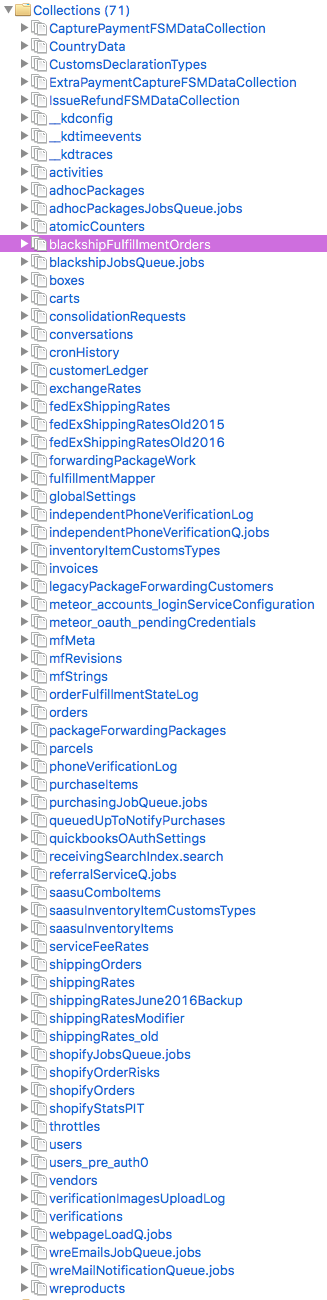
We worked on nearly two dozen prototypes that had 5 to 7 collections. That seems to be a very typical number for Meteor apps, which usually includes user accounts and roles, maybe a statistics or cronjob collection, a master collection, and one or two data dictionaries.
After a lot of experimenting, we’ve managed to do a production refactor, and start pulling in all of our prototypes into a single master application. Nowdays we’re up to 25 or 30 collections, I think. And our design eventually calls for nearly 100 collections.
Challenges…
a) data modeling - To have a multi-collection app, you need clear business processes. Do business workflow analysis, do UML diagrams, figure out process state, cross reference with incoming/outgoing datatypes, create simple-schemas, and try not to reinvent the wheel.
b) pipelining - Collection hooks are your friends. Particularly with inbound/outbound message queues.
c) statistics - You can’t fit all the data from large-collection apps into minimongo. So, to coordinate them all, you need a statistics collection. Start with a singleton pattern and then move to a sorted snapshot pattern; use the most recent available stats record as a bucket to collect collection counts.
d) cron - You’ll need some regular maintenance; whether it’s just collecting statistics or more complex housekeeping.
e) dashboard / views - Ostensibly the problem that GraphQL tries to solve, a great pattern is to store your view state as a record in a collection. You have to identify all of your joins and lookup logic, and move it to to an insert(), update(), before.insert(), or before.update() function.
f) collection topology - As the number of collections grows, you’ll starting experimenting with indexing them, capping, sharding, write concerns, etc. Then you’ll start having decisions about how often capped collections should be flushed; whether users can control that; what your shard indexes should be; etc. etc.
$0.02