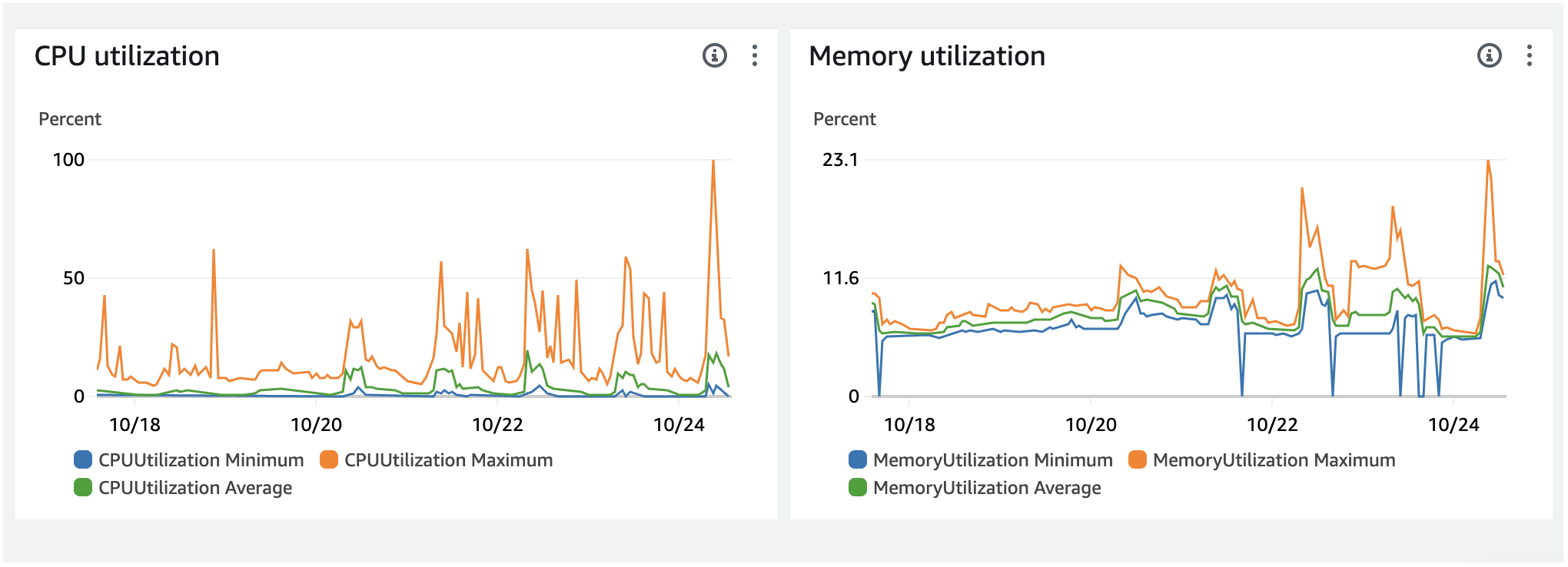
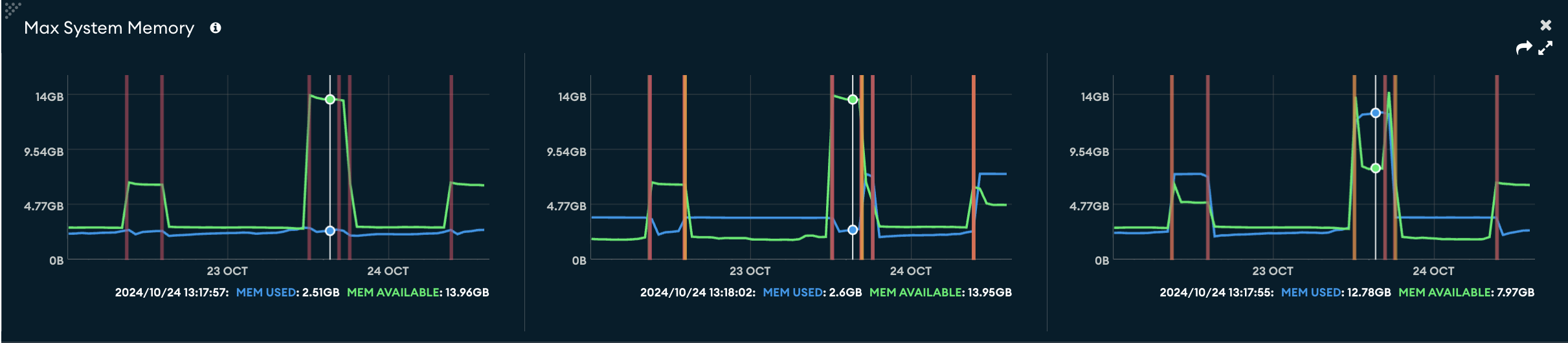
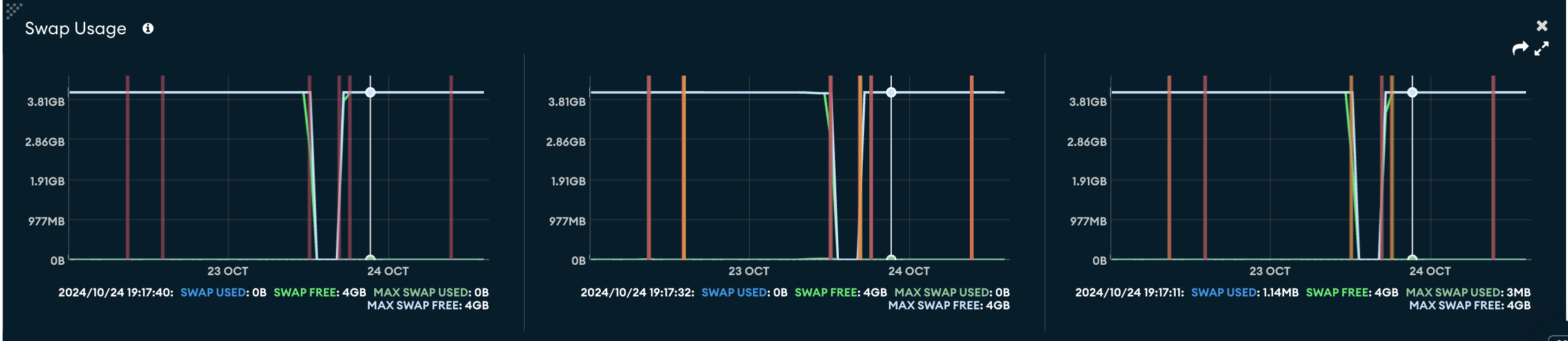
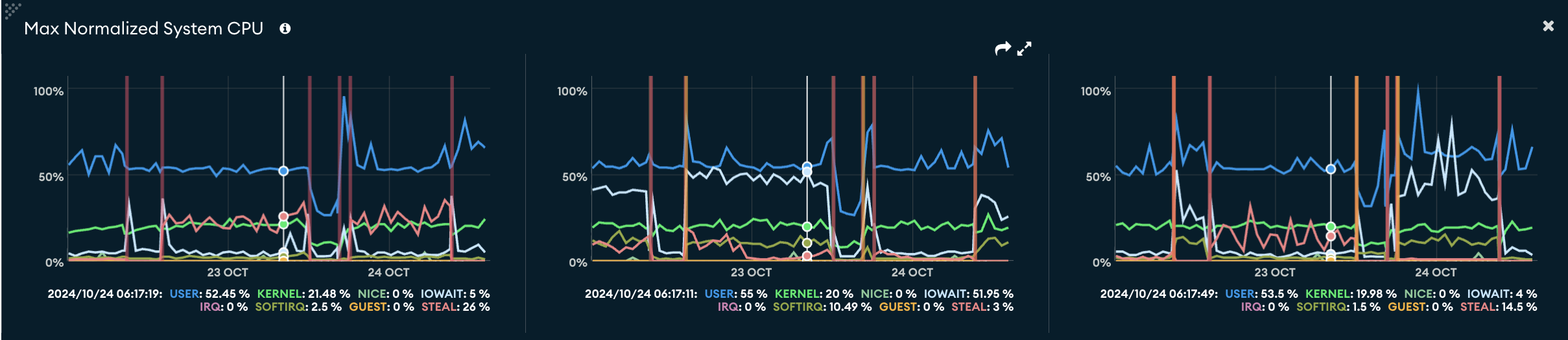
Thanks very much for the detailed comments @leonardoventurini. Glad I am going down a known path but one less traveled, which might be an edge of Meteor … I would fan to flame your crazy side.
I am encouraged that you are brave and open minded, it seems. And I see but dismiss burn-in from the current way it is; you are immersed in how it is now, but your mind sounds of breaking out of the jailed shell of how we experience Meteor today, I believe. I meet you there and apply to be your shoulder devil.
Going to take time to consider what you said at more depth as it pertains to the current way and circle back to discuss further, toward Meteor improvement versus just my implementation. Before thinking from Meteor itself then, I will think from “the situation in the wild” as it is, with or without Meteor … and share direction a bit in trade to your bravery within Meteor today. Based on your comments I can feel where the edge of the issue is now.
I am coming in fresh to Meteor but with a lot of history. Especially after working with the Actor model for many years. As well as writing microservices architectures ( using message queues ) and dealing with ZeroMQ at great depth. I deployed Actors in pretty much every type of inter/trans/action you can imagine.
Eventually it got to be too cookie-cutter, and limited to a certain approach when it no longer fit. I saw distribution of load is actually a clue we are doing design wrong, at the level of fundamentals. I think of how we overload IMAP and SMTP, how SMS / MMS and SIP are still based on Telegraph and PTSN, etc. Anyone looking at 10 DLC in that spirit will noticed we cannot make enough acronyms to cover our shame, and we are running from being pretty much horribly ugly at a design level. That cannot be smoothed out at the edges but speaks to a rotten core. All those foundational systems were improvised, especially TCP/IP, and often commissioned by military, i.e. US DoD kicking off TCP/IP versus Recursive Internetworking for example, which dramatically impacts design, so much so RINA the infrastructure would completely obsolete this conversation right now. A lot of what we are dealing with is TCP/IP itself, and Meteor sits smack dab in the middle of that design warzone.
We use “message queues” today but they are still in the same lineage as smoke signals, which are the first real example of “synchronous telecommunication” before Telegraph, Telephone, etc. We are in that mental space still.
Now our improvised designs are obese and vestigial, and everyone deals with the issue in a silo. Everyone teaches design philosophies which are pretty much pure opinion versus lift and reuse natural structures. Anyway so I left that Actor model mental space, because it is running home from its own vasectomy and calling that performance, even though it is trustworthy and easy to supervise, and did massive-level scaling well. Rather than trivial things it is deployed in life-threatening situations, like energy distribution, covering regional electrical fail-over with no room for error on deadlocks or bottlenecks since thousands of people on the sensitive side might die pretty much right away, even just if a hiccup happened. Bear with me I am heading back to Meteor today now.
Reason to leave Actor behind is because it does not really do "Distributed Applications" which is what we are all working toward with multi-modal systems ( mobile, desktop, browser; multi-instance, multi-tenant, multi-location, etc. ) … it is a hack. A very scholarly, proud, section of duct tape reinforced with chewing gum. And this is the pressure point Meteor is sitting on the red button of, and so… I see it very simply, and would contribute this nudge:
There is more than server and client … there is also agent ( in my terminology, beyond Actor which is still too vague and abstract ) … and from there, I almost want to bet >70% moves out of the server application.
That approach though is an entirely different design pattern, similar to MVC in usefulness, going beyond the transient “full-stack” front/back-end hellscape, but it is easier to think of it as coming backward from the future, rather than remedying the dumpster fire we call CS/IT/AI/*aaS, with a partridge in a pear tree.
In the background of arriving to Meteor I have been coming in with a design style which forces the issue. So if you are at the edge of the rabbit hole… count me a friend and I would love to destroy your sense of orthodoxy  Right now I see
Right now I see Meteor as if we traveled from the Sun to Earth except for the last meter. That last meter is a head change, and getting out of the “smoke signal” era, then backporting to there, rather than being the heirs of quills and horses carrying slips of paper as determining factors in the rise and fall of ecosystemic evolution.
In the meantime I will keep thinking this way and get to a point of sharing code once I have the style above ported to Meteor shortly, which I would not necessarily share publicly out the gate. Thinking about how to broach that since it is right on the vein of the field, and goes back to before the 60s. Mostly I want to unleash it and not sign up to bikeshed, so I hug you for your bravery versus feel a need to speak in school. I would love to meet at the mind on totally annihilating all our core beliefs and expectations on what “excellent performance” means, to leap 1 meter which is all the difference in the world. I can thread-off somewhere else to add fuel to the fire of design bravery if preferred.
Thanks again and I am very glad this thread poked through to the most salient contemplations, in my opinion.