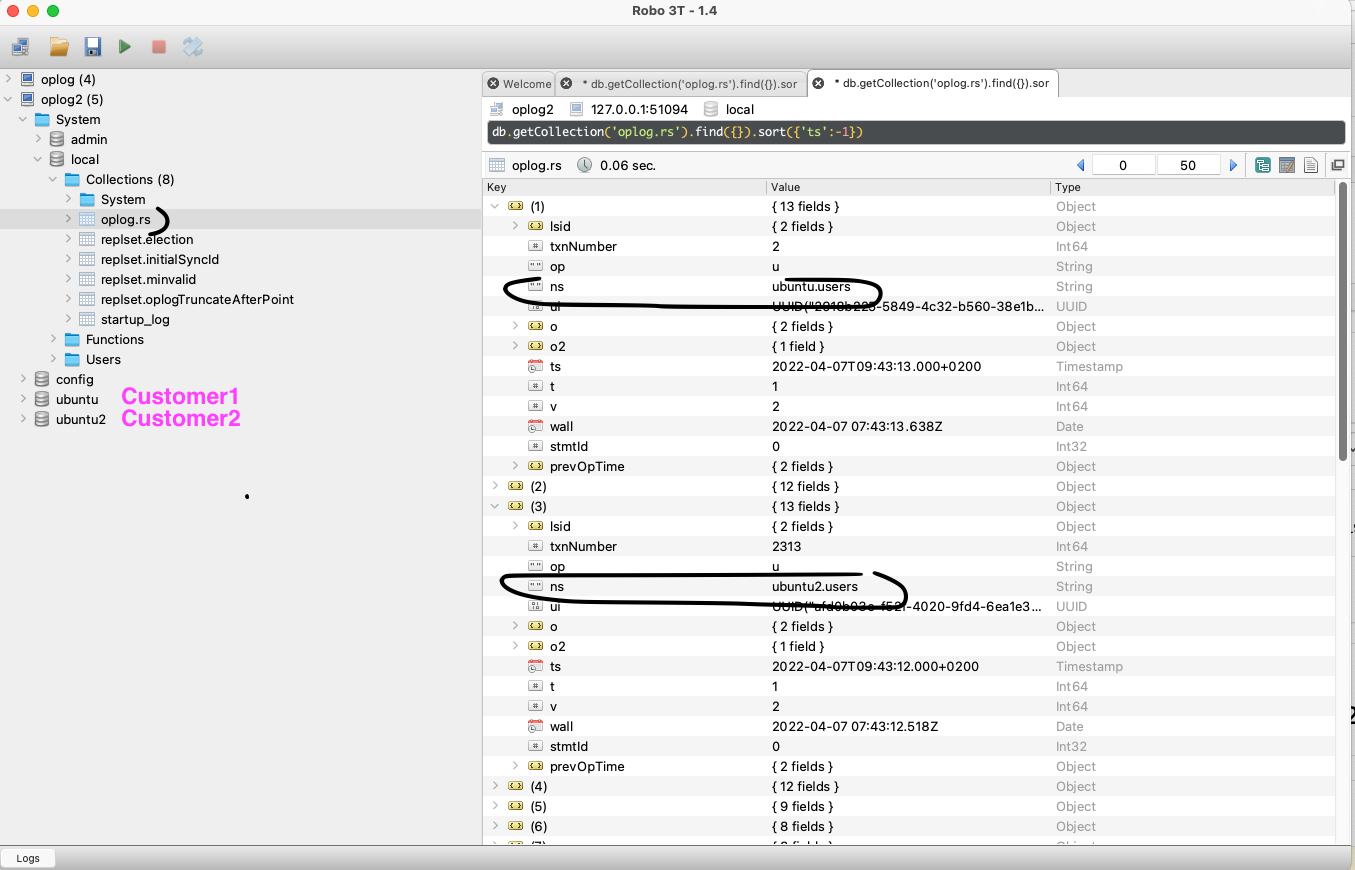
In the screenshot above my db is called “ubuntu”, If I add more customers on this mongo, I will have more db like “ubuntu2”, “ubuntu3”.
But there is only 1 local db with oplog.rs collection for all my customers db. In other words they will all share the same oplog. Is that right ?
Will meteor use the ns (=namespace) field of the oplog to distinguishe the changes to observe ?
Thanks
“…keeps a rolling record of all operations that modify the data stored in your databases.”
My understanding is one oplog per cluster. I take it you will be using multiple Meteor servers running with different MONGO_URLs, each pointing to a different db in the same cluster.
I’d say, if you have a rather simple system with few concurent users per DB and few subscriptions (POS for example), I’d go with one cluster (one oplog). If each customer (DB) is complex and data intensive (financial systems, CRM, social network, communication tools/chat etc) I’d go for separate clusters (if not too intensive). You could go with the free package of Atlas and use something like this for backups: GitHub - stefanprodan/mgob: MongoDB dockerized backup agent. Runs schedule backups with retention, S3 & SFTP upload, notifications, instrumentation with Prometheus and more.
Would be worth asking/checking in the redis-oplog community package repo how is this package handling multiple DBs. Then you would need a server/instance to run your Redis.
Hello,
Thank for your answer.
I did the test, with 2 db (2 customers) and yes they share the same oplog as they are on the same mongo instance.
I think I can live with this.
1 Like
Has your login time improved? If yes … [SOLVED]