Not sure I understand your question, it depends on the environment. If you are using Galaxy, the sticky sessions are taken care of with the cookie they give to each client, to associate the user with a particular instance. If you are using Google Cloud, you can use the same thing with their load balancer, a cookie/sticky session per client, and also give it a max time if needed. Also, using Google Container Engine (GCE) (Galaxy is also using containers) there is no need to manage multiple processes.
In GCE, You setup a compute instance ( a normal VM, say 2x cpu 16gb mem), Then you create pod instances. You can customize the min/max resources each pod can have. 1 instance of meteor can run on a container in a pod.
You can over-scale the pods, say 6 pods per instance.
1 x Compute Instance - 2x cpu, 7.5gb mem | 6 Pods
1 x Compute Instance - 2x cpu, 7.5gb mem | 6 Pods
1 x Compute Instance - 2x cpu, 7.5gb mem | 6 Pods
= 18 Pods or instances of Meteor running
GCE Instance Cost: $145.64 = $8.09/month per Meteor instance.
This is ($600-700+/month on galaxy) which is how this is calulated:
From AWS
1 ECU is the equivalent CPU capacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon processor
In Galaxy a Micro Pro instance is 0.5 ECU & 512MB and costs $40/month.
The above Google Cloud config gives you ~28 ECU (2.4ghz processors (2.4 ECU) x 2 per instance), and 22gb of Memory.
18 instances of meteor could use up to 1.5 ECU in that configuration. Even if you scaled down to 1.0 ECU per Meteor instance, they would get 2x the resources of the Micro pro instance on Galaxy. So you can see if you scaled down the instance sizes dramatically to match the resources in Galaxy, it would be even cheaper
Google’s Load balancer allows you to configure a max number of connections before failing over, or keep the cpu under a certain threshold etc. in addition to what nginix could offer as well.
You can also run nginx within this configure in addition to the Google Load Balancer for more advanced configuration. Add 1-2 pods of nginx per instance easily.
You probably don’t even need this number of instances running. But having this many pods helps with the exponential contention issue. If you run less pods and make them more powerful, they will just go under-utilized or end up being locked in over-utilization during spikes.
I wrote about this here for Next.js, but it can be thought of the same for Meteor, or any Node.js app.

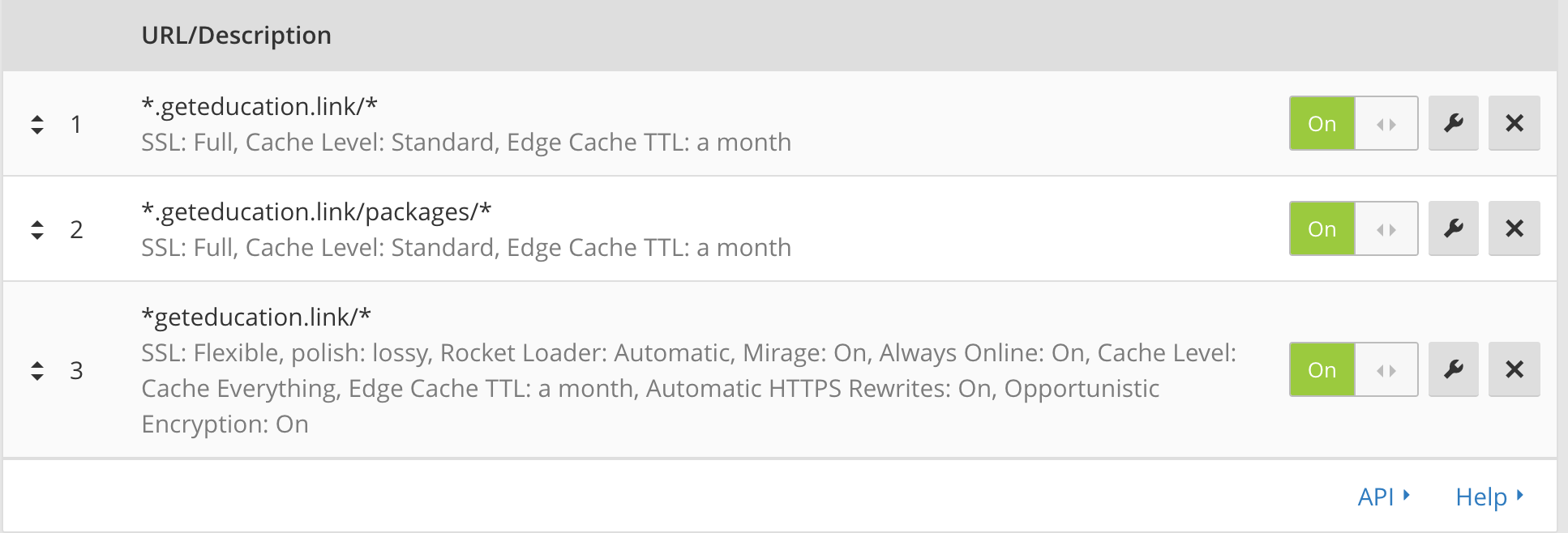
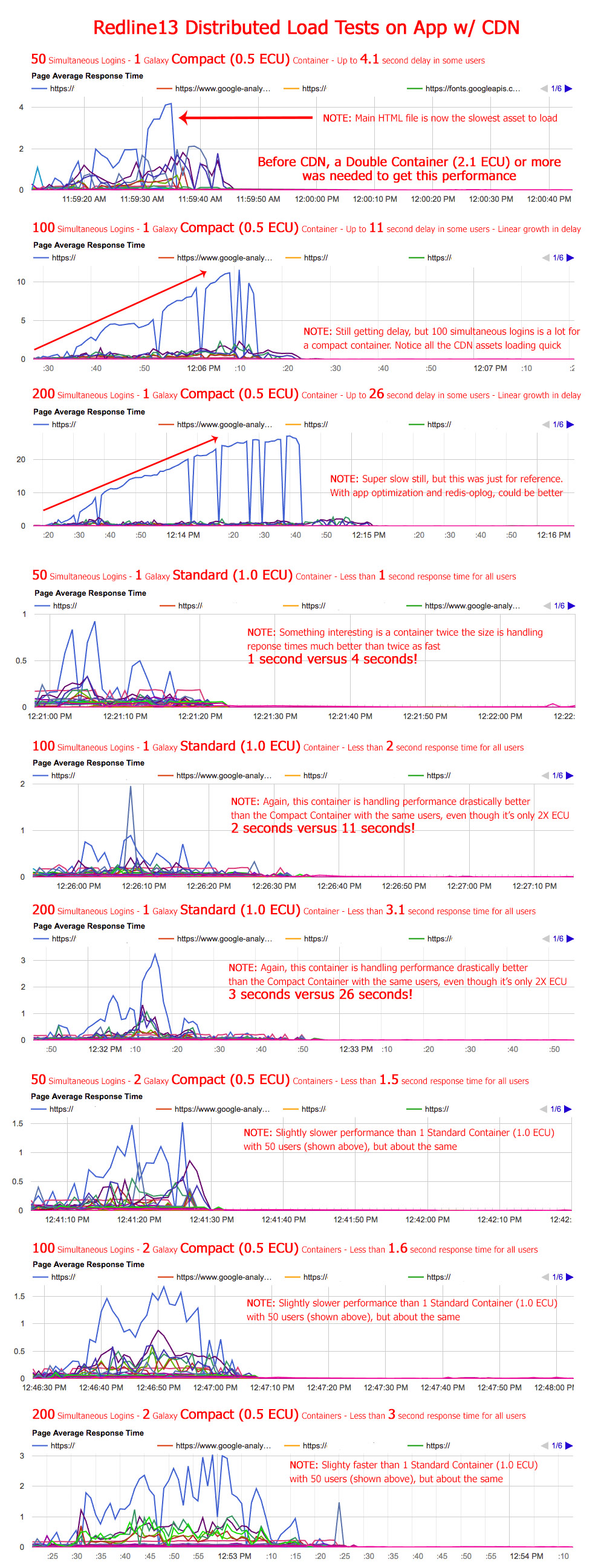
 This explains a lot.
This explains a lot.