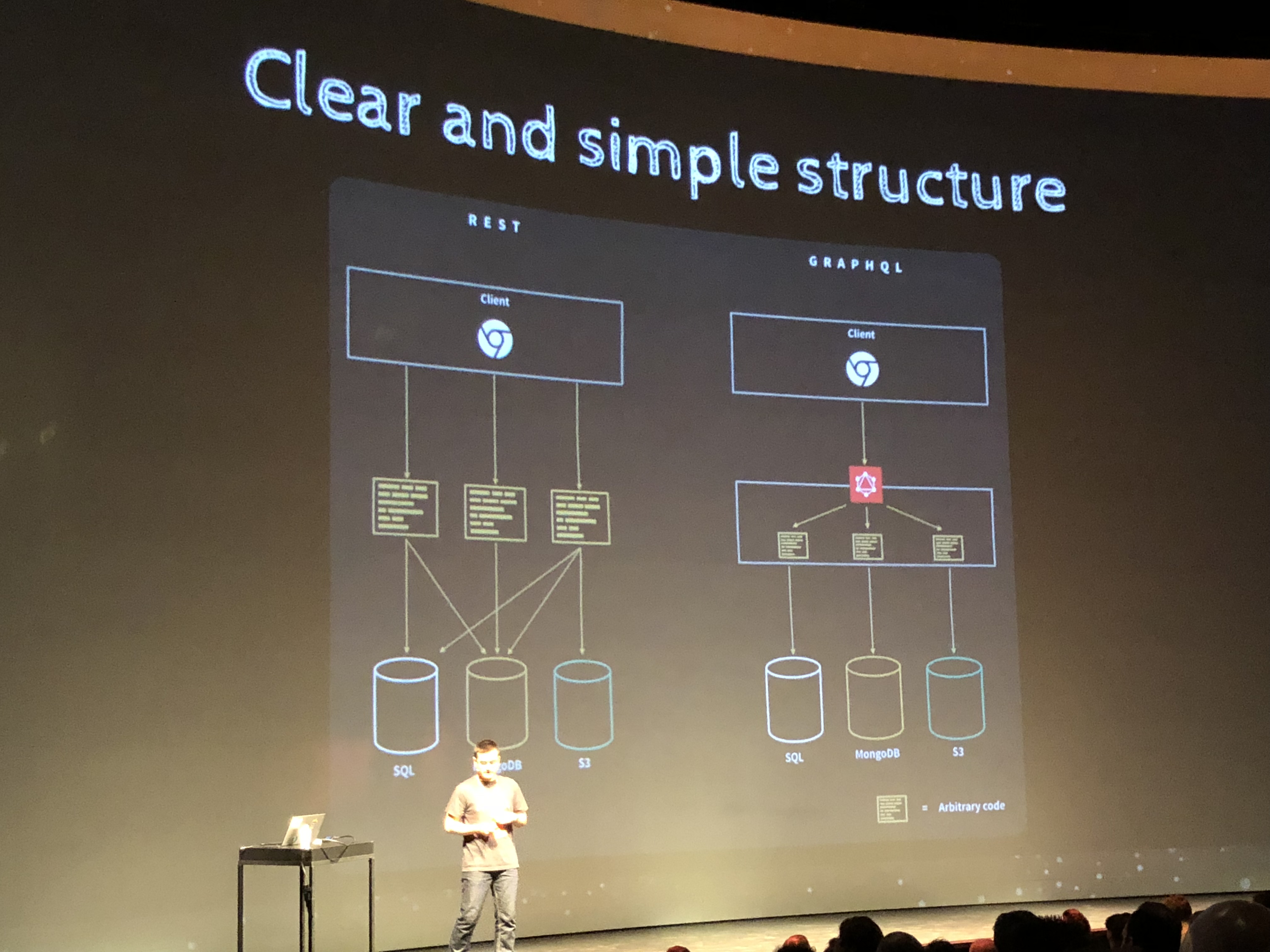
What’s so cool about GraphQL, lets say compared to Mongo-Queries or SQL.
I don’t get it.
I touched GraphQL Queries only briefly, but the examples i saw just had, let’s say some
arg id equal some string.
I just see the limitation of fields or joins (“Graphs”) are represented nicely this way.
But how can I implement the cool stuff in GraphQL I can do with SQL with ease
(where clause, sort, count, grouping…)
The main theme of GraphQL, & the most important thing in this domain is that it makes things very good for a huge App like Facebook, Twitter, Gmail etc.; which have a lot of versions of Clients in the market. Coz there are a Zillion Android/iOS devices say, with different version of OS. & different versions of Apps, Clients.
If you don’t have a huge app, I think others can guide you better with what you should know, & what is important for you to know.
The biggest benefit of GraphQL is that you can virtually type the customized queries you want, when you want, without worrying about the Backend APIs, REST Endpoints, etc. E.g., to have a certain kind to Query interface via HTTP, it has to be built first on the Backend.
GraphQL makes this requirement not necesary. You can type any query & don’t need a backend REST API for it setup in advance. In fact you don’t need it all together.
Work a little with GraphQL Tutorials, and you will appreciate it more.
Some of us are not only pulling data from MongoDB. Sometimes we need to pull data from MongoDB and SQL, or from multiple REST APIs. GraphQL allows you could synthesize data from disparate sources in a single query.
If you need to get data from MongoDB, Stripe, and Quickbooks API, you’d have to do one query in Mongodb and two API calls, and you’d probably get a lot more data from those REST API endpoints then you actually need. With GraphQL you can get just the data you need, from multiple sources, in a single call. What’s not to love? There are plenty of GraphQL talks on YouTube if you want to know more.
Here’s a great list of benefits of using Apollo to access GraphQL. It’s from the New York Times and talks about why they use Apollo:
A more vibrant ecosystem: It’s important for the Times to bet on tools that are part of an active and engaged community.
Better server-side rendering/isomorphic support : This includes fine-grained control over where and when queries are fired. We can delay some queries until elements are scrolled into view, and we can isolate others to fire only on certain device types or viewports.
Preloading/prefetching: With Apollo, we can selectively prefetch certain queries for a snappier reader experience.
Code-splitting at the component level: This was difficult to do before, because of the static routing requirement with Relay.
Apollo Link architecture: Middleware for the GraphQL fetching layer using Observables.
Modeling local app state as part of the schema: In some cases, this may obviate the need for Redux.
Schema stitching: This allows us to seamlessly connect to multiple GraphQL backends and treat them as if they were one.
Persisted queries: We can now send a query ID instead of the full the query over the wire.
Enhanced debuggability and local developer experience: We now have tools to monitor Apollo inside Chrome DevTools.
Having said that, merely using graphql may not save one from sql injections either. The only way to be sure is to encode/sanitize each user input used in queries, according to the query engine (be it SQL, Mongo or some other DSL)
Without knowing all the requirements I can’t speak with authority, but if there is a strong case for ah-hoc SQL queries, perhaps you can write out data to a data warehouse for reporting?
Personally, we prefer to build visualizations (charts, metrics) to deliver the data our user’s needs and to export data as CSV for analysis in Excel, Tableau or dashboard service like Geckoboard when more they need more flexibility. I’ve been building business apps for 25 years and I’ve never just given users direct SQL access. It’s kind of an anti-pattern in my opinion.