(Apologies if this is scatter-brained writing, been fighting this for days now and am at my wits end trying to figure out what’s going on).
As of approximately Friday, our performance has significantly degraded on our application, and it seems to be resulting from MongoDB Atlas, but haven’t been able to figure out why. Any advice or assistance would be appreciated.
The strange part is that we had not many any significant changes to our software during this time. Especially in relation to database access, we’ve only done some visual updates/etc in the last few weeks.
Long story short, our software is made for in-house usage at our business, with usually no more than 10 users connected at once, so scaling shouldn’t be a huge problem. We’re already setup with Redis-oplog, and the Redis server does not seem stressed at all.
Our application has been slipping between unusable, and barely usable. We’ve had to use an “emergency mode” to only do the most important server functions in order to even use the app, if we turn on “regular” usage (using routines for stock updates/etc) it’ll crash within minutes.
Here is a screenshot from our MongoDB Atlas metrics:
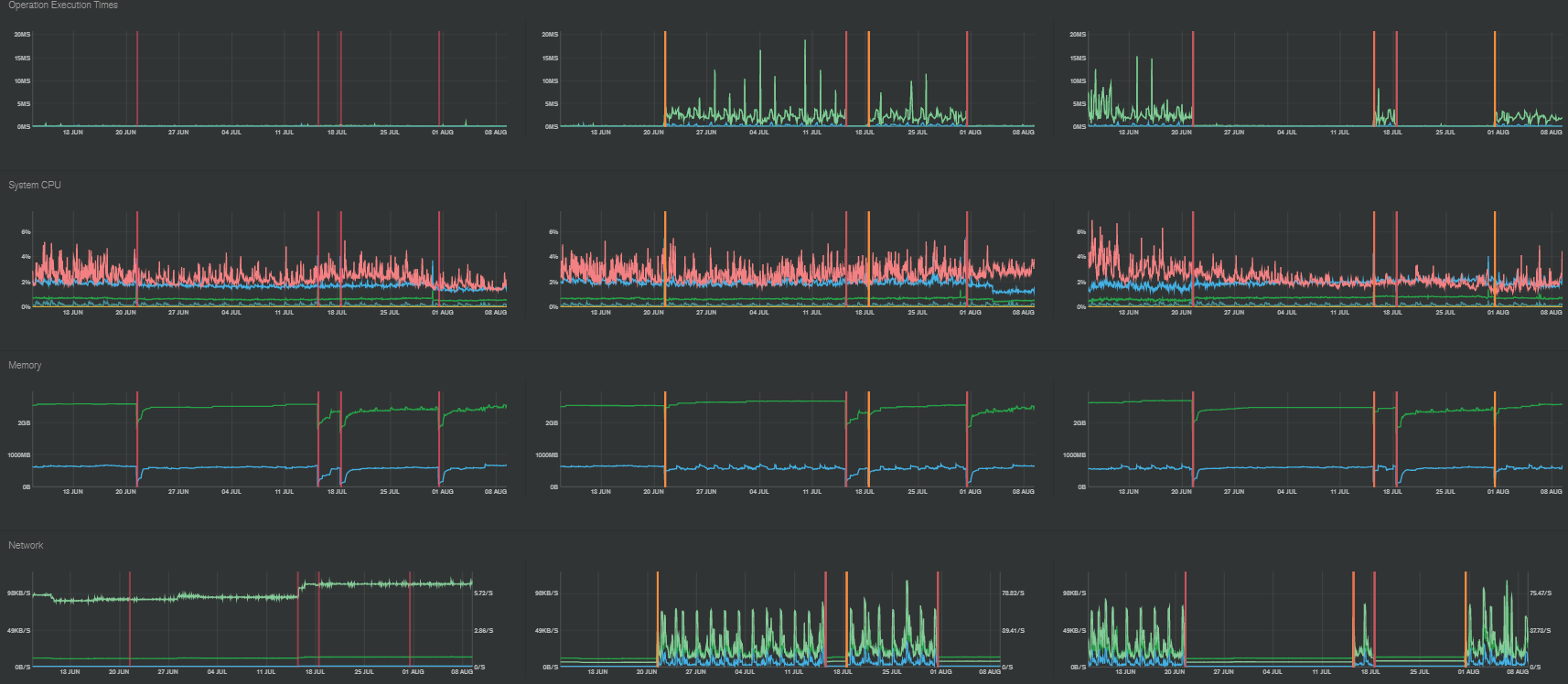
As you could see, it doesn’t appear that there’s any significant changes, nor does it look like the problem that began on Friday is even visible on the graphs?
Here is an image of our Galaxy APM, and you can see the DB clearly beginning to lag behind around 8AM (when we begin using the software).

Taking this in to consideration, it seems a problem that is certainly worse when others are using the application. But all of our subscriptions, data usage, etc? It hasn’t changed at all! I’m not sure where to even begin on solving this problem, as based on our past experience, it should still be working the same. Our data usage hasn’t increase, we haven’t had an increase of orders, nothing has changed?
I have no idea what could be causing stress from connected clients. It doesn’t look like anything abnormal in our APM (aside from extremely high response time). It’s difficult to debug as the highest response time methods seem to be ones that are typically extremely fast - it’s as if when this problem occurs everything has a huge response time, and it doesn’t seem to be linked to any specific method or function that I could find,
MongoDB Atlas support has been friendly but has not been useful in resolving the problem yet. The first thing they mentioned was CPU Steal - which I’m not sure why it’s using CPU Steal anyway if we’re on a M10 plan and using such low CPU% - and as you can see in the logs I posted the pink line on the graph is CPU steal and that has NOT changed significantly.
Then Atlas Support chose a few specific methods saying that they may not have been indexed - but these were some rare cases where for example, a manager had searched logs to pinpoint a specific log and it didn’t fit under an index. These slow queries only happen a handful of times per hour, and I don’t believe they are the cause of this issue we’re seeing, as again, the indexes have not changed ,database usage has not changed, etc.
The issue here, for both support and ourselves, is nothing seems to be appearing on our MongoDB Atlas graphs. No differences in performance, response time, etc, if we compare when we’re having issues to when we’re not. Resources are mostly free.
But if I check logs, even the optimized queries are all appearing in slow queries during this time. A shot of our “profiler”:
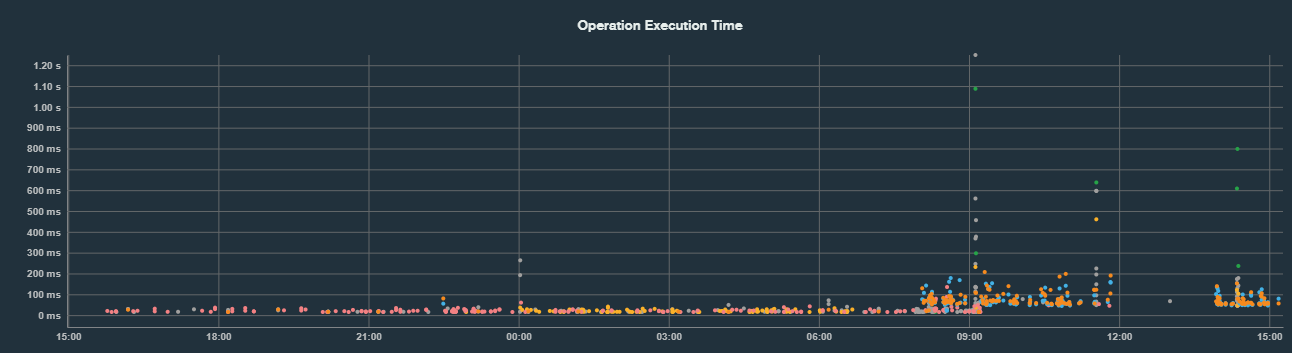
You can see the handful of manual searches there with high responses, that’s fine. But you can see as soon as 8AM hits, every single query begins taking much longer. (And to bring some understanding, at midnight/overnight we have some API routines that run, and that ends prior to 8AM. So some usage overnight is normal. My main point is that you can see all the queries begin taking much longer as of 8AM.)
I had attempted to restart the Atlas database, but when I try following the documentation to do so, the option to restart isn;'t there. I asked support about this, and no response.
Furthermore, while the response time for those methods is high, it’s nothign compared to what we see on our end. Even pages without any data subscribed nor any methods take 30 seconds to appear when only using general login/user access.
And the last 12 hours for the Profiler have slow queries by collection, and the total sum are as follows:
10, 9, 4, 3, 2, 2, 1 second respectively by collection
So according to this, around 30 seconds of response time was logged in the “slow queries” of the profiler. Meanwhile, our Meteor APM shows instances of over 91 SECONDS DB time , on single calls!
None of this is making sense to me. As again, we haven’t made any changes, the graphs of MongoDB Atlas don’t show any changes, nor do they show any major differences (although we could FEEL a huge difference!). Atlas support is pointing at optimizing slow queries, wehn those are rare cases of manual searches and aren’t realistically going to help. APM isn’t showing anything abnormal aside from a huge DB time.
I don’t really know what to do to diagnose this further. No publications/subscriptions stand out as a problem, it doesn’t seem linked to any specific methods. All signs seem to point at the database, but the database doesn’t even show anything that is a problem…?

 ). I wonder if
). I wonder if