We made lots of changes to our codebase in recent months, most of them in regards to performance. We removed many subscriptions, (finally!) implemented Oplog tailing, moved from DigitalOcean to AWS and much more.
We still have a setup with (at the moment) 4 identical meteor app docker containers (behind a traefik load balancer) and 2 identical plain nodejs docker containers running our workers (on a separate AWS server!) doing the heavy lifting.
Our database is not hosted on MongoDB Atlas on M30 instances with the default 3 replica nodes.
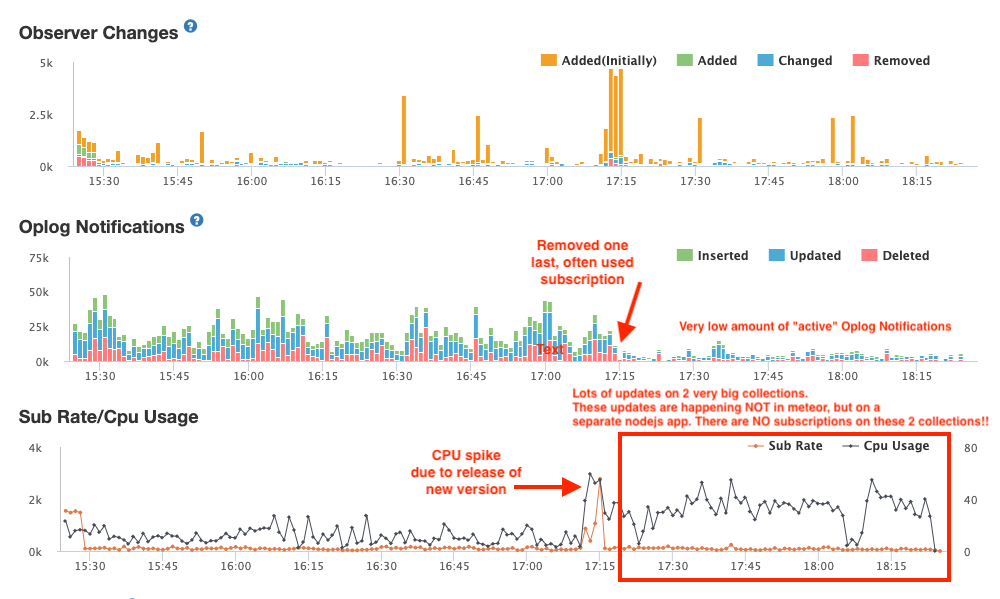
We have this use case, where we have to import lots of data into our database. This is done on the workers and most of these updates touch 2 or 3 mongo collections. We are talking spikes of ~5k updates on both collections in a matter of seconds. These loads sometimes are “sustained” (with breaks in between of a couple of seconds) for minutes or sometimes even hours!
During these imports, we see significant CPU spikes on all 4 meteor instances.
But, here is the catch: We do NOT have any subscriptions on these collections anymore!
My questions now are:
Is this expected behaviour?
Is there anything we can do about this to reduce the load on the meteor instances during these updates?
you say your DB is NOT on Atlast but you mention specs. I thing that is a typo? If yes, can you see in Atlas what was the number of connections at the time of these updates. I am thinking Meteor could have been left without available connections and that could be a cause for processor spikes that you see.
Also, from where you write those large numbers of records, you may check the write concerns and reduce friction between servers in the replica set if that is not particularly important for you.
… something like … don’t wait for acknowledgment.
Another thing is to throttle the writing (batching). I’ll leave here an example:
const runBatch = () => {
for (let i = 0; i < 5000; i++) {
(j => {
setTimeout(() => {
// Write here in smaller batches.
}, j * 1000) // 1 seconds per call
})(i)
}
}
Sorry for my late reply!
Yes this was indeed a typo - we ARE on mongoDb Atlas on 3x M30 instances on AWS.
We already have an adapted mongodb connection string with w=majority&readPreference=secondaryPreferred - so we already optimized everything “there is”.
Also, the big writes already happen in UnorderedBulkOprations, so I don’t think there is not much we can still do there?! Also, again: these bulk operations are done by a worker nodejs app which is running an a completely separate AWS server.
Last but not least: we do restrict our connection pools to "maxPoolSize": 60 PER Meteor instance. So yeah … could be an issue but really not sure if this is the case. Since the spikes I showed you were RIGHT AFTER a go-live of a new version, all Meteor instances just restarted minutes before that, so it is highly unlikely that we already reached a limit of connections at that point.
Maybe someone from the Meteor team (e.g. @hschmaiske) can add something to this?! Maybe this is something that can be improved in Meteor 3.0, that many OPLOG changes do not cause CPU spikes like this, even if there are no active subscriptions on this very mongo collection!
The problem with the oplog tailing is every meteor instance does oplog tailing. Which means the more instances you added, the more CPU database uses to support oplog tailing. I saw you have 4 meteor instances.
You may try Redis Oplog. It should solve your problem.
Okay understood. I wasn’t aware of the benefits Redis Oplog might have here, as I thought it would only help when it comes to actually active subscriptions.
To put it into other words: Is the OVERHEAD of the Oplog itself without active subs really that big?
I don’t have the answer but I had this problem before. I deployed a Meteor app on Google Cloud and use its load balancing and auto scaling feature. Sometime the number of servers increased to 10. When I use builtin oplog, everything goes crazy.
interesting! did you work a lot with (active) subscriptions or did you experience this “auto scaling craziness” also without any subscriptions, only caused by the “default oplog overhead”?
I tried to use less pub/sub as possible. I don’t use pub/sub with a list of document. I only use pub/sub with a single document then use method to load a list of documents.
I don’t know exactly what causes the problem, but I know is using redis oplog helps.
I can answer this for you. So, the default Oplog implementation works by every Meteor application instance actively listening to all Oplog messages in the database you connect to. So the more operations you do, the heavier the load will be on all your applications, because ALL changes are being fetched by meteor and processed.
Meteor has to process all these messages from the oplog to determine whether or not any of them are relevant to the current subscriptions. So it takes one oplog element, looks through the current subscription handlers and matches against the pattern that matches. Even if there are no subs, meteor will get all those messages and process them. That’s why it is slow at scale.
Redis-oplog on the other hand, does not rely on the oplog from mongo. When an update is made by a meteor app to a collection, the change made is sent to a connected redis instance in a special format that contain the relevant updated fields, and to mongo at the same time. Redis will then distribute the update message only to the meteor apps that have subscribed to that collection’s or document’s updates. This way, doing an update will not tax all the other meteor applications.
So, when a client subscribes to a user doc, for example user_1, then meteor will make a subscription handler for that document, and in turn subscribe to the user_1 update messages from redis. Updates to user_1 will be sent from one app, to redis, to the app server with the sub, and then up to the user.
Hope this clarifies things. Now, there are come caveats. You need to set up redis for one. AWS’s ElastiCache redis works great for this. There is also some memory and processing overhead to redis-oplog that is still out there, so it is not optimal to what it could be either, but better than only oplog.
oplog sucks it did the same to me. I run everything on my own server 8 core it’s cost very little, the best way to use Mongo is give it lots of ram that’s how they designed it. By default mongo will use as much memory as possible so that’s why you cannot be profitable and use cloud based services, you need to have your own metal.
I have to raise this issue again, because this really gets out of hand for us at Orderlion unfortunately.
I had a look into meteor’s mongo oplog observe driver, but, to be honest, the code is quite complicated to me and I don’t fully understand what is going on there!
My question is this: If we would have an env var or maybe a Meteor setting, which kind of ignores some collections in the oplog, would this reduce the CPU load significantly?
In other words: If I have a collection, let’s call it Products, which is every often hit by very big bulk updates, but I don’t care about any reactivity for this collection, if there were a filter to ignore any oplog messages for this collection in meteor, would this reduce the CPU load significantly or not?
I understand that Meteor still then has to look at all oplog messages, but I am trying to figure out if this very simple collection level filtering would already reduce the load.
Hello everyone!
I basically just tested this what I outlined in my earlier post.
The results are great!!
When updating 600k documents in a collection which I actually do NOT want to “watch” via the Oplog, the CPU impact on my meteor app went down basically 100x with my change.
I will cross-check this one more time tomorrow and then create a proper PR and link it here!