Hi guys, here’s my setup:
I’ve got a game where a player has X and Y. They travel through space, where X and Y can be 0 - 100,000,000 say.
I don’t need the user to subscribe to all the other players that aren’t near them. Why send the data, right?
So here’s that subscription cursor:
return Posts.find({
$or:[
{type:"ships"},
{type:"planets"},
{type:"asteroids"}
],
last_activity:{
$gte:time_timeout
}
});
This works great, it’s reactive, hooray. A player moves in to a far away distance and the other player surely is visible and they interact.
But they get ALL data. So I want to only give them data that’s near them by saying “Find everything near you” by settings an X and Y, like so:
var range = 100;
var scanner_left = player_ship.x - range;
var scanner_right = player_ship.x + range;
var scanner_up = player_ship.y - range;
var scanner_down = player_ship.y + range;
return Posts.find({
$or:[
{type:"ships"},
{type:"planets"},
{type:"asteroids"}
],
x:{
$lte:scanner_right,
$gte:scanner_left
},
y:{
$lte:scanner_down,
$gte:scanner_up
},
last_activity:{
$gte:time_timeout
}
});
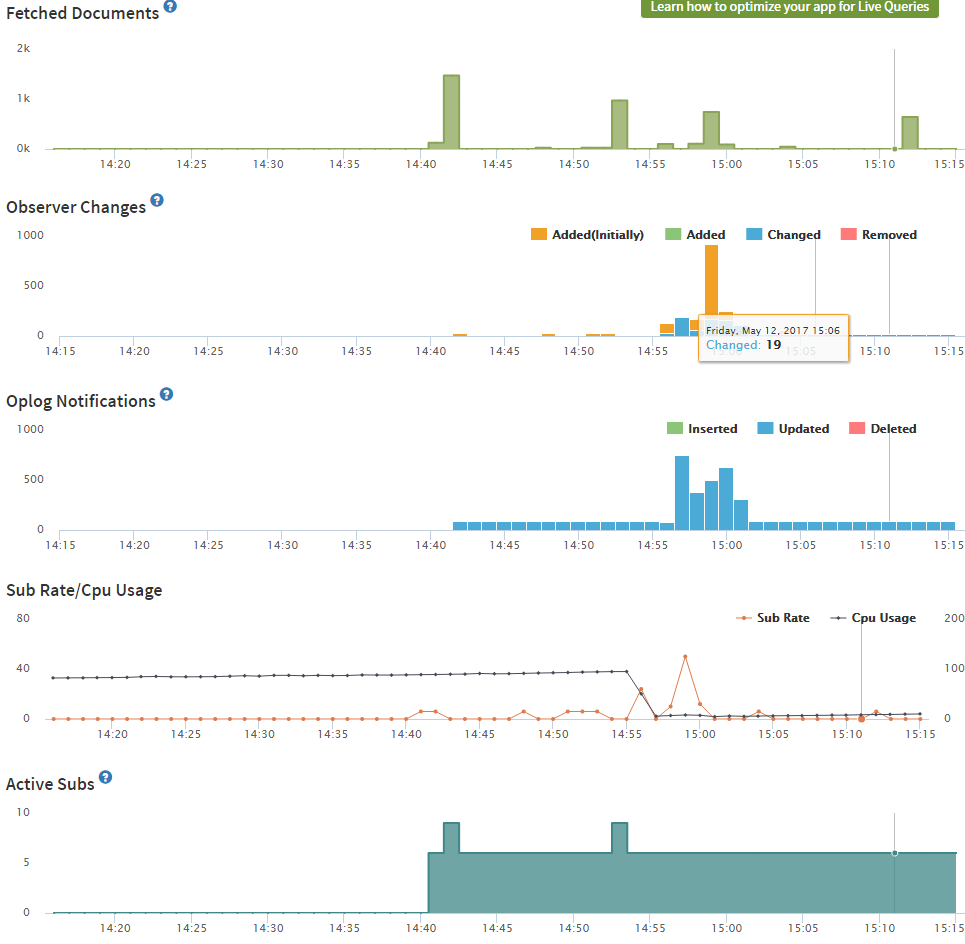
The problem with doing this is, it only runs once. On page load it works great! But as a player moves the subscription is not reactive. A player must refresh the window to restart this subscription.
I have made a hack to do a Meteor.subscribe on an interval of 10 seconds, but… I think this is blowing up my server.
How can I optimize this process?
Edit: I do not have any indexed fields. Should I index X, Y and last_activity?
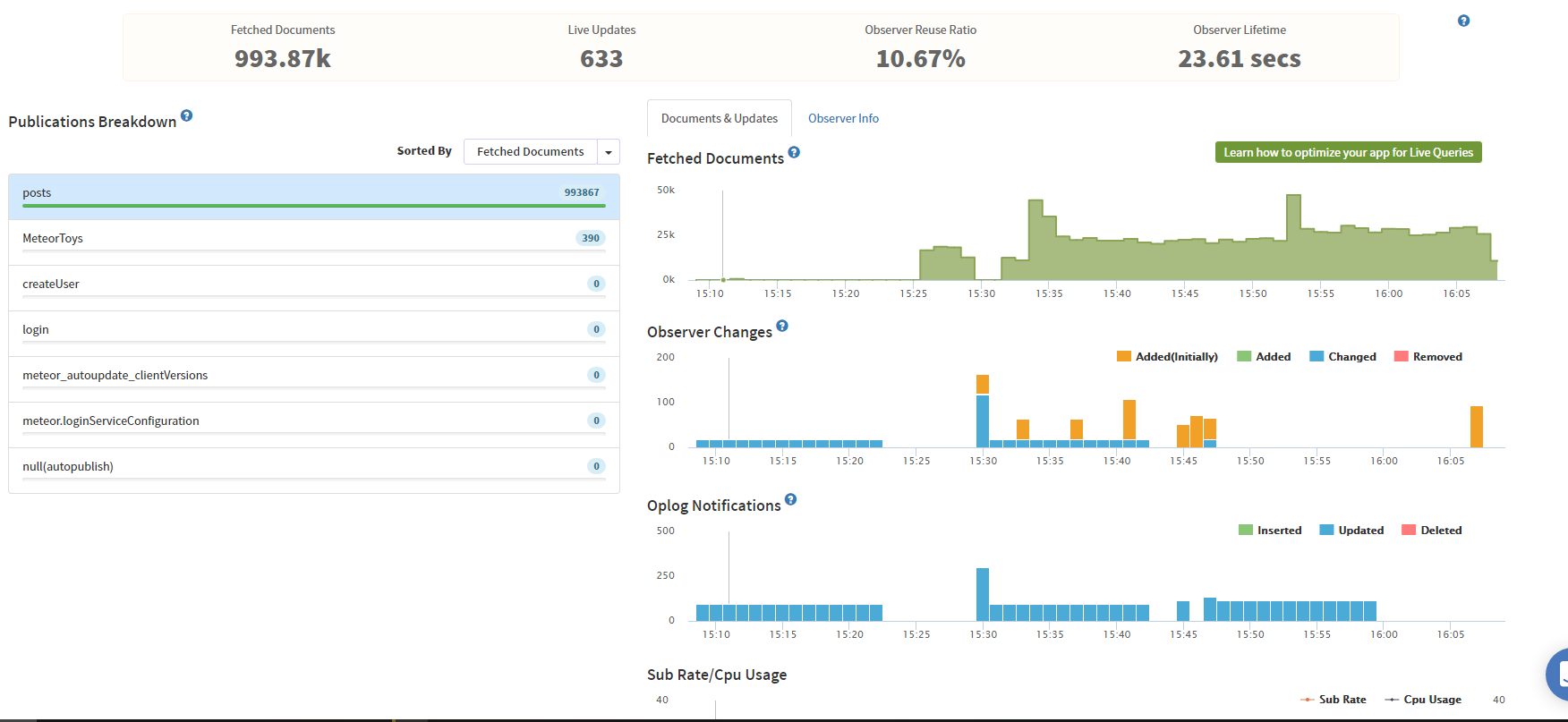
SOLUTION
What a length subject. Here is the tldr;
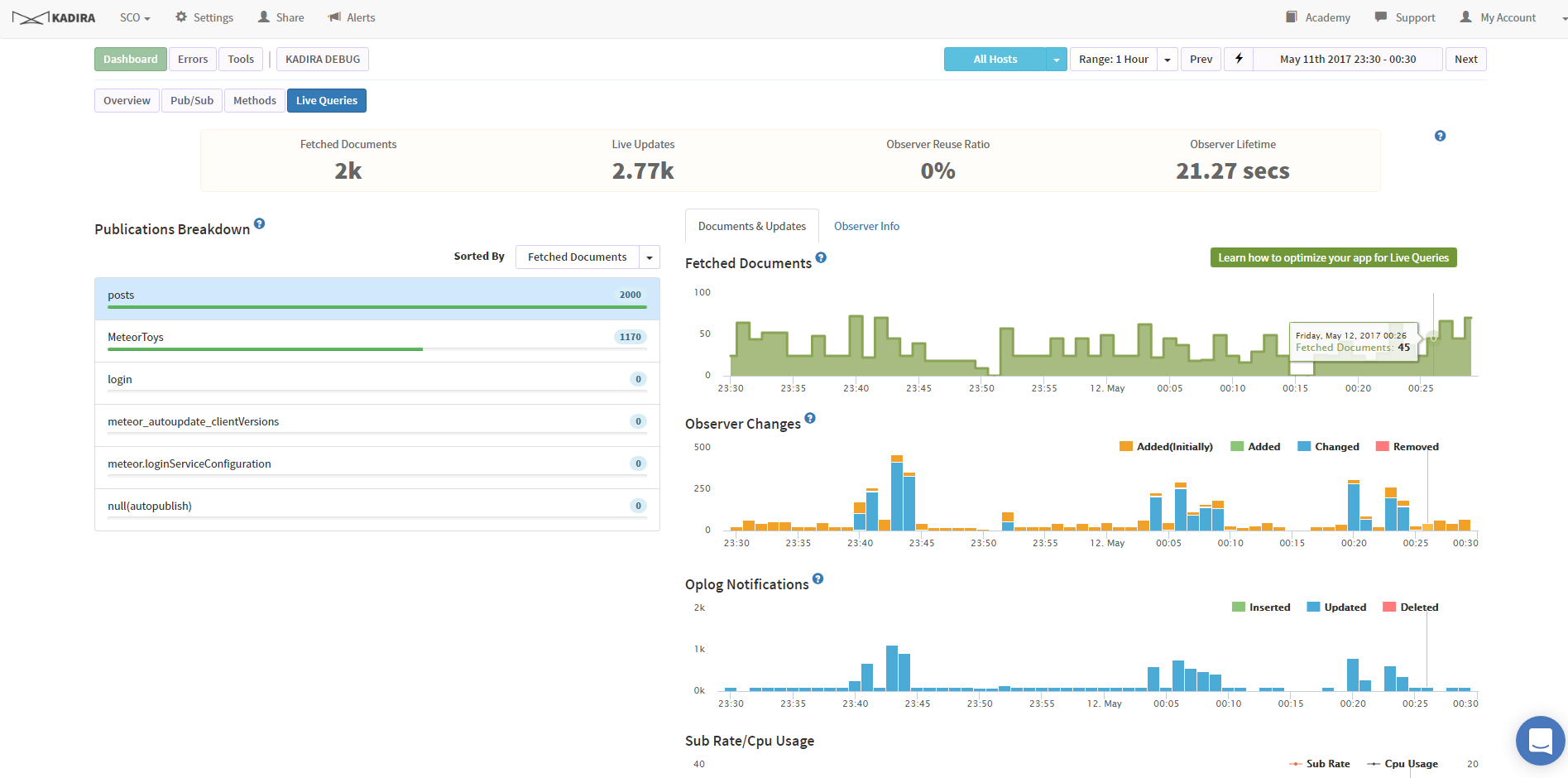
Meteor hosting using MongoDB is an extensive and difficult to learn platform. So nice people like mLab, AtlasDB, etc put together a service for you. In MOST circumstances, this is fine. But in mine, where I’m building an MMO, I need some CPU power behind it.
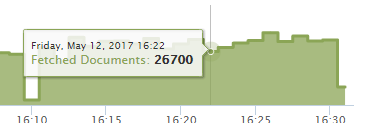
Database Optimization #1
Index your data
Database Optimization #2
Configure your Mongo Database for OpLog, and optimize your live queries.
That’s really all there is to it. Good luck and see you on www.StarCommanderOnline.com - the Meteor MMO.