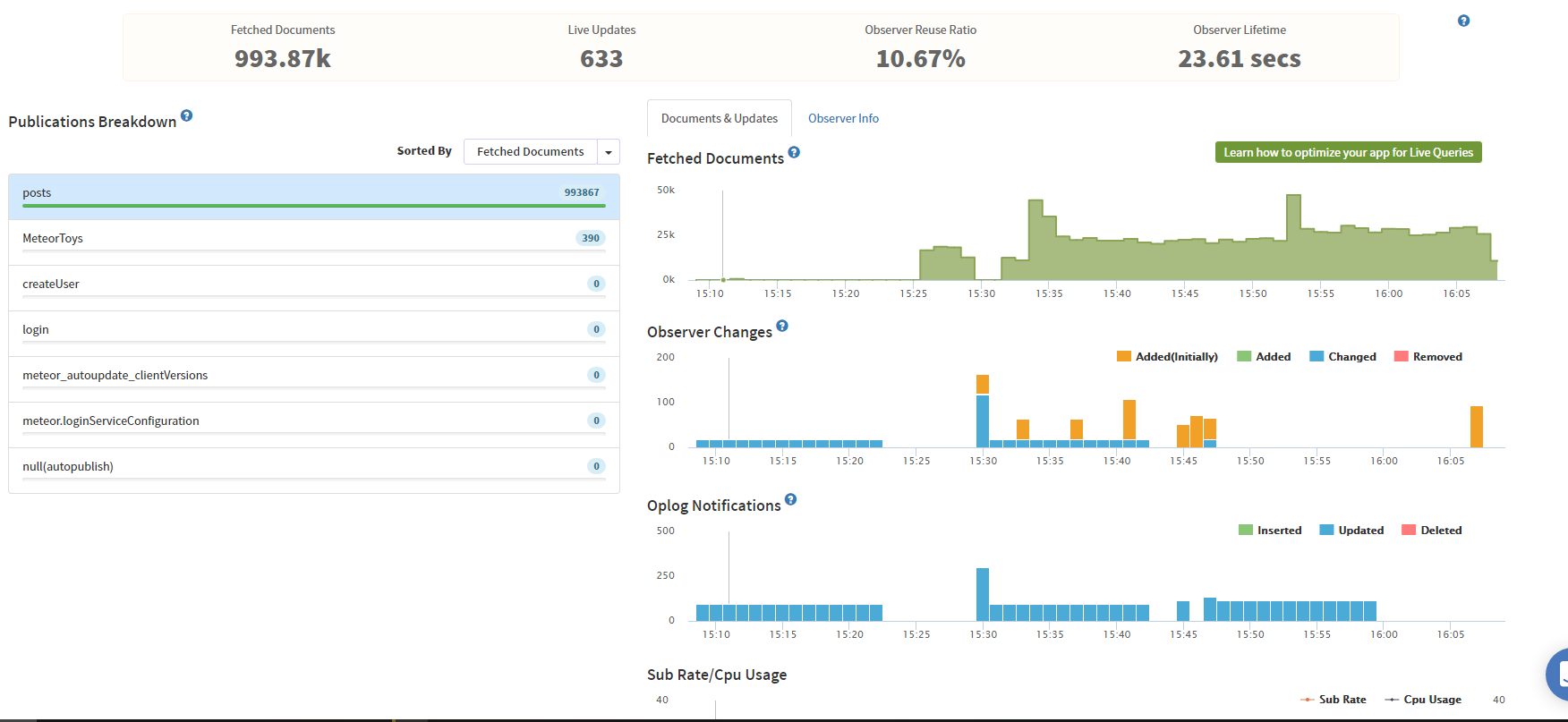
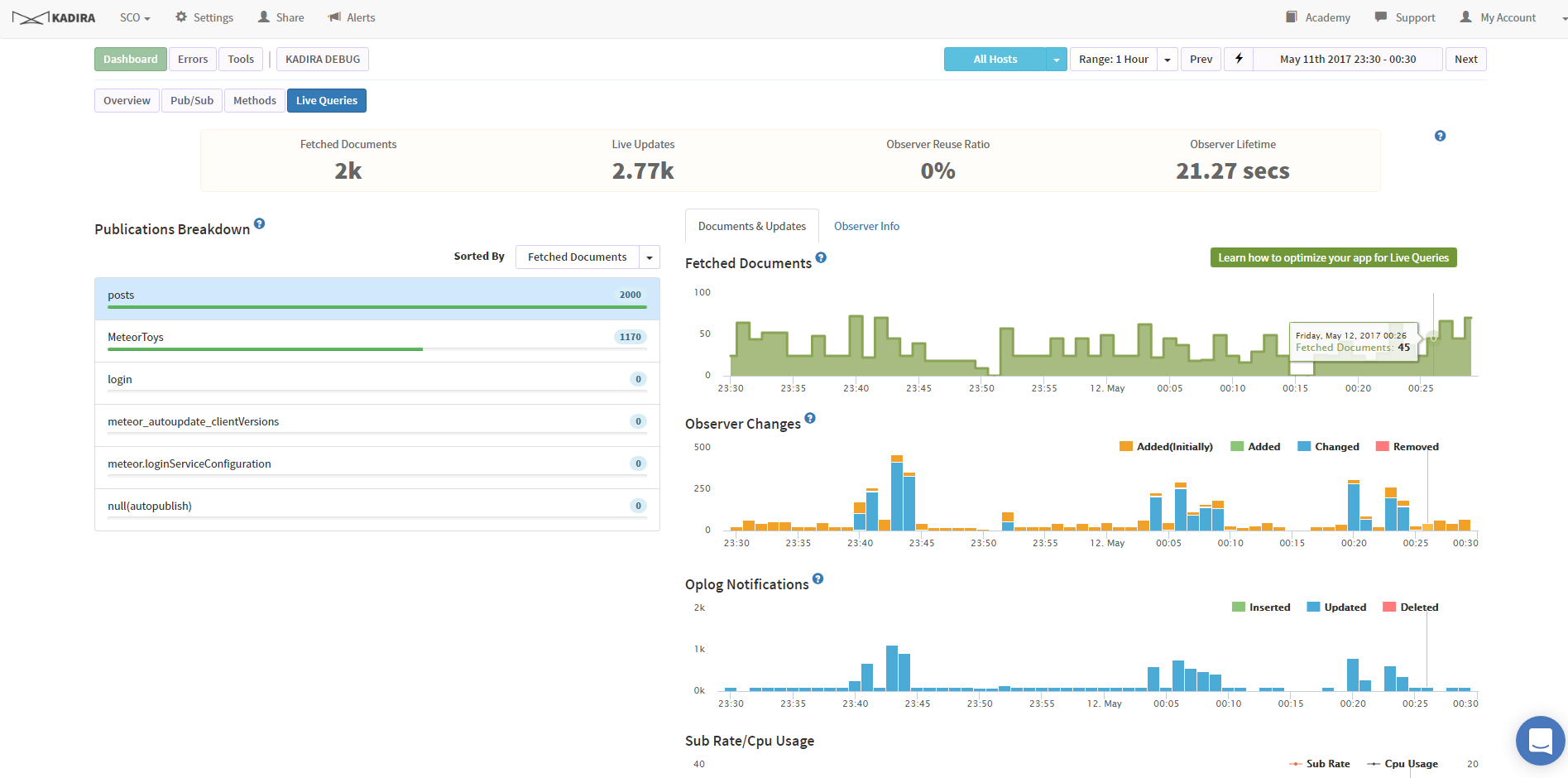
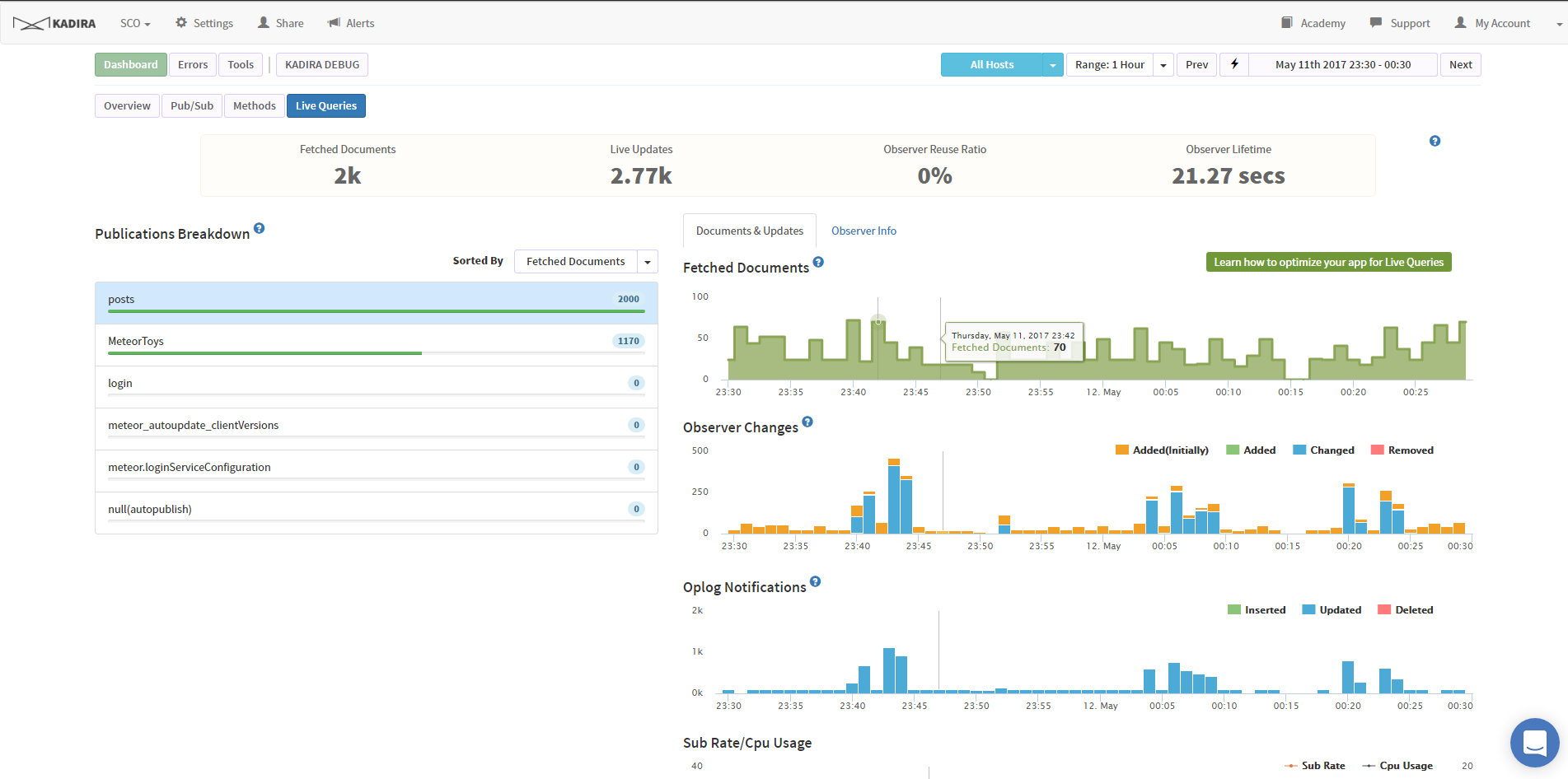
So for example, in my original post, I was pulling data back from NOW until 3 days ago. (search active players).
The result would be every CPU cycle, Meteor was running a new query, and blowing the CPU out. This scaled exponentially with more players. Six players blew the CPU up.
So, the solution for example, is find the start time of 3 days ago, which would be constant, using a function like this:
var date = new Date();
var yesterday = date - 1000 * 60 * 60 * 24 * 3;
yesterday = new Date(yesterday);
yesterday.setHours(0,0,0,0);
var time_timeout = yesterday.getTime();
console.log(time_timeout);
The result of which is currently: 1494302400000, three days ago at 12:00:00
Now on the next CPU cycle, Meteor has a constant to search with, and can simply re-use this query. Meteor gets and publishes the differences.
The tricky part is X and Y. If a player always moves… X and Y always change. So I wonder how to get around that.
Now I’m able to look at the data and see what other problems I have. Players in this case of my app can mine asteroids. This is a constant changing number and looks like it’s clogging the pipes too. I think this is the answer though.
This is my gripe about learning Meteor, this very simple lesson is hard to understand for new comers. This should be made way more obvious and not take actual research to understand
I hope this post is useful to the future of searchers… I’ll do one more post when it’s fully optimized.
Well looks like I’ve reached the end of the tunnel.
Meteor OpLog is the term you’ll want to google. It’s a beast. It’s what gives Meteor speed on production systems. And it’s SUPER hard to enable on your own custom deploy.
Yeah I think I’ll have no choice. I’m testing how to replicate servers at the moment, frigging nuts man. But hey, it’s the future; welcome to nuts? lol.
Oh, you don’t have Oplog enabled? You HAVE to have it, otherwise Meteor will totally trash your database. I just host Meteor on our office server (regular old computer). Set it up myself with Mongo and Nginx
The Meteor dev bundle actually has Mongo with Oplog built in btw.
Correct, I didn’t have OpLog running. Never heard of it. Haven’t seen any guides about it. Friggin crazy, but looks like it may solve the problem. I really need to import my data, but it’s giving me a friggin nightmare to import it.
Transferring data is super simple if you get Studio3T. You can just right click and copy-paste collections or even entire databases, with options to either replace or merge And if you don’t have direct access to Mongo it can tunnel through SSH.
Thank you, I’ll try it out. I’m very excited about the results at the moment. Not excited about the price though. But I think I can get the replication set working myself.
Btw, I think you could install Redis Oplog on Galaxy, instead of using Mongo’s Oplog. Would give you better performance too being on the same server as Meteor.
Also I googled “mlab oplog” and it says they have it: http://docs.mlab.com/oplog/
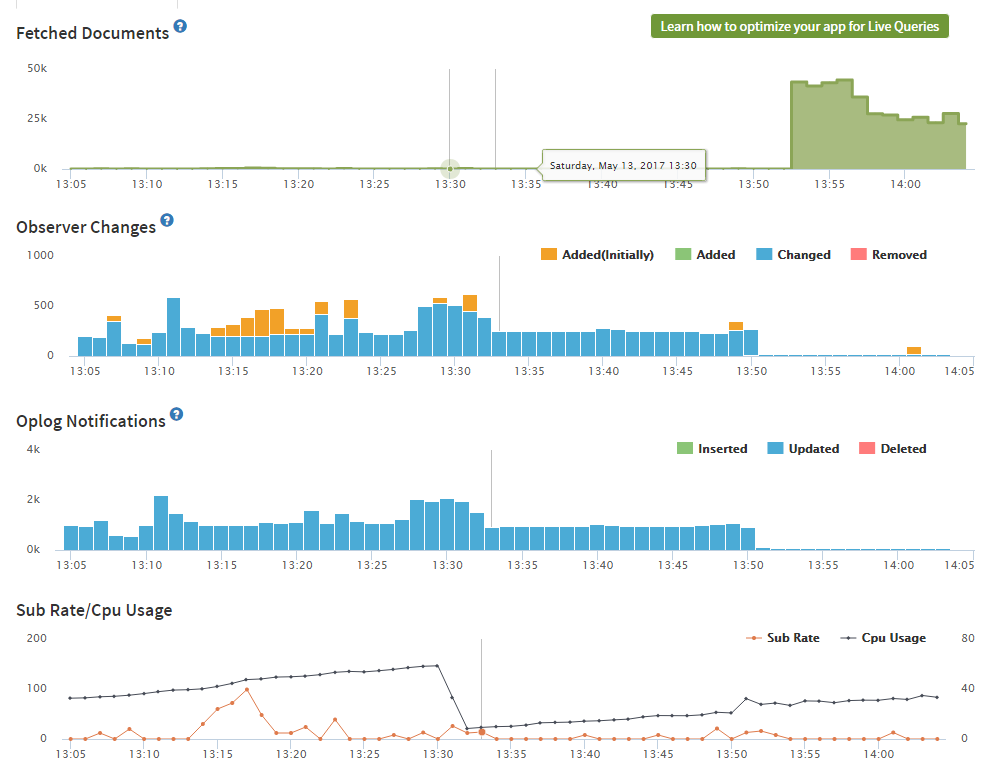
So still not happy, even with OpLog. Definite performance gains. But also, I wasn’t indexing ANY data. I have now properly indexed data.
My total db is 40,000 documents. Which makes sense earlier, why 40,000 documents were being created. If I have 2 users, that’s now 80,000 documents returned.
With indexing, back on my old non OpLog server, you can see the performance effects of indexing.
However, if we examine Kadira, you can see when I make the switch.
Answering the OP again (from an architectural perspective)…
I am not sure about Mongo but, generally, having an index doesn’t fix range queries (simply because ANY record could satisfy the query).
A lot of games of this nature usually have the concept of a “zone”. You would index “zone” and the user can only be in one “zone” so optimisation restricts the query set before it worries about the range query.
Once you have a “zone” you could use an idea similar to Google Maps (or Minecraft) and deliver the data for the “zone” only when the players movements require it. You can then use a client-side collection (that gets the progressive updates) and query that on the client side reactively.
Also, ensure that your data sets are “sparse” and not recording an “empty” cell if there is nothing in it (as Excel does when it stores data).
In any case, if I were to code a (potentially) MMO game in Meteor I would approach it that way.
In summary:
Use Zones to segment the data into chunks (index on Zone and anything else that can limit the segment)
Sparse data sets to reduce what is meaningful
Progressively load new Zones into a client-side collection and query that
You can also use this concept on the server (with observers) to generate new zones as players start moving in certain directions.
If done right, this can provide a linear response time (or even close to static) versus an exponential one when the usage grows.
[UPDATE: Oh, and you could consider using a background job (vsivsi job collection is cool as you could even run a separate server to do the generation if required) to generate the Zones - one per job pass if there are pending Zones to generate.]